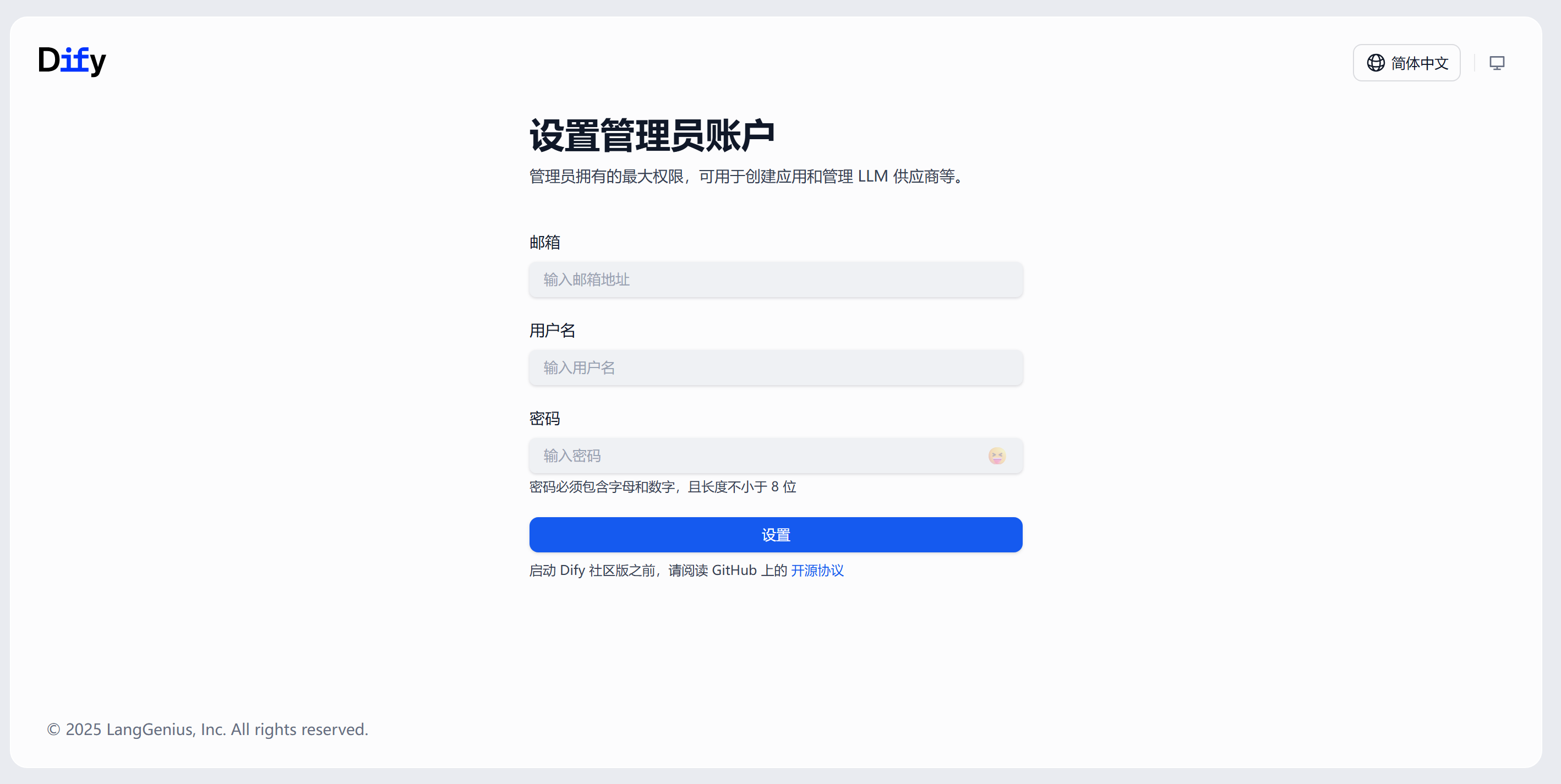
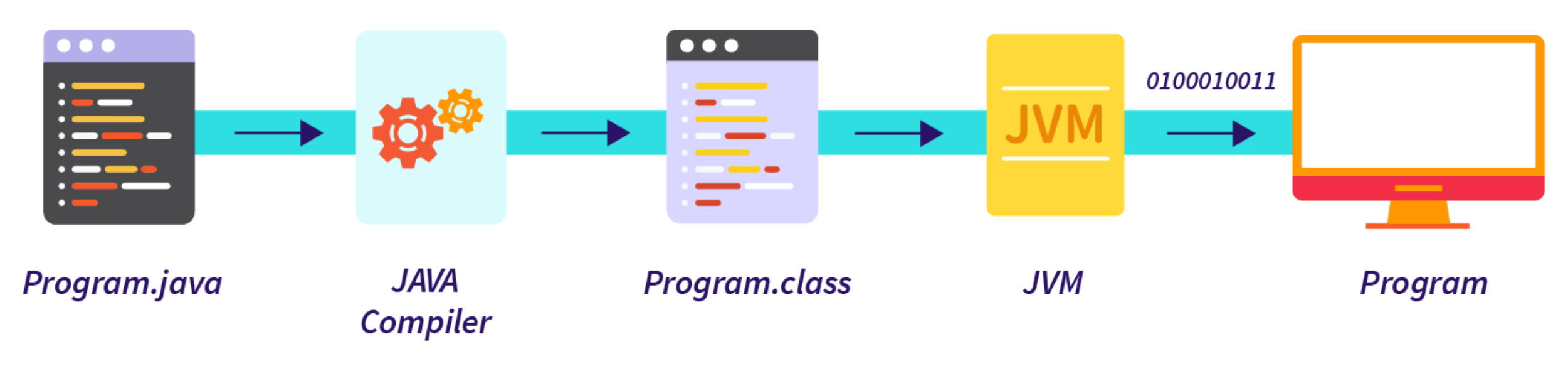
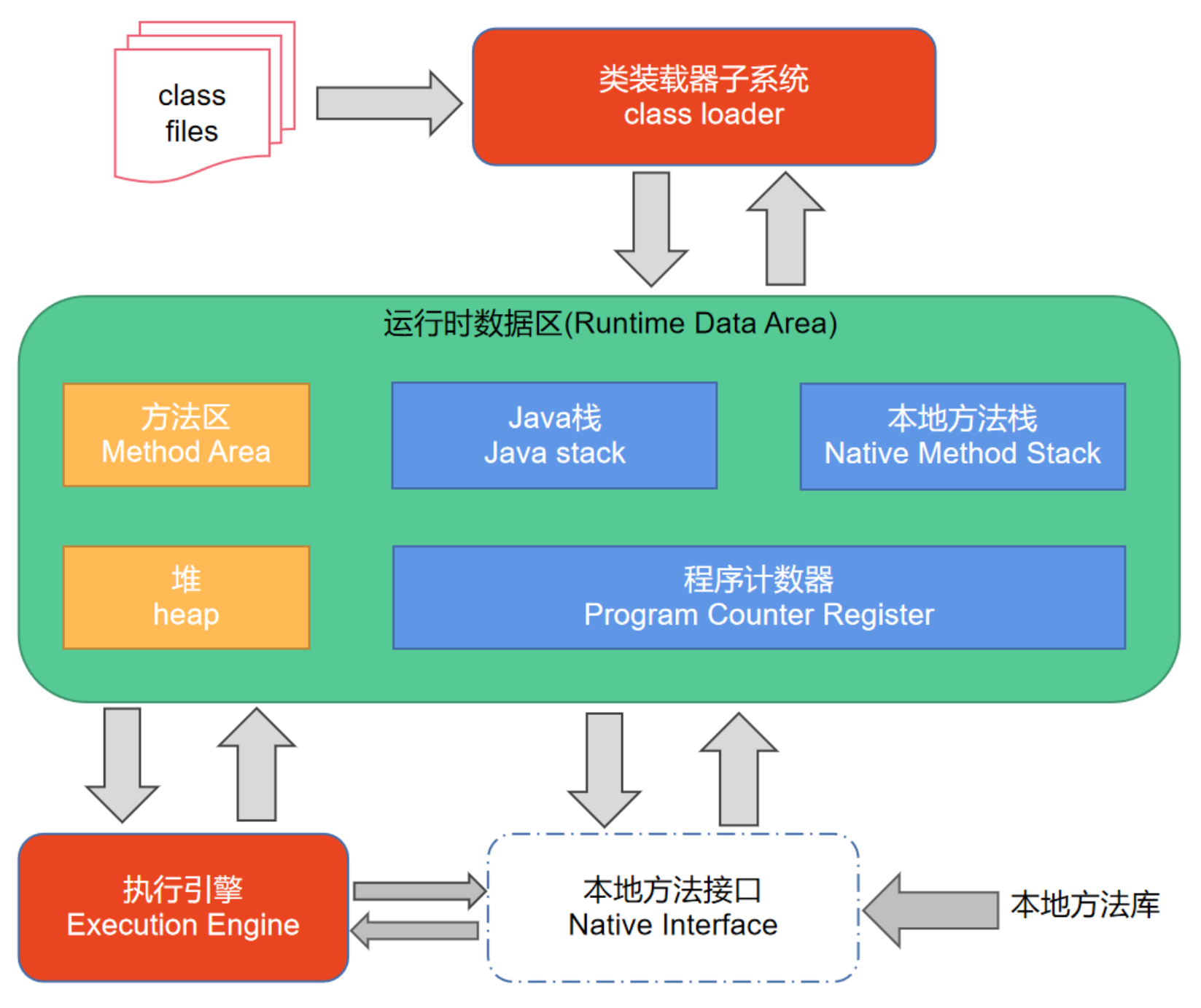
