感谢订阅陶其的个人博客!
我有一份兼职,目前处于运维状态。
因为我的懒,导致上周被入侵了三次。
第一次
1、入侵警告
事情开始时间是2025年03月18日,周三。
老板(他有阿里云主账号)在群里发,接到阿里云安全警告短信,说是我使用的RAM账号的AccessKey泄露了,检测到对云资源有异常试探访问记录。
我赶紧登录我的RAM账号,因为我的RAM账号被授权几乎所有权限,所以一开始我并没有登录老板的主账号。
我登录之后,看了一眼告警日志,说是我这个RAM账号的一个AccessKey泄露了,对方(后面称为黑客)使用这个AccessKey去试探性访问云资源的一个接口,去获取基本信息,属于中低危警告。
我一时有一点懵,我有点纳闷,并不清楚这个AccessKey怎么突然泄露了。
因为这个AccessKey只在下面几个地方存在:
- 我自己电脑的项目里;
- Gitee私有代码仓库;
- 测试服务器部署的jar里;
- 生产服务器部署的jar里。
可以说保护的算不错来了,应该并没有泄露的可能,然后我检查了一下:
- 我电脑里有360,我也扫描了一下,没发现电脑被入侵的记录。
- 检查了一下Gitee账号,发现没有其他异常IP地址登录和异常动态,我也把密码改了,之前授权但是不用了的Token也被我删除了。
- 那最大的可能就是从测试服务器或者生产服务器泄露的。
因为这个AccessKey涉及到好几个生产项目的使用,这些项目需要一直保持可运行状态。
被中低危警告的级别迷惑了的我,想着先申请一个新的AccessKey,把所有测试环境项目和生产环境项目的AccessKey都替换之后再去禁用这个泄露的AccessKey。这样那些生产项目只需要经历2-3分钟重启停服,问题不大。正好这个AccessKey也已经使用9个月了,早就该换了。
2、被黑客创建高权限RAM账号
结果正在我按部就班愉快的更换项目代码里Accesskey时,老板又发了一条信息,说阿里云发警告短信,说泄露的AccessKey正在创建新的高权限的RAM账号。
?(此处应该有:黑人问号脸.gif)
发生了什么?这次这么刺激的么?
然后等我从项目代码切回阿里云操作界面时,我发现我的RAM账号被退登了(被踢了)。
我以为是长时间没操作,登录过期了,当我再尝试登录的时候,登录界面弹出提示:当前账号不允许RAM用户登录,请使用主账号登录联系客服。
一开始我没仔细看到“联系客服”,心里卧槽一声,我这个账号不会被黑客删了吧,对方不会已经拿到主账号的权限了吧。
