Juanyi Chat:现代化实时的聊天室,无需框架依赖,开箱即用。
大家好,我是倦意,最近我开发了一个即时通讯系统,取名叫JuanyiChat,也可以叫JChat。这是一个基于原 […]
未完待续
false的时候,触发异常java中的异常处理包含:try => catch => finally几个步骤,python中的异常处理则是:try => except => else => finally
except捕获异常
try: i = 1 / 0 print("正常执行")except: print("发生异常了") #发生异常了try内没有异常,else块内代码才会执行,else必须放在所有except的后面
__doc__是 Python 中每个对象都可能具有的属性,用于存储该对象的文档字符串
try: result = 3 / 0except ZeroDivisionError as e: # 打印:异常名 + 异常描述 print(f"1.异常名:{type(e).__name__},异常信息:{e.__doc__}")except (RuntimeError, TypeError, NameError) as e: print(f"2.异常名:{type(e).__name__},异常信息:{e}")except: print("Unexpected error")else: # try内无异常时执行的固定逻辑 print("try内无异常时执行的固定逻辑") print(result)1.异常名:ZeroDivisionError,异常信息:Second argument to a division or modulo operation was zero.如果改为result = 3 / 1,则输出
try内无异常时执行的固定逻辑3.0无论try内是否出现异常,异常是否被捕获,finally块内语句都会执行
try: result = 3 / 0except ZeroDivisionError as e: print(f"异常名:{type(e).__name__},异常信息:{e.__doc__}")else: print(result)finally: print("finally")异常名:ZeroDivisionError,异常信息:Second argument to a division or modulo operation was zero.finally如果改为result = 3 / 1,则输出
3.0finally⚠️ finally一定会执行,所以finally中要谨慎访问可能因异常导致不存在的变量
try: result = 3 / 0except ZeroDivisionError as e: print(f"异常名:{type(e).__name__},异常信息:{e.__doc__}")else: print(result)finally: print(result) # ❌ NameError: name 'result' is not defined print("finally")
def int_add(x, y): if isinstance(x, int) and isinstance(y, int): return x + y else: raise TypeError("参数类型错误")print(int_add(1, 2)) # 3print(int_add("1", "2")) # TypeError: 参数类型错误语法:assert [表达式], "异常信息",表达式一旦我们的断言的预期不符,自动抛出AssertionError
def divide(a, b): assert b != 0, "断言触发,除数不能为0" return a / bprint(divide(10, 2)) # 5.0print(divide(10, 0)) # AssertionError: 断言触发,除数不能为0assert本质上就是简化版的raise,多用于日常开发测试,在生产环境中,应当使用raise,可以通过执行带参数的python -O ***.py命令,屏蔽掉代码中全部的assert语句,直接跳过,不判断不抛异常
继承Exception自定义异常,自定义一个属性value
__init__(self, value)会覆盖掉父类Exception的__init__()
class MyError(Exception): """我是异常doc""" def __init__(self, value): self.value = value def __str__(self): return repr(self.value)if __name__ == '__main__': try: raise MyError('fuck') except MyError as e: print(f"触发自定义异常:{type(e).__name__},异常描述:{e.__doc__},异常信息:{e.value}")触发自定义异常:MyError,异常描述:我是异常doc,异常信息:fuck未完待续
python3中的根类,有且只有一个:object(小写)
⚠️大写的Object不存在于python内置中,是自己定义的,为防止混淆不建议使用