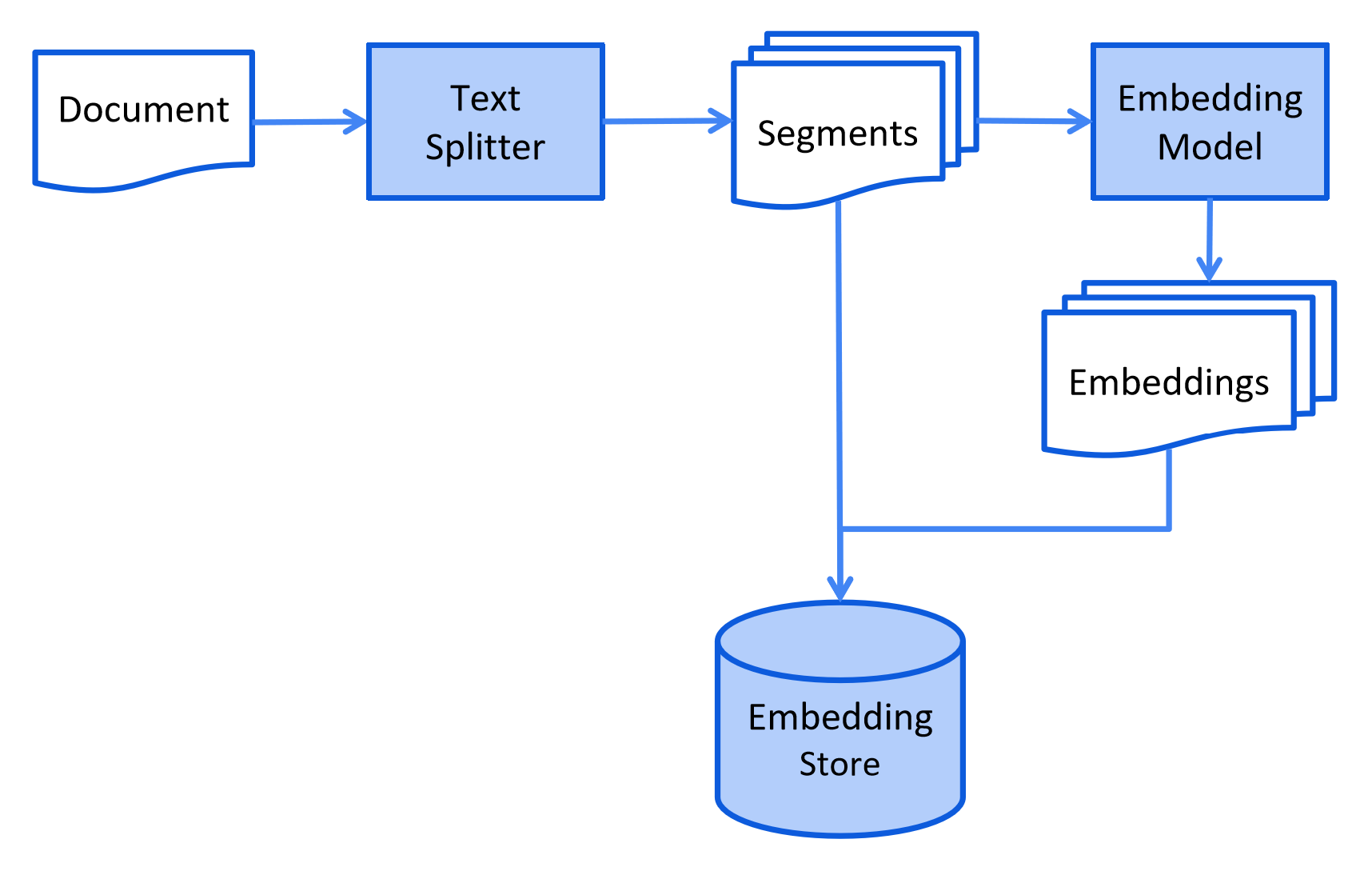
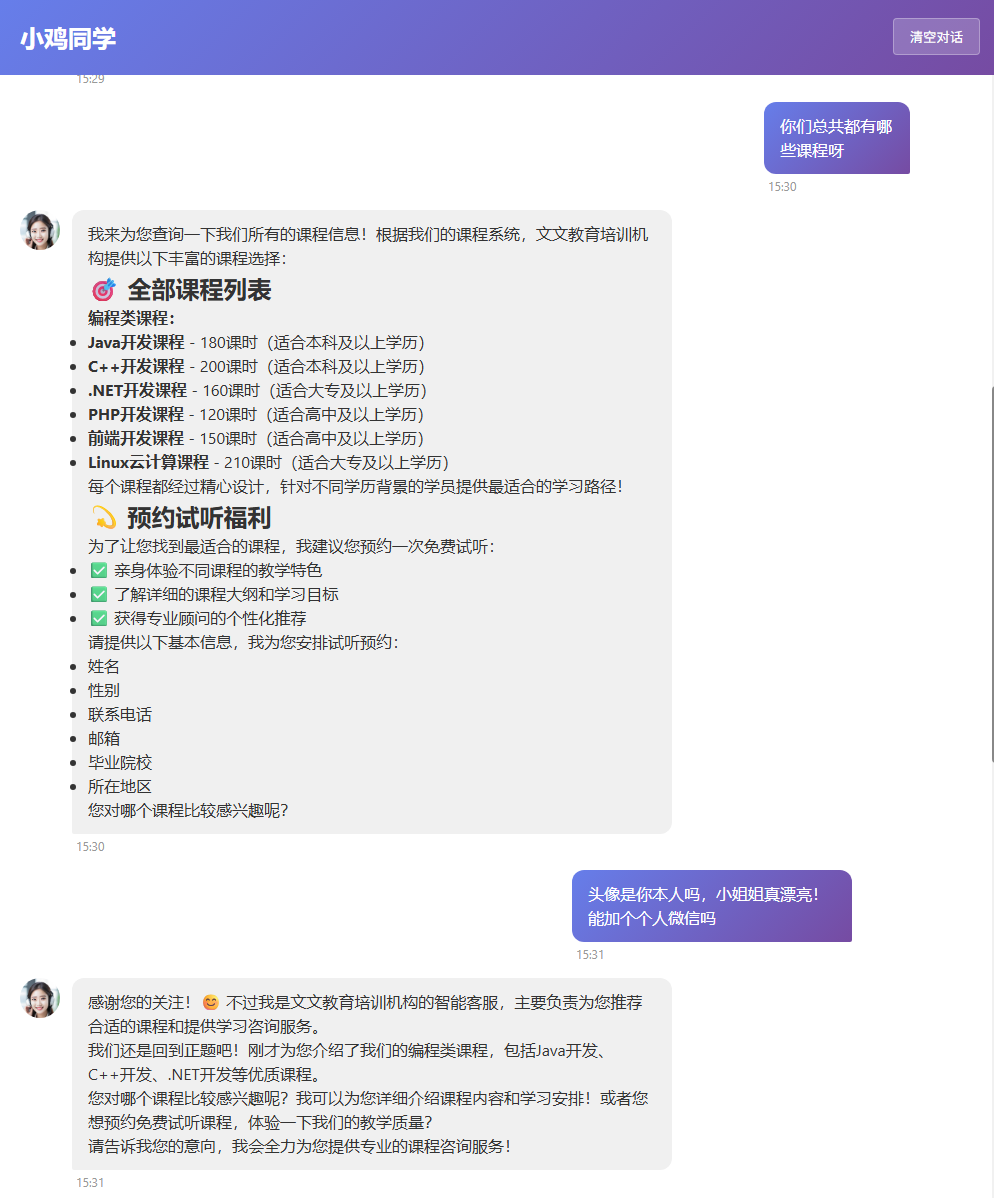