我的RAM账号不能用了,我又想到对方还创建了一个高权限的RAM账号。
我赶紧问老板要他的手机号码和验证码登录主账号。
结果老板在忙,不回我消息,电话也直接挂断。
在遭到我的消息轰炸之后,老板终于把验证码发了过来。
经历好久终于登录上主账号,那时候心里特别忐忑,千万不要动云资源和服务器数据库啥的呀,如果被勒索了,这兼职铁定完了。
此时阿里云的顾问也打来电话,说账号疑似被入侵了,我说我正在处理了,不得不说阿里云的安全嗅探和提醒机制是真🐂🍺。
3、紧急处理
所以等我登录上主账号之后,我第一时间查看RAM列表,然后把对方创建的RAM账号给禁用并删除了,然后我赶紧把我RAM账号的AccessKey给禁用了,防止对方再搞事情。
这个时候已经顾不上线上系统服务会不会崩了,先和对方对完线再说。
等都禁止的差不多了,我才去看操作日志,看一下对方都做了些啥,看看有没有什么损失,赶紧处理或者修复。
然后我就看到,对方一开始在使用我的RAM账号的AccessKey去试探访问各种账号或者云资源的API接口,然后就用这个Accesskey自己创建了一个高权限RAM账号。
因为我当初为了省事,直接给我自己的RAM账号赋予了主账号几乎所有权限,然后在创建AccessKey时,不想一个一个勾选,索性也直接赋予所有权限了。
4、阿里云🐂🍺
但是庆幸的是,当对方创建了高权限RAM账号之后,触发了阿里云安全限制,直接禁止这个主账号下所有RAM账号登录。所以我看到了对方登录自己创建的RAM账号的控制台时,提示操作失败。
因为用一个RAM账号的AccessKey去创建另一个高权限的RAM账号,这个接口不仅是高敏结构,这个操作本身就很反常,因为创建RAM账号基本都是主账号或者在控制台操作,几乎很少会是RAM账号的AccessKey去创建另一个高权限的RAM账号。
主要是此时,我们并没有购买阿里云的安全服务和防火墙之类的安全产品,纯阿里云自带的免费基础安全服务在顶。
此处我只能说:阿里云🐂🍺
我的RAM账号也是被阿里云禁止登录的,直接禁止了所有RAM账号登录控制台,所以黑客没有成功登录自己的RAM账号,但是RAM账号下属的AccessKey还能用,所以我直接把泄露的AccessKey给禁用了。
5、排查处置
然后经过我细细的排查,发现黑客只进行了一些查询操作和创建账号的操作,并没有对云资源和其他东西做出增删改的操作。
黑客是使用徐州的一个代理服务器进行入侵的,IP地址:49.68.57.93。