__bases__是python中一个内置的变量,代表基类
# 隐式继承,python3自动处理class Cat: pass# 显式继承class Dog(object): passif __name__ == '__main__': print( Cat.__bases__ ) # (<class 'object'>,) print( Dog.__bases__ ) # (<class 'object'>,)__init__()这个特殊方法作为类的构造方法,创建对象时会被自动调用。__init__(),否则最后一个覆盖前面的。构造方法就是一种实例方法
class Cat: '我是说明文档' def __init__(self): print('init') print(self) print(self.__class__)if __name__ == '__main__': cat = Cat() print(cat)init<__main__.Cat object at 0x000001982BE1D400><class '__main__.Cat'><__main__.Cat object at 0x000001982BE1D400>__init__中声明,__init__()中通过self.定义实例变量__init__()以外的变量是类变量,类似Java中的static对象.访问,类变量可以通过类.访问或对象.访问对象.访问到的是实例变量,类变量只能通过类.访问python的实例方法第一个参数必须是当前调用对象(类似Java中的this),名字可以任意取,但是通常都起名叫
self代表当前调用对象
⚠️
__init__()外面的同名变量前面没有static且和self.后面的变量名重名时,self.极易被Java程序员误判为是在为外面的变量初始化或赋值,这种Java的思路,在python中是错误的
例:
__init__()里面的重名name,age是实例变量,通过对象.访问__init__()外面的重名name,age是类变量,通过类.访问country变量不重名,可通过对象.访问,也可以通过类.访问class Stu: name = 'simaple_name' age = 0 country = 'China' def __init__(self, age, name): print('init') self.age = age self.name = name def speak(self): print(self.age, self.name)if __name__ == '__main__': stu1 = Stu(18, '元宝') stu2 = Stu(20, '大黄') stu1.speak() stu2.speak() print('---------------') print(Stu.name) print(Stu.age) print('-------------') print(stu1.country) print(stu2.country) print(Stu.country)initinit18 元宝20 大黄---------------simaple_name0-------------ChinaChinaChina有时候,一个类存在变量过多,逐一用参数赋值会很复杂,例如:
def __str__(self)同样是一个内置函数,类似Java中的toString(),打印对象时转换为字符串- 双下划线
__开头的变量,属于私有变量,类外不可直接访问
class Stu: def __init__(self, name, age, no, score): self.name = name self.age = age self.no = no self.__score = score def __str__(self): return f'{self.name}, {self.age}, {self.no}, {self.__score}'if __name__ == '__main__': stu1 = Stu('liming', 16, 10001, 100) print(stu1) print(stu1.name) print(stu1.age) print(stu1.no) #print(stu1.__score) ❌错误 AttributeError: 'Stu' object has no attribute '__score'liming, 16, 10001, 100liming1610001python是一门灵活的语言!解决这个问题,可以动态的给某个对象设置成员变量,例如为stu2动态指定一个变量no
self.__dict__可以代表对象所有变量
class Stu: def __init__(self, name, age, score): self.name = name self.age = age self.__score = score def __str__(self): return f'{self.__dict__}'if __name__ == '__main__': stu1 = Stu('liming', 16, 100) print(stu1) stu2 = Stu('liming', 16, 100) stu2.no = '10002' print(stu2){'name': 'liming', 'age': 16, '_Stu__score': 100}{'name': 'liming', 'age': 16, '_Stu__score': 100, 'no': '10002'}上面的写法不推荐,可以采用定义好再去赋值的写法
class Stu: def __init__(self): self.name = None self.age = None self.no = None def __str__(self): return f'{self.__dict__}'if __name__ == '__main__': stu1 = Stu() print(stu1) stu2 = Stu() stu2.age = 12 stu2.no = '123' stu2.name = 'sxh' print(stu2){'name': None, 'age': None, 'no': None}{'name': 'sxh', 'age': 12, 'no': '123'}还可以通过可变参数