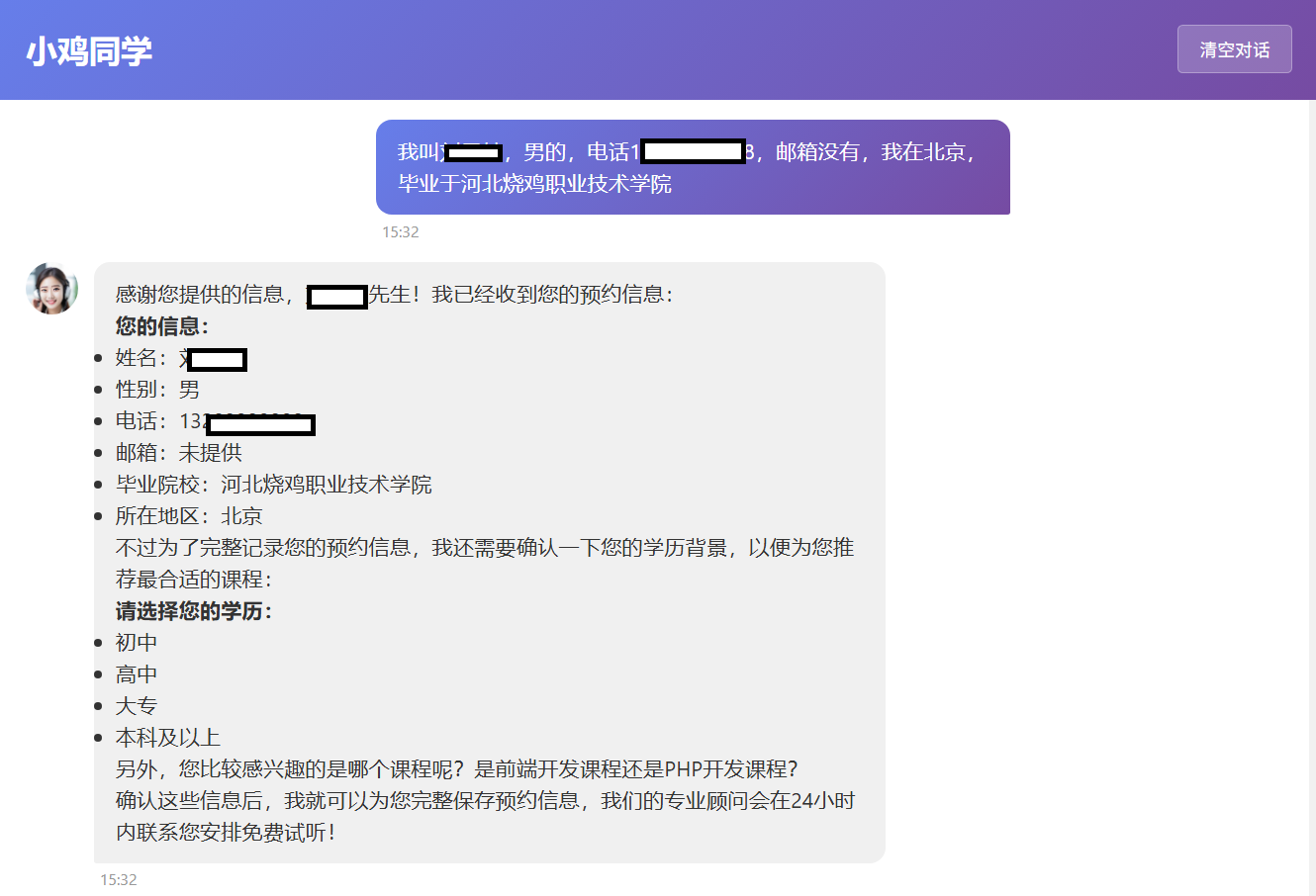
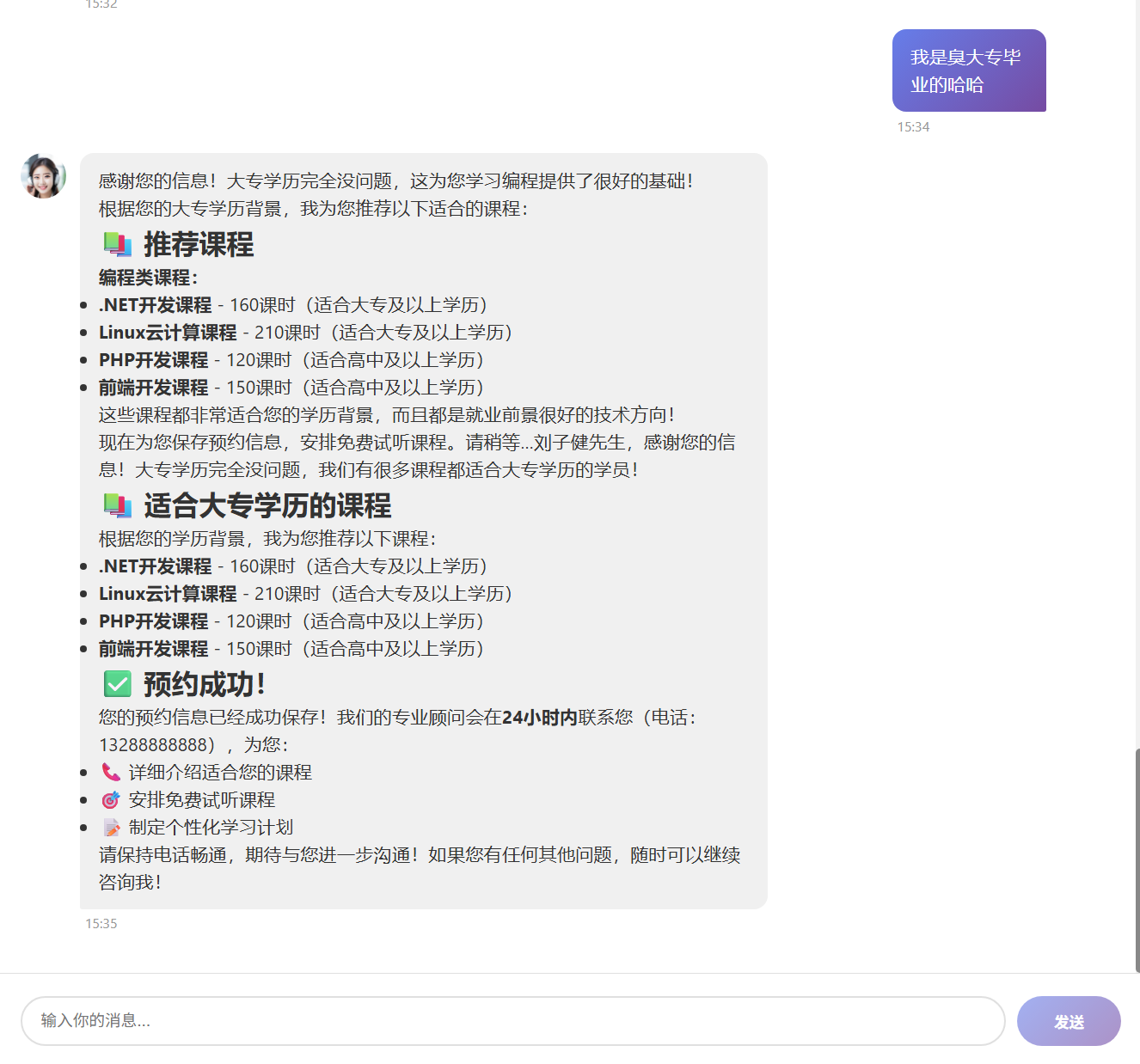
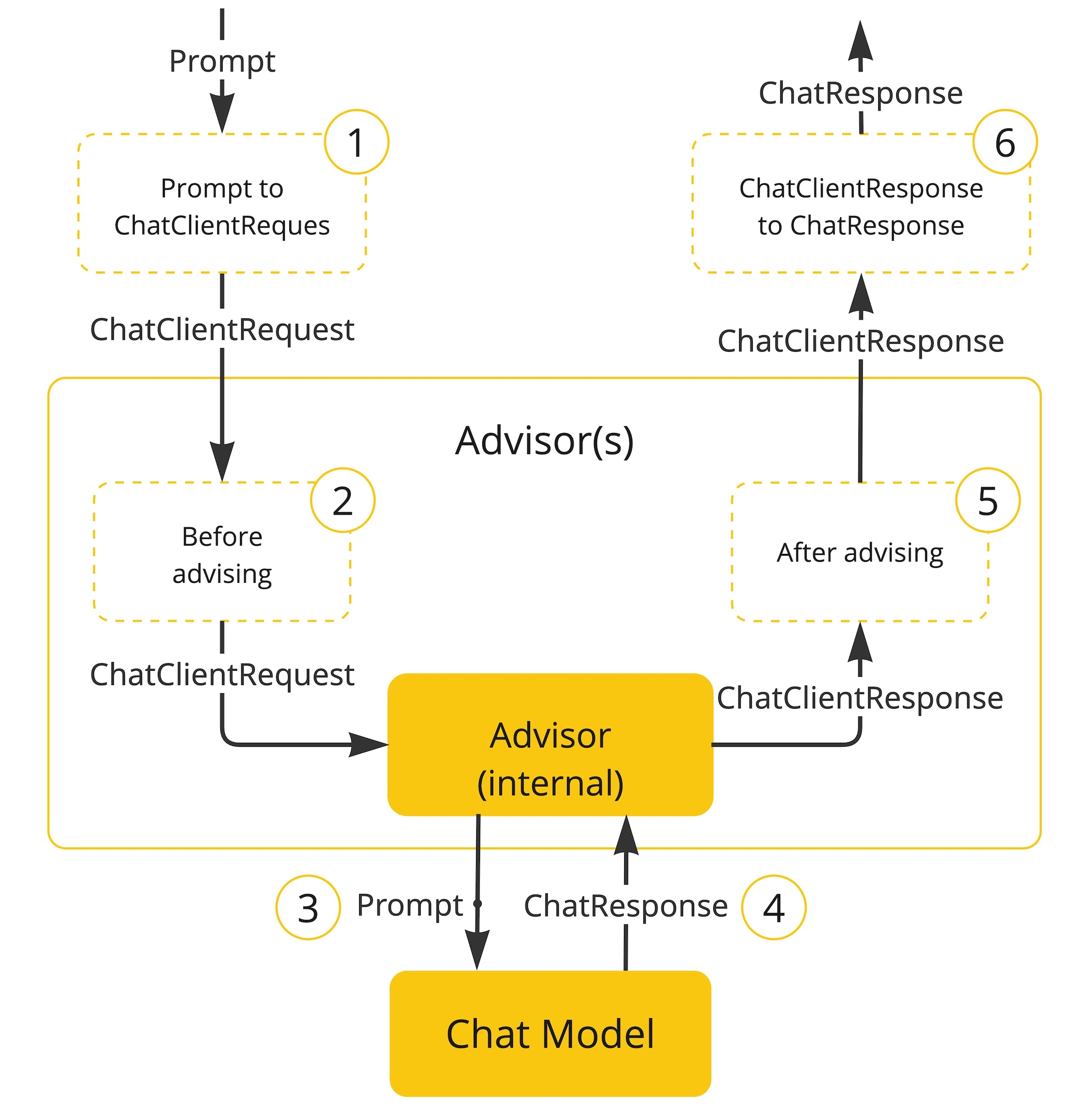