虽然我这边阿里云限制了常用登录地址是徐州,结果对方的IP地址就是徐州,这个正好放过去了。
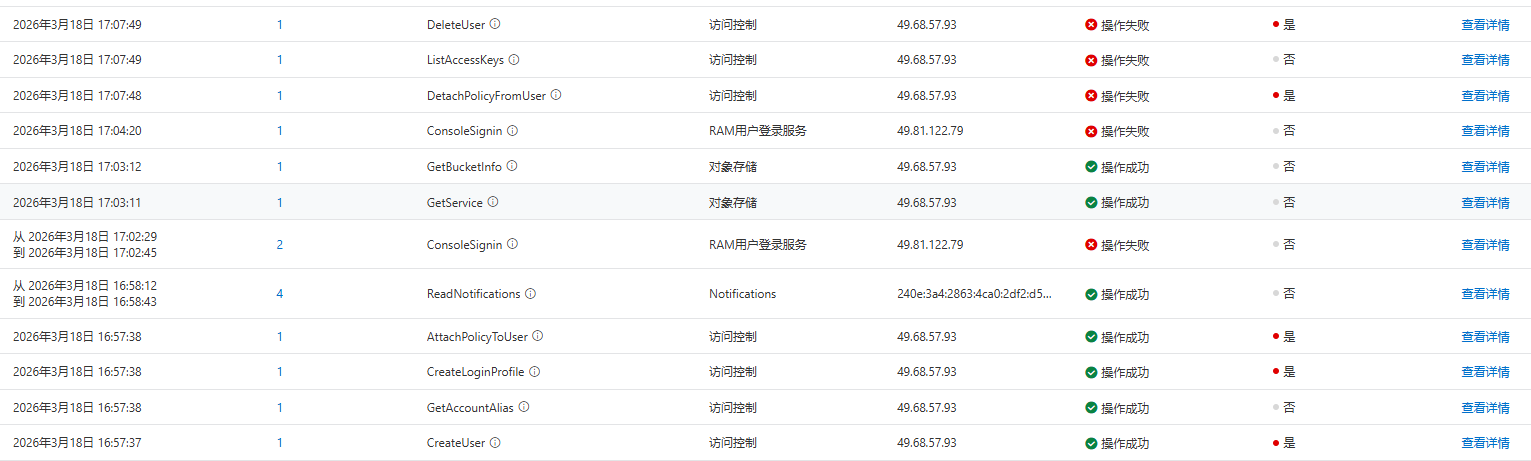
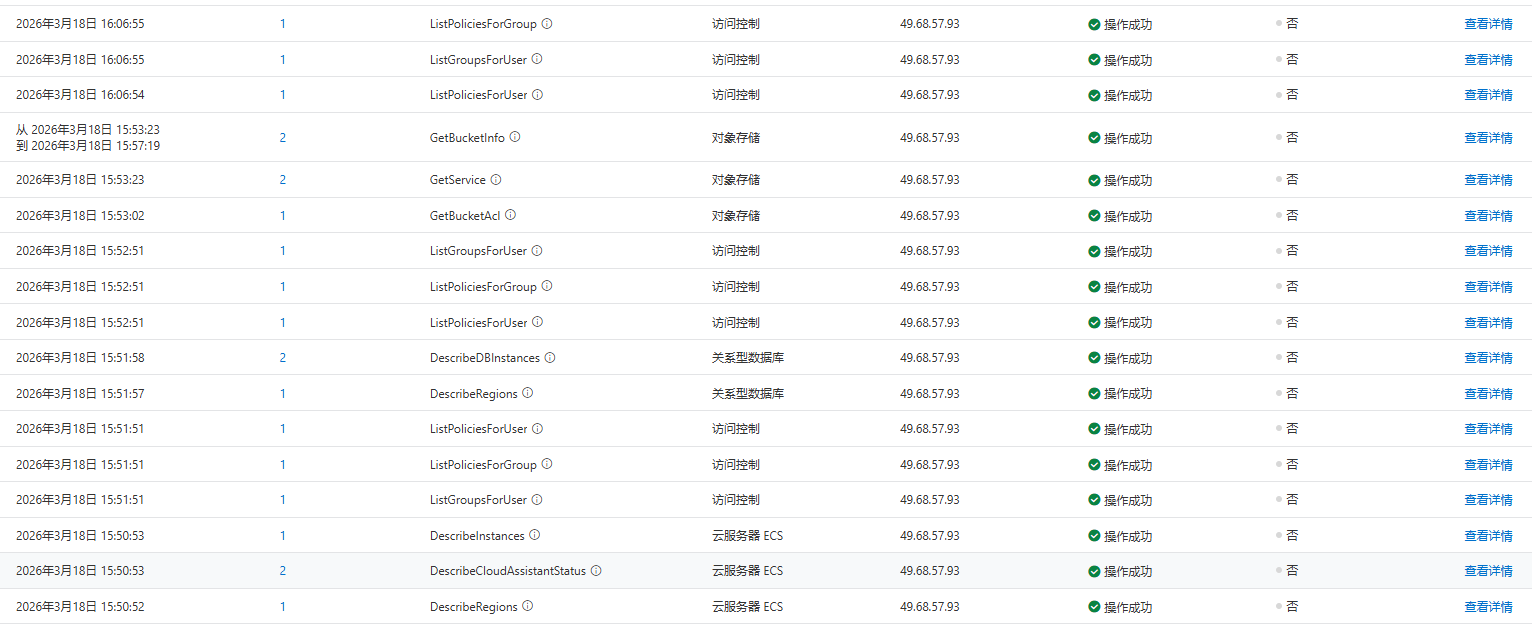

此时,各项目服务还处于停服的状态。
所以我赶紧更换项目的AccessKey为自己新申请的AccessKey,先恢复项目服务再说。
我把所有项目的已泄露AccessKey都换成新的AccessKey并恢复运行之后。
6、入侵原因解析并处理
我开始排查泄露原因,不然对方还是能通过泄露渠道再次拿到AccessKey的。
因为之前简单排查过,大概率是从测试服务器或者生产服务器泄露的。
这两个服务器的账号密码,我们保护的也挺严格的,应该不是账号密码问题。
所以我就先从漏洞方面考虑。
果然在排查期间,发现对方就是从测试服务器的Redis的一个漏洞入侵的,然后一步一步提权,然后访问系统里的jar文件,解析到里面的AccessKey,才导致的AccessKey泄露的。
我看了一下,服务器里部署的Redis Server版本是6.2.6,这个版本有一个高危漏洞,可以通过漏洞逐步提权到root账号级别。
果然,我赶紧把测试服务器和生产服务器的redis版本从6.2.6升级到6.2.20(安全版本),之所以没有升级到最新的安全版本,是因为老项目了,能不动就不要大动,小版本升级更保险一些。
然后我在Redis版本升级之后,还检查了一些服务器里有没有新增异常的账号,以及root近期登录日志啥的,以及那个入侵的IP地址在服务器有没有其他操作啥的,结果没有发现异常。
我想着此次危机应该是度过了,就结束了运维。
第二次
本来我以为入侵事件就这么结束了,毕竟我已经把漏洞都给修复了,而且排查了对方没有在服务器里留东西,测试和生产服务器的root的密码我也换了。
结果打脸来的如此之快。
因为我的懒惰,并没有做过多的防御设置,结果就是再次被入侵了。
1、再一次被入侵,破防
时间发生在2026年03月21日,那天是周六。
估计是对方想着,这天是周末,应该不会被发现的那么快,即使发现了也不会处置的那么快。
但是黑客应该没有想到,我主职是上六休一,我那天上班,所以接到老板的消息之后就立即着手处置。
想利用我休息时间偷袭我,没想到我周六也上班吧,哈哈呜呜呜呜~
我特么周六上班,还被黑客入侵。
焯!毁灭吧。
言归正传。