class Stu: def __init__(self, **kwargs): self.name = kwargs.get('name', None) self.age = kwargs.get('age', None) self.no = kwargs.get('no', None) def __str__(self): return f'{self.__dict__}'if __name__ == '__main__': stu1 = Stu(name='lzj', age=19, no='10002') print(stu1) stu2 = Stu(name='xiaohong', age=19 ) print(stu2){'name': 'lzj', 'age': 19, 'no': '10002'}{'name': 'xiaohong', 'age': 19, 'no': None}在python中,属性可以进行访问权限控制,和Java类似,如果要访问受保护的属性,就定义方法,这是类封装性的体现
_单个下划线开头,仅仅起到提醒作用,但是不阻止访问,例如_age__双下划线开头,类外不可访问,否则程序运行出错,例如__age__dict__⚠️ python处理
__双下划线的底层实现,是将该变量替换成了_类名__私有变量名,通过将某个私有变量名修改为_类名__私有变量名的形式,可以突破访问控制,这种访问方式极不推荐
例:
class Stu: def __init__(self, **kwargs): self.name = kwargs.get('name', None) self.__age = kwargs.get('age', None) self._no = kwargs.get('no', None) def __str__(self): return f'{self.__dict__}' def getAge(self): return self.__ageif __name__ == '__main__': stu1 = Stu(name='lzj', age=19, no='10002') print(stu1) print(stu1.name) print(stu1.getAge()) print(stu1._no) #不建议的 print(stu1._Stu__age) #不建议的 #print(stu1.__age) #运行出错{'name': 'lzj', '_Stu__age': 19, '_no': '10002'}lzj191000219上面例子里面出现在类中,参数以self开头的方法,都是实例方法,在python中,还存在静态方法和类方法
在python中,有一种方法,只是出现在类中,但是不依赖于实例和类的普通方法,叫做静态方法,采用@staticmethod装饰器装饰,通常都是作为一种工具方法,除非传入否则不能访问类和实例的成员,可以使用实例名或类名调用,但是参数列表中不能出现self或cls
例:def sum(a, b)就是静态方法
class Stu: def __init__(self): name = None def call(self): self.sum(1, 2) self.__class__.sum(3, 4) Stu.sum(5, 6) @staticmethod def sum(a, b): return a + bif __name__ == '__main__': stu1 = Stu() stu1.call() stu1.sum(7, 8) Stu.sum(9, 10)类方法类似Java中的static方法,python的类方法声明时第一个形参永远是cls代表类本身(不是实例),同时除__new__()以外,所有类方法都要采用@classmethod函数装饰器修饰。
python的类方法既能通过类也能通过实例调用,但是为防混淆不建议用实例调用。
主要用于操作类属性或实现工厂模式。
可直接访问类属性,类方法和静态方法,不能直接操作实例属性或实例方法。
例:
class Stu: school = 'bupt' def __init__(self): name = None def call(self): pass @classmethod def classfunc1(cls): print(cls.__name__) print(cls.school) cls.sum(1, 2) cls.classfunc2() @classmethod def classfunc2(cls): print('classfunc2') @staticmethod def sum(a, b): return a + bif __name__ == '__main__': Stu.classfunc1() s1 = Stu() s1.classfunc2() s1.__class__.classfunc2()Stubuptclassfunc2classfunc2classfunc2还可以实现工厂方法,例如:
class Person: @classmethod def create(cls, name): return cls(**{'name': name}) def __init__(self, name): self.name = nameif __name__ == '__main__': p = Person.create('lsj') print(p.name)python中,可以定义类属性,类属性是被@property修饰的一种成员,对外表现是变量,对内实现是方法