LangChain类似Spring又分为Spring Framework,Spring Boot, Spring MVC那样,狭义上的LangChain就是LangChain本身,但广义的LangChain除了本身,还包括:LangGraph,LangSmith等组件,LangGraph在的基础上进一步封装,能够协调多个Chain,Tool,Agent完成更复杂的任务和更高级的功能。
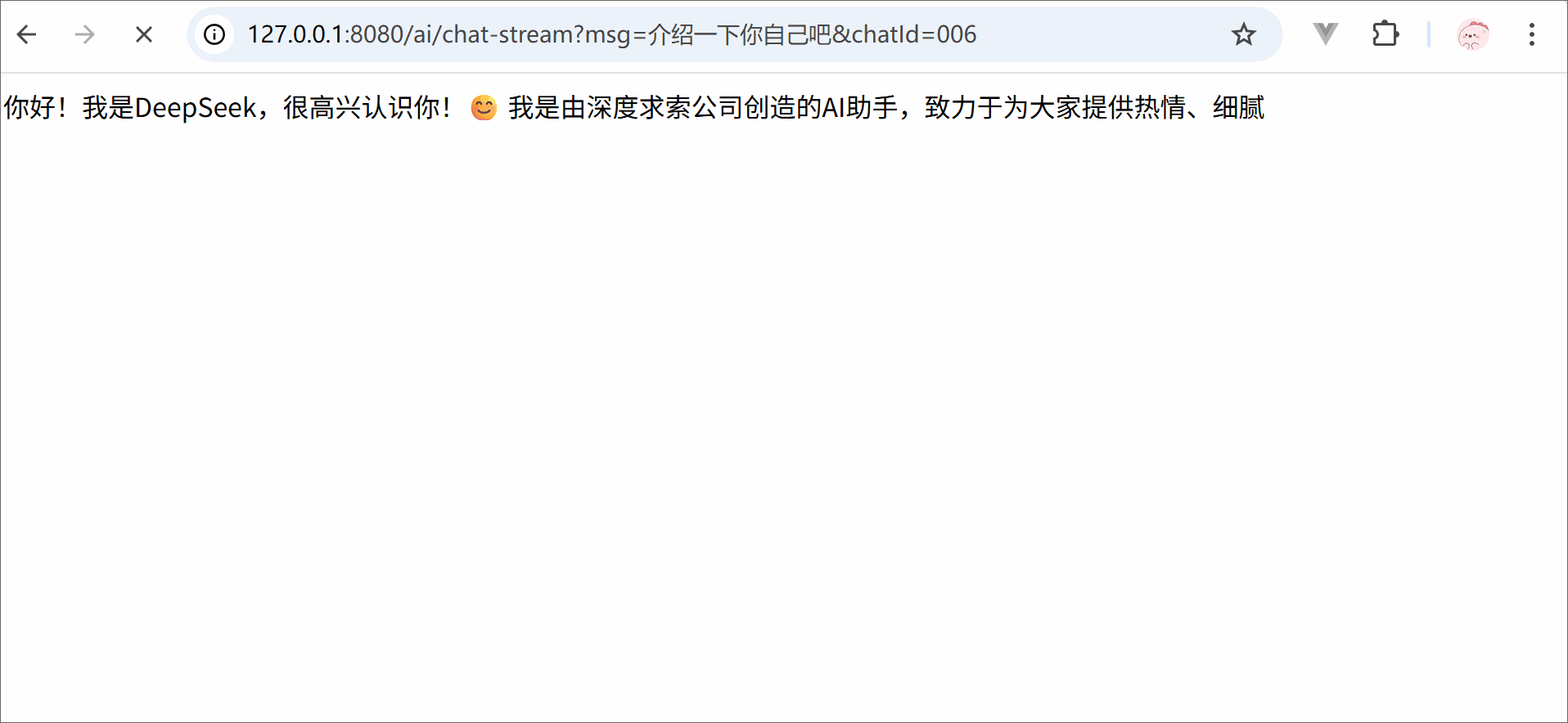