我发现又是通过这个RAM的AccessKey泄露导致的,而这个AccessKey是前两天刚换的新的AccessKey。
我擦,怎么又泄露了。
2、紧急排查
有了上一次经验之后,我在他还在进行查询一些权限接口的时候,第一时间封禁了这个AccessKey。
项目停就停吧,先保命。
我禁掉AccessKey后,就开始着手排查,是不是服务器还存在漏洞,结果发现没有了。
因为我其实对运维,特别是安全方向的运维并不熟悉,所以我让AI给我生成一堆全面检查CentOS系统的检查入侵的命令,我还把黑客的IP地址也给AI了。
然后我使用AI给我的命令一条一条的排查。
果然发现了端倪。
在测试环境的MySQL中,发现了这个IP地址的几条长链接。
淦!
他没在系统里留后门和木马,他在MySQL里留了长连接,然后潜伏几天之后悄悄摸摸进行账号提权,再一次拿到了新部署的jar包,解析到了新的AccessKey。
淦!
上次升级了Redis的版本,检查了服务器层面,修复了漏洞,结果偏偏漏掉了MySQL,其实也不算漏掉,我想着MySQL版本是安全的,所以就没在意。
3、紧急处置
我赶紧把所有异常的MySQL链接全部杀死,然后更换MySQL的密码和端口。
又排查了一遍测试服务器里所有的异常链接、定时任务之类的可能留后门或者木马的地方。
而且这次我直接在测试服务器的防火墙里封禁了这个黑客的IP地址。
我不知道我的RAM账号本身是不是也出现了问题。
我直接问老板要来了主账号,又重新创建一个RAM账号,把之前的RAM账号连带泄露的AccessKey都删除了。
然后用新的RAM账号,重新申请了AccessKey。
这次我留了一个心思,我创建了两个AccessKey,然后分别用在测试环境和生产环境的项目配置文件里。如果万一后面再出现泄露,我好知道是哪个服务器泄露的。
然后在项目打包构建jar的时候,让不同环境仅能把自己环境的配置文件打进去,其他环境配置文件不会打进jar包。之前我都是直接打,一个jar里包含所有环境的配置文件。
4、自我感觉良好
然后我感觉我应该处理完了。
排查了Redis和MySQL、排查了系统层面的链接和日志、更换了RAM账号和AccessKey,并且分环境打包。
于是我结束了这次的处置。
但是世事无常,大肠包小肠。
第三次
时间是2026年03月23日上午,周一。
仅仅过去一天,接到老板的消息,新RAM账号的新AccessKey再次泄露。
MD!
没完了,盯着我打。
我上RAM账号,查了一下,是生产服务器的AccessKey泄露的。
我特么,淦!