类属性本身是类的,但是用于实例,可以实现更好的封装
例:
class Stu: @property def age(self): return self.__age def __init__(self, age): self.__age = age passif __name__ == '__main__': print(Stu.age) #<property object at 0x000001D82AA20D10> s1 = Stu(29) print(s1.age) # 29 s2 = Stu(34) print(s2.age) #34__call__()
让实例对象被当作函数调用
class Person: def __init__(self, name): self.name = name def __call__(self, age): self.age = age return selfif __name__ == '__main__': p = Person('lsj') q = p(22) print(q.name) #lsj print(q.age) #22__repr__()
和__str__()类似,同时定义时,__str__()优先
@dataclass的用途类似于Java中的Lombok。
@dataclass可以帮我们省略掉__init__(),__eq__(),__repr__()等常见方法的手写代码,专注于业务逻辑,@dataclass中写的变量名:类型的结构会自动转换为实例变量,自动添加到__init__()中,只有变量名不加类型的默认为类变量。
@dataclass既能声明带默认值的变量,也能生成不带默认值(= None)的变量,无默认值的在前,带默认值的在后。
⚠️
@dataclass装饰器会自动生成__init__(),一旦手写了__init__()会导致装饰器失效,所有自动功能全部关闭,如果想用了装饰器又要加自定义的初始化逻辑,用__post_init__(self, ...)避免冲突
例:
from dataclasses import dataclassfrom datetime import date, datetime@dataclassclass Book: # 类变量:所有书籍实例对象共享 publisher = "机械工业出版社" id: int = None bookName: str = None price: float = None author: str = None course_date: date = None start_time: datetime = None # 初始化后校验价格合法性 def __post_init__(self): print('__post_init__') if self.price is not None and self.price < 0: raise ValueError("书籍价格不能为负数!")if __name__ == '__main__': print(Book.publisher) book = Book(id = 1, bookName='疯狂python讲义', price=2.3) print(book) book = Book(id = 1, bookName='疯狂python讲义', price=-2.3)机械工业出版社__post_init__Book(id=1, bookName='疯狂python讲义', price=2.3, author=None, course_date=None, start_time=None)__post_init__Traceback (most recent call last): File "D:\PycharmProjects\python-lang-test\clazz\t3.py", line 27, in <module> book = Book(id = 1, bookName='疯狂python讲义', price=-2.3) ~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "<string>", line 9, in __init__ File "D:\PycharmProjects\python-lang-test\clazz\t3.py", line 21, in __post_init__ raise ValueError("书籍价格不能为负数!")ValueError: 书籍价格不能为负数!对__eq__()的重写,也会导致比较对象时,比较的是成员变量的值,而不是地址
if __name__ == '__main__': book1 = Book(id = 1, bookName='疯狂python讲义', price=2.3) book2 = Book(id = 1, bookName='疯狂python讲义', price=2.3) print(book1 == book2) # Truepython对象初始化o = Obj(),会经历以下几个过程:
1.调用该Obj类的__new__(cls,...)方法,在内存中开辟空间,创建一个空的实例对象
2.__new__(cls,...)执行完成,必须返回一个当前Obj类的实例对象,就是后续的self
3.python自动把返回的对象,传给__init__(self,...)的第一个参数self
4.调用__init__(self,...)给这个空对象绑定属性,初始化数据
5.返回初始化完成的实例对象给变量o
其中:
__new__(cls,...)是类方法,但是无需显式添加@classmethod装饰器__new__(cls,...)必须有返回值,返回当前类对象时执行__init__(self,...),返回None则跳过__init__(self,...)__new__(cls,...)的时机一定早于__init__(self,...),先创建再初始化__init__(self,...)例:
class Person: def __new__(cls, name): obj = super().__new__(cls) #调用父类(直到object)的__new__方法开内存空间, print('new') return obj def __init__(self, name): print('init') self.name = nameif __name__ == '__main__': p = Person('liming') print(p.name)filebeat是传统elk组件中logstach的升级替代,能够高性能的采集一些中间件的日志到es中,供检索分析。
首先要安装filebeat到nginx所在服务器,因为我的服务器是rocky linux属于redhat系,故这里通过yum安装,先设置安装源
导入GPG-KEY
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch新建一个elastic.repo文件在/etc/yum.repos.d下,并粘贴安装源地址
vim /etc/yum.repos.d/elastic.repo
[elastic-9.x]name=Elastic repository for 9.x packagesbaseurl=https://artifacts.elastic.co/packages/9.x/yumgpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearchenabled=1autorefresh=1type=rpm-md接下来执行安装,直到安装完成
yum install filebeat -y首先确认nginx的日志路径和日志格式,一般日志路径默认就是:
/var/log/nginx/access.log 常规访问日志/var/log/nginx/error.log 错误日志在nginx.conf配置文件中,默认的日志格式是:
log_format main ' $remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"';为了区分各个主机的访问记录,我选择增加一个主机的字段:$host
log_format main '$host $remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"';亲测filebeat可以识别上述的日志格式,自动提取有效信息
然后设置filebeat,通过yum安装的filebeat,默认全局配置文件位于/etc/filebeat/filebeat.yml,有这样几项需要修改
output.elasticsearch: # 改成自己es地址和端口 hosts: ["localhost:9016"] # 改成自己的索引格式 index: "nginx-logs-%{+yyyy.MM.dd}" # 通信协议按需要修改 protocol: "http" # es用户名密码,必须设置 username: "elastic" password: "***************"# 需要新增这两项,索引数据格式模板名称setup.template.name: "nginx-logs"setup.template.pattern: "nginx-logs-*"然后对nginx的采集功能进行设置,filebeat支持很多中间件的日志采集,通过yum安装的filebeat,默认的各中间件的采集配置文件位于:/etc/filebeat/modules.d/
首先要将默认的nginx配置文件nginx.yml.disabled复制出一份nginx.yml,因为最后filebeat只会自动导入读取.yml结尾的文件
cp /etc/filebeat/modules.d/nginx.yml.disabled /etc/filebeat/modules.d/nginx.ymlvim编辑/etc/filebeat/modules.d/nginx.yml配置文件,针对nginx的采集进行配置
- module: nginx # 打开常规访问日志采集,指定日志路径 access: enabled: true var.paths: ["/var/log/nginx/access.log"] var.timezone: "Asia/Shanghai" # 打开错误日志采集,指定日志路径 error: enabled: true var.paths: ["/var/log/nginx/error.log"] var.timezone: "Asia/Shanghai"都修改完成后,通过filebeat test config命令,验证配置文件是否有语法错误
[root@VM-0-3-rockylinux ~]# filebeat test configConfig OK然后启动filebeat,并且能看到进程,启动成功
[root@VM-0-3-rockylinux ~]# systemctl start filebeat[root@VM-0-3-rockylinux ~]# ps -ef | grep filebeatroot 279214 1 0 Apr17 ? 00:00:09 /usr/share/filebeat/bin/filebeat --environment systemd -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeatroot 484905 454652 0 14:33 pts/2 00:00:00 grep --color=auto filebeat登录kibana,打开开发工具,就能看到filebeat建的索引和采集到的日志了,还可以根据业务需要制作图表等
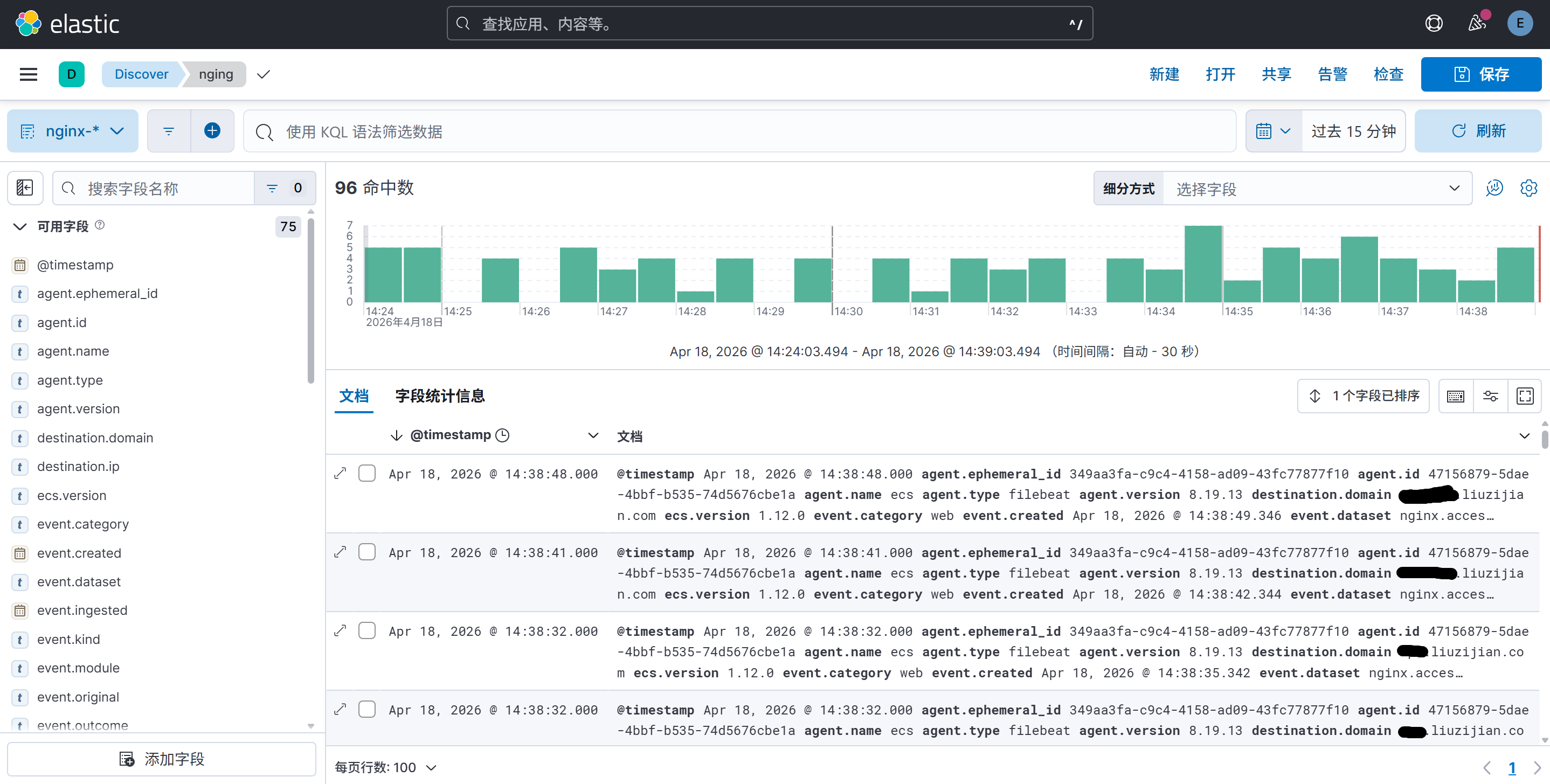
还可以通过检索,根据各种字段进行聚合,通过访问规律查出一些攻击和刺探的恶意请求,例如:
1.查询某一天,某个主机下,某个IP访问某个路径的次数,可以很容易发现恶意请求的规律,揪出恶意访问者
GET /nginx-logs-2026.04.18/_search
{ "size": 0, "aggs": { "domain_counts": { "terms": { "field": "url.domain", "size": 20000 }, "aggs": { "domains_per_ip": { "terms": { "field": "source.ip", "size": 20000 }, "aggs": { "domains_per_path": { "terms": { "field": "url.path", "size": 20000 } } } } } } }}
2.查询某个IP地址段的访问记录
GET /nginx-logs-2026.04.25/_search
{ "size": 8000, "query": { "match": { "source.ip": "221.229.0.0/16" } }, "sort": [ { "@timestamp": { "order": "asc" } } ] }
1.函数代码以def关键字开头,后接函数标识符名称和圆括号()
2.任何传入的参数和自变量必须放在圆括号内,圆括号中定义参数
3.函数内容以冒号:开始,需要缩进
4.return表达式结束函数,返回一个值给调用方,不带表达式的return相当于返回None
5.若暂无函数实现,函数体内写一个pass关键字,可避免语法错误
def 函数名(参数列表): 函数体 return 返回值例:
def greet(name, age): print("Hello World")Python函数参数不需要声明类型,解释器会自动推断,但是会带来难以理解,隐藏BUG,开发效率低下等问题,因此类型注解通过引入可选的类型信息解决这些问题,明确指出函数和返回值的类型,让代码更加健壮可维护。
在实现复杂逻辑和对外提供公共接口时,都应当使用类型注解
例:
func.py
def greet(name: str, age: int) -> str: return f"Hello World {name}, age {age}"但是,调用时仍然可以不遵守
func.py
def greet(name: str, age: int) -> str: return f"Hello World {name}, age {age}"if __name__ == '__main__': print( greet('lzj', 12.6) )此时可以通过mypy工具包,对我们的代码进行检测,会检测出问题
先安装mypy工具 pip install mypy,再进行检测
PS D:\PycharmProjects\python-lang-test> mypy .\func\func.pyfunc\func.py:5: error: Argument 2 to "greet" has incompatible type "float"; expected "int" [arg-type]Found 1 error in 1 file (checked 1 source file)如果要彻底避免,需要进行严格类型检查
def add(a: int, b: int) -> int: if not isinstance(a, int): raise TypeError(f"参数a期望类型int,实际传入{type(a).__name__}") if not isinstance(b, int): raise TypeError(f"参数b期望类型int,实际传入{type(b).__name__}") return a + bresult2 = add('5', 3)print(result2)Traceback (most recent call last): File "D:\PycharmProjects\python-lang-test\func\func.py", line 9, in <module> result2 = add('5', 3) File "D:\PycharmProjects\python-lang-test\func\func.py", line 4, in add raise TypeError(f"参数a期望类型int,实际传入{type(a).__name__}")TypeError: 参数a期望类型int,实际传入str在函数返回值是某种特定类型或None时使用Optional,等价于Union[具体类型, None]
例:dic.get(name)可能返回字典的值,也可能在没有值时返回None
from typing import Optionaldef age(name: str) -> Optional[int]: dic = {'a':16, 'b':17, 'c':18} return dic.get(name)if __name__ == '__main__': print(age('dd')) print(age('a'))None16以正确的形式传入函数,数量要和声明时保持一致
from typing import Optionaldef fun(age:int) -> Optional[int]: print(age) return agefun(10)函数调用使用关键字参数来确定传入的参数值
def fun(age:int, name:str) : print(age) print(name)fun(name='lzj', age=10)10lzj调用函数时,如果没有传递参数,则会使用默认参数
def fun(name:str = "a", age:int = 25) : print(f"fun---name:{name} age:{age}")fun()fun("zhangliang")fun("wangqiang", 28)fun---name:a age:25fun---name:zhangliang age:25fun---name:wangqiang age:28加了*的参数会以元组的形式传入,一般这种参数放在参数列表后面
格式:
def fun([普通参数], *var_args_tuple) : 函数体例:
def print_info(num, *var_tuple): print(num) print(var_tuple)print_info(70,1,2,3,4,5)print_info(80)print_info(90,*(1,2,3,4,5))70(1, 2, 3, 4, 5)80()90(1, 2, 3, 4, 5)如果后面还有参数,必须通过关键字参数传入,如果没有给不定长的参数传参,那么得到的是空元组
def print_info1(seq, *var_tuple, age) : print(seq) print(var_tuple) print(age)print_info1(1,20,30,40,50, age = 25)print_info1(70, age = 29)1(20, 30, 40, 50)2570()29加了两个星号的参数,会以字典的形式传入,“**”可变参数的后面不能再有其他参数,因此“**”可变参数往往在“*”可变参数的后面(如果有的话),并且作为整个参数列表的最后一个参数
调用时,直接在参数列表直接传入键值对
def func(nid, **info): print(nid) print(info) if __name__ == '__main__': func(10, name='苗苗', age=22) func(11, name='欣欣', age=27)10{'name': '苗苗', 'age': 22}11{'name': '欣欣', 'age': 27}如果要传字典,需要用**前缀,否则报错
if __name__ == '__main__': dic = {'name':'苗苗', 'age': 18} #func(10, dic) ❌ func(10, **dic) #✅ func(10, **{'name':'苗苗', 'age': 18}) #✅上面出现的*() **{}就是一种解包/打包的写法
概念
异同:
| 语法 | 含义 | 类型 | 使用场景 |
|---|---|---|---|
*args | 可变位置参数 | 元组 | 不确定数量的位置参数 |
**kwargs | 可变关键字参数 | 字典 | 不确定数量的关键字参数 |
*args, **kwargs | 组合使用 | - | 通用函数包装、装饰器、继承 |
总结
*args:接收多余的位置参数(arguments)**kwargs:接收多余的关键字参数(keyword arguments)例:
def func(a, *args, **kwargs): print(a) print(args) print(kwargs)func(100,1,2,3,k1=20, k2=30)func(200,*(1,2,3),**{"k1":20, "k2":30})100(1, 2, 3){'k1': 20, 'k2': 30}200(1, 2, 3){'k1': 20, 'k2': 30}例:参数解包
传递参数时,可以将多个实参用*组合为元组,传入形参
def sum_num(a, b, c): return a+b+cif __name__ == '__main__': print( sum_num(1, 2, 3) ) #6 print( sum_num( *(1, 2, 3) ) ) #6 let_tuple = (1, 2, 3) print( sum_num( *let_tuple ) ) #6python使用lambda来创建匿名函数
与java的lambda的区别:通常只有一行代码
组成:
lambda arguments : expression例:
某种操作函数operator,传入待操作数a, b以及操作规则func,将1和2以及一个加法计算规则add()传入,令operator函数对两个数进行加法
def add(a, b): return a + bdef operator(a, b, func): return func(a, b)print( operator(1, 2, add) ) # 3add()就无需单独再定义函数,可以匿名成为一个加法计算规则的lambda:lambda x, y: x + y
print( operator(1, 2, lambda x, y: x + y ) ) #3lambda可以赋给变量,称为函数变量,函数变量保存的是函数类型的值,对函数变量进行调用(加小括号),才能得到对应函数的返回值类型的值
例:
f = lambda: "Hello, world!"print(f) # <function <lambda> at 0x000002A2226B7C40>print(f()) # Hello, world!x = lambda a, b, c : a + b + cprint(x(5, 6, 2)) #13在python中,lambda通常可以和一些内置函数配合使用,实现一些效果
numbers = [1, 2, 3, 4, 5, 6, 7, 8]even_numbers = list(filter(lambda x: x % 2 == 0, numbers))print(even_numbers) # 有三名学生的姓名和年龄,按年龄排序student_list = [{"name": "z3", "age": 36}, {"name": "li4", "age": 14}, {"name": "w5", "age": 27}]print(sorted(student_list, key=lambda x: x["age"]))# map() 的主要作用是将给定的函数批量应用到可迭代对象的每个元素上,实现数据转换map_result = map(lambda x: x * x, [0, 1, 3, 7, 9])print(list(map_result)) # filter() 的主要作用是将给定的函数**批量应用**到可迭代对象的每个元素上,实现数据过滤filter_result = filter(lambda x: x >= 0, [-0, -1, -3, 7, 9])print(list(filter_result)) [2, 4, 6, 8][{'name': 'li4', 'age': 14}, {'name': 'w5', 'age': 27}, {'name': 'z3', 'age': 36}][0, 1, 9, 49, 81][0, 7, 9]闭包是python实现函数式编程的重要基础
定义:内部函数引用了嵌套它的外部函数的变量或参数,且内部函数被返回或暴露出去,从而保留了外部函数作用域(即便已经调用完成)的函数对象。
例:定义一个函数lazy_sum(),嵌套一个内部函数inner(),并将内部函数inner()作为返回值返回,并赋值给了num,但是是个函数对象,只有执行num(),内部函数inner()才会执行,将外部函数的参数*args进行累加。在这个过程中lazy_sum()的执行完成后,并没有被释放,参数*args也被保留下来,什么时候内部函数执行了,什么时候真正完成调用。
def lazy_sum(*args): def inner(): result = 0 for n in args: result = result + n return result #返回函数 return innernum = lazy_sum(11, 12)print(num) # <function lazy_sum.<locals>.inner at 0x0000023A15FD62A0>print(num()) # 23print(num.__closure__) #闭包保存的变量元组 (<cell at 0x00000241568DB5E0: tuple object at 0x00000241568E8940>,)print(num.__closure__[0].cell_contents) # 闭包保存的变量 (11, 12)例:带参数
def hello(s1): def world(s2): return s1+' '+s2 #返回函数 return worldfun = hello('hello')print(fun('world')) #hello worldprint( hello('hello')('world') ) #hello world总结:
利弊:
装饰器类似Spring AOP,前置/后置通知
装饰器(decorators)是Python中的一种高级功能,它允许你动态地修改函数或类的行为。
装饰器本质上是一种函数,它接受一个函数作为参数并返回一个新的函数或修改原来的函数,可以实现不修改被修饰对象的源码和调用方式的前提下,为其额外添加功能(日志,计时,权限校验等)。
执行原理:
例:装饰器的实现,使用aop()函数增强hello()函数,aop()函数替换掉原hello()函数,直接调用aop()函数
def aop(func): def wrapper(): print("before") func() print("after") return wrapperdef hello() : print('hello world')if __name__ == '__main__': aop(hello)()beforehello worldafter例:简化写法,@加上一个闭包函数,就能构成一个装饰器函数,语法类似Java中的注解
def aop(func): def wrapper(): print("before") func() print("after") return wrapper@aopdef hello() : print('hello world')if __name__ == '__main__': hello()beforehello worldafter例:带参数的装饰器
def aop(func): def wrapper(*args, **kwargs): print("before") func(*args, **kwargs) print("after") return wrapper@aopdef hello(name) : print(f'hello,{name}')if __name__ == '__main__': hello('sxh')