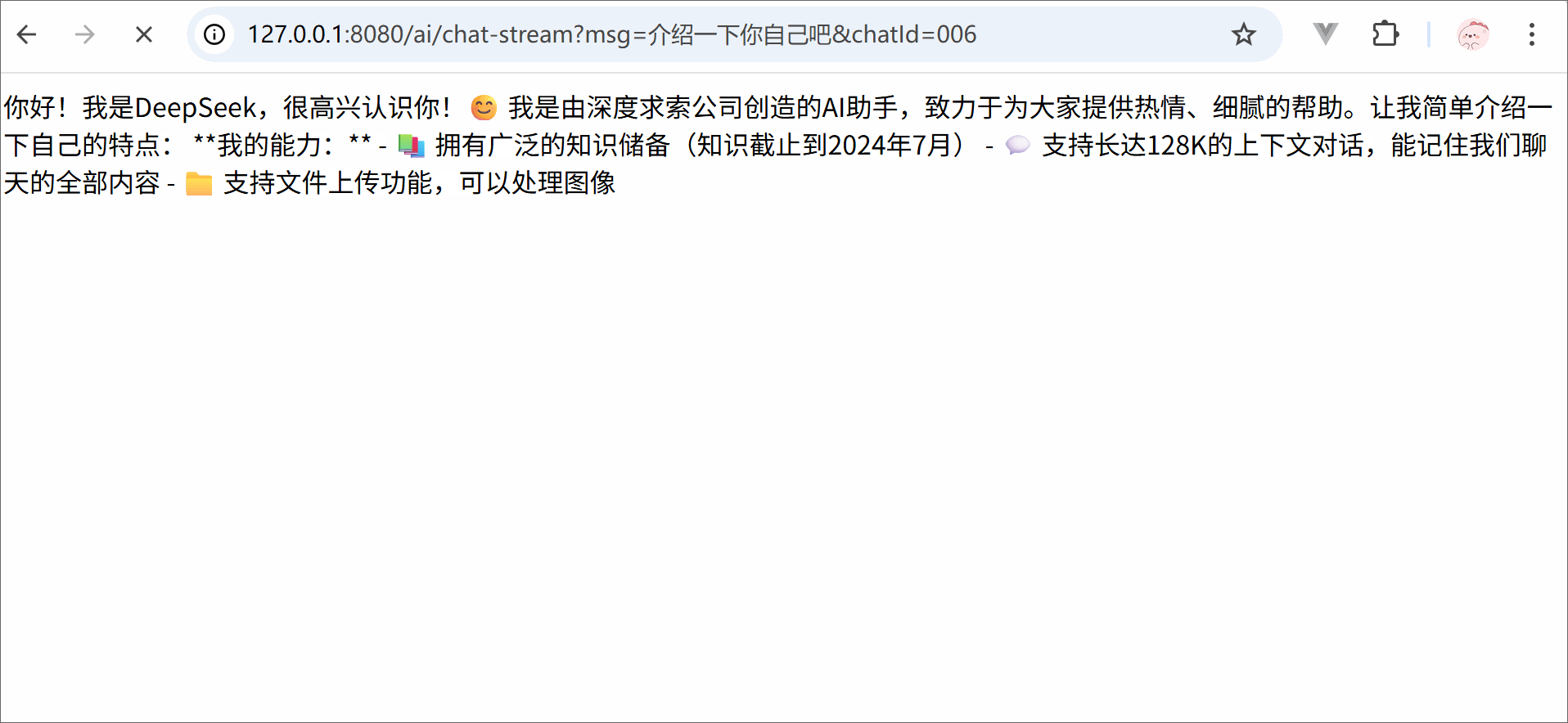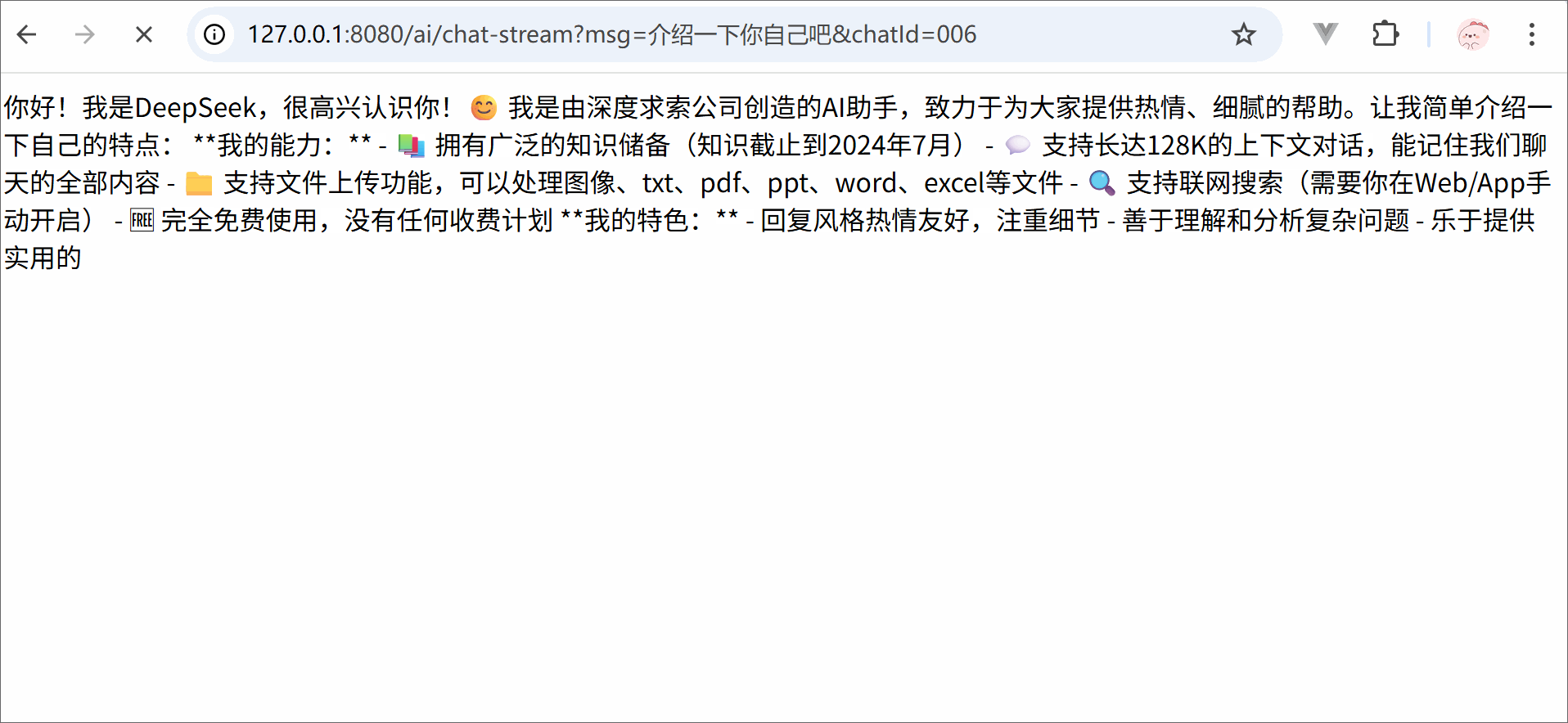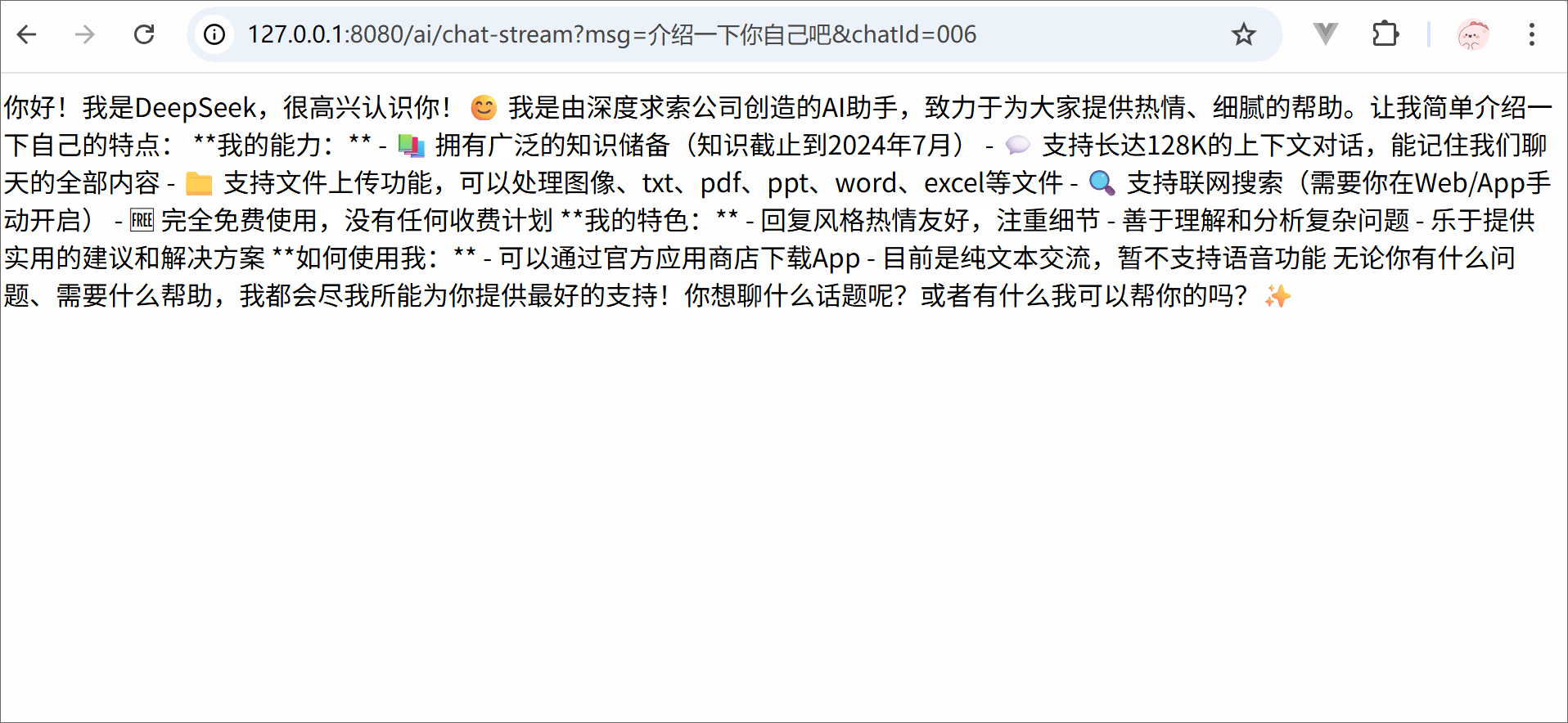
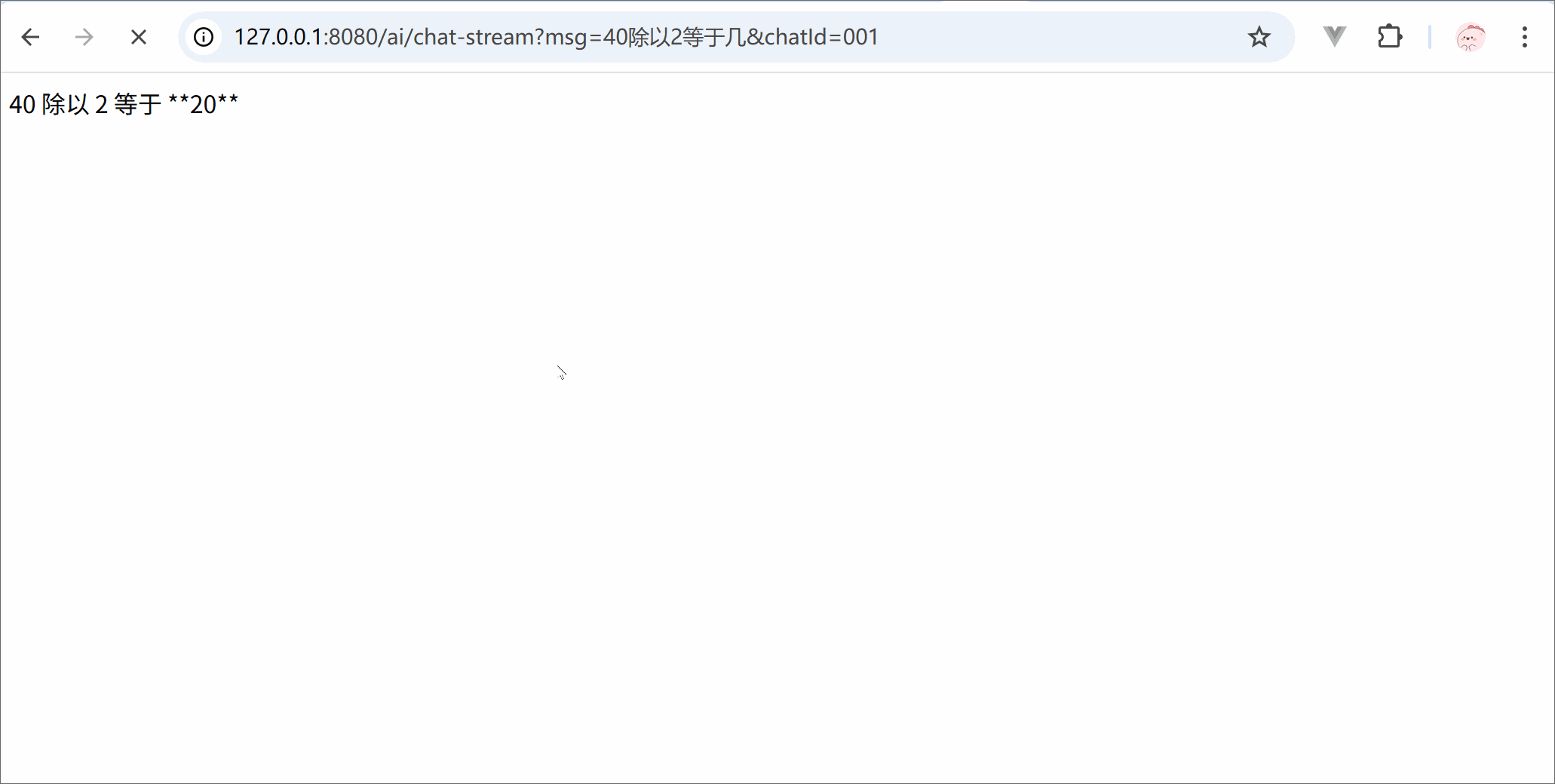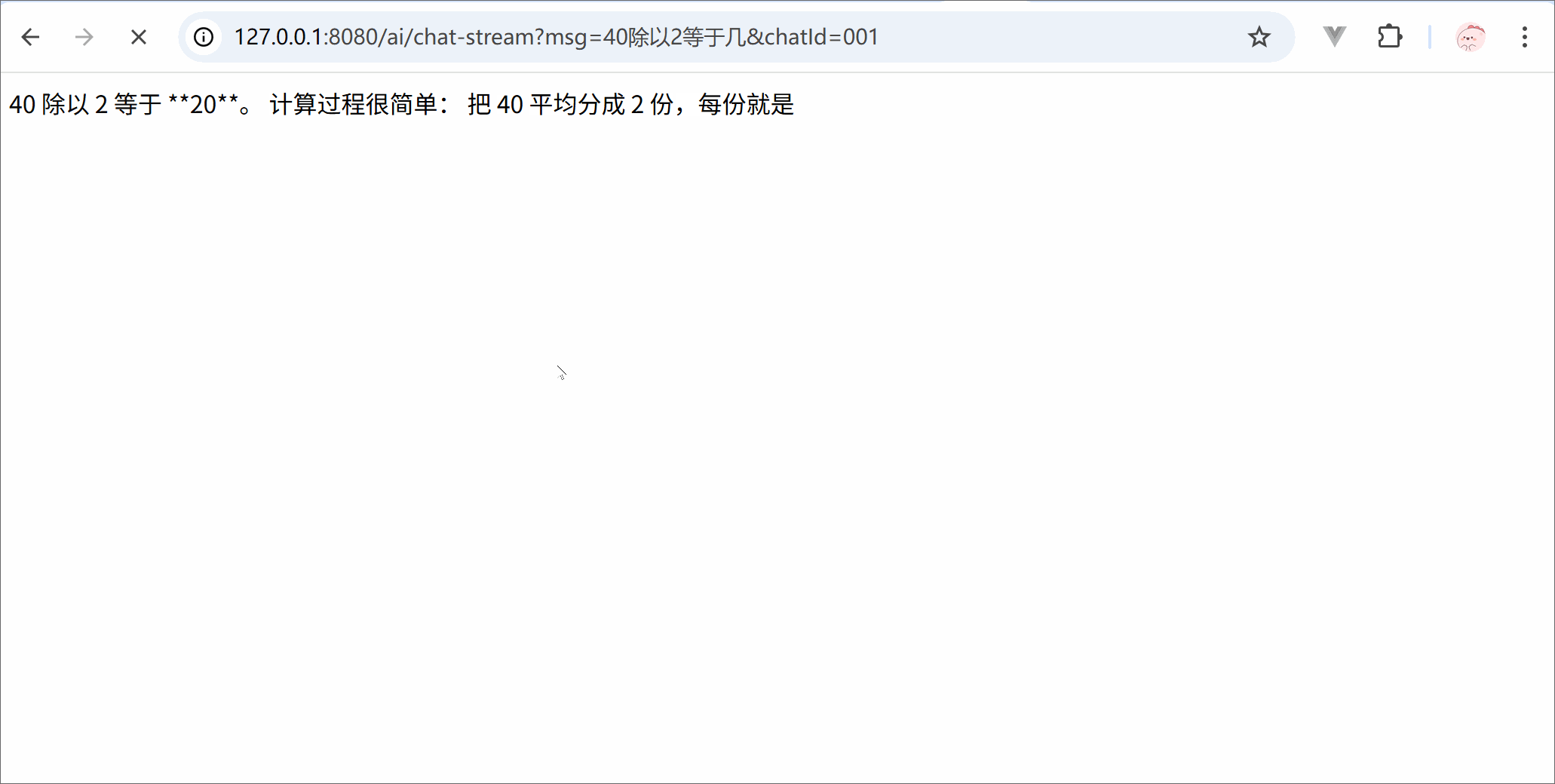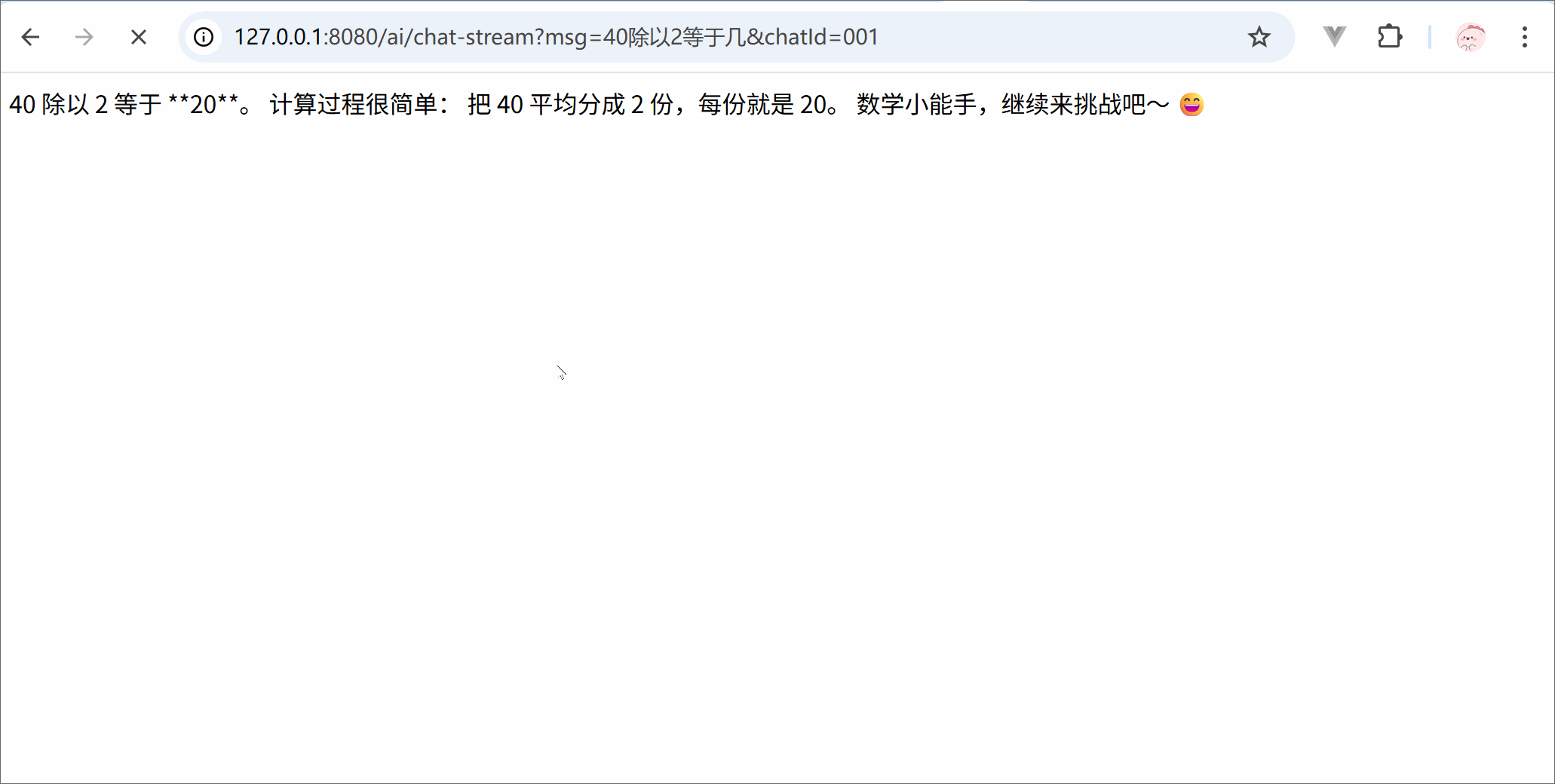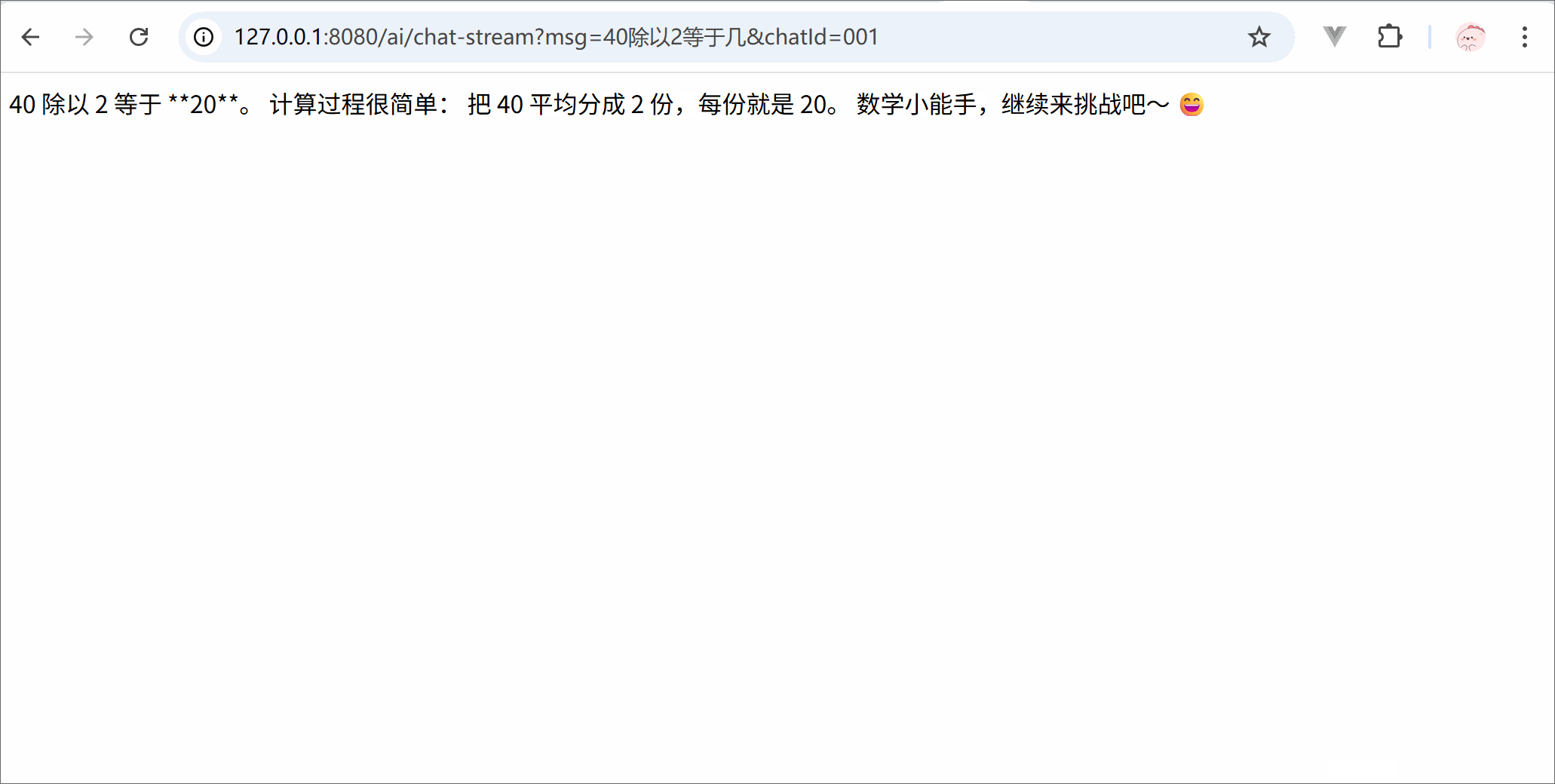
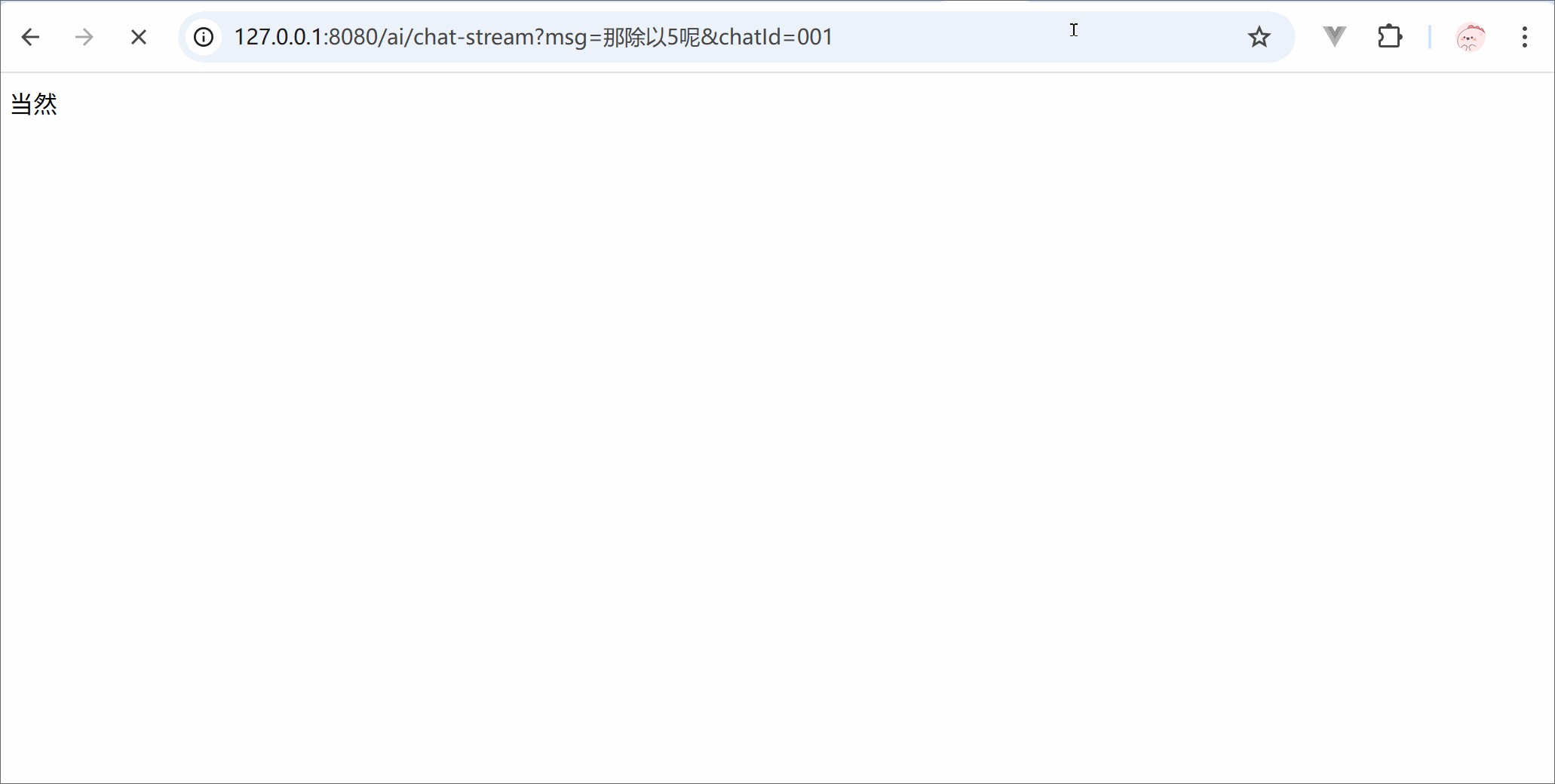