他是怎么进到生产服务器的。
1、全面处理
倒不是说生产服务器是内网,而是jar包里就没有生产服务器的IP地址,后面我才想明白,可能是之前黑客通过访问阿里云的API查询接口,拿到了云服务器的信息,所以才被入侵的。
上次我只封禁了测试服务器的防火墙对这个IP的禁止访问,忘了生产了,想着他也没有入侵成功生产,生产服务器的MySQL、Redis、系统日志都没有显示被异常访问过,没有异常链接,就忘记封禁了。淦!真的一点懒都不能偷。
我又第三次的封禁了AccessKey,我担心另一个测试服务器用的AccessKey也泄露了,索性两个都禁用了。
因为,一个RAM账号只能同时有两个AccessKey,我又申请了一个RAM账号,用新RAM账号申请的两个AccessKey重新替换。
在替换之前,我还做了一些操作。
- 关闭阿里云生产服务器的MySQL的远程连接;
- 关闭阿里云生产服务器的Redis的远程连接;
- 在阿里云的安全组里限制测试服务器MySQL的端口访问IP仅为我当前所在的动态IP;
- 在阿里云的安全组里限制测试服务区Redis的端口访问IP仅为我当前所在的动态IP;
- 在阿里云的安全组里限制生产服务器和测试服务器的22端口访问IP仅为我当前所在的动态IP;
- 对最新RAM账号新申请的两个AccessKey做网络访问限制,用于测试的AccessKey只能通过测试服务器IP访问,用于生产的AccessKey只能通过那几台生产服务器的IP访问。
- 在测试服务器和生产服务器,全面禁止黑客的IP地址访问;
- 更换测试服务器和生产服务器的MySQL和Redis账号密码;
- 把测试服务器和生产服务器的root账号的SSH连接登录方式,从账号密码改成公私钥证书登录,然后禁用账号密码登录;
- 把测试项目和生产项目的配置文件中的AccessKey都做成了环境变量,Key值存放在系统的文件中,项目本身不自带密钥;
这样,直接进行了AccessKey的固定IP访问、服务的指定动态IP访问(我每次想要远程连接这些服务,都要登录阿里云账号进行当前所在IP地址的临时授权)、服务器登录方式的变更。
说实话,第三次的AccessKey的泄露,我并没有查到从哪里泄露的,实在是没有一丁点头绪,但是我把能封禁的或者能限制IP的地方都限制了。
现在即使黑客拿到了AccessKey也无法进行任何操作,因为这些AccessKey只接受来自我允许的服务器IP地址的访问,而服务器层面也做了加固和防御。
然后我还针对我的RAM账号进行了权限收缩,解除了一些不必要的高权限授权。
所以,这次应该能真正的结束了…吧。
真的,心累了,真不能偷懒。
我之前就是想偷懒,不想每次登录服务器或者使用服务都要登录阿里云进行IP授权,才直接放开所有IP都可访问的,大忌啊!
入侵事件后续
今天(2025年04月01日),项目的实际权属方,我们地方的某市政单位。
今天单位人员联系我,说市局技术发现这个系统存在漏洞,可以无权限下载服务器内任意文件。
然后发了一个入侵拿到各个权限的截图。
我擦,感情是主管部门进行的渗透测试。。。
我TM服了。
我这边赶紧搜索了一下,结果发现是若依框架早期版本的一个漏洞:CNVD-2021-01931任意文件下载漏洞。
这个项目的代码都是上古的了,所以这个漏洞是存在的,怪不得每次都被拿到jar包。我还以为是入侵了服务器后一步一步提权拿到的。
不过我第三次的处理方案能杜绝对方在拿到jar之后的进一步入侵,只是这个漏洞我当时没有发现,怪不得对方能一而再再而三的入侵成功。。。
我刚要把问题给修复了,结果老板告诉我,这个系统早就超出了我们运维的合同期,现在已经不需要我们运维了。
额…
我还能说什么呢?
我只能说:
淦!
喜欢记录一下我因为懒导致六天被入侵三次的经历这篇文章吗?您可以点击浏览我的博客主页 发现更多技术分享与生活趣事。


























{kind=link}
{kind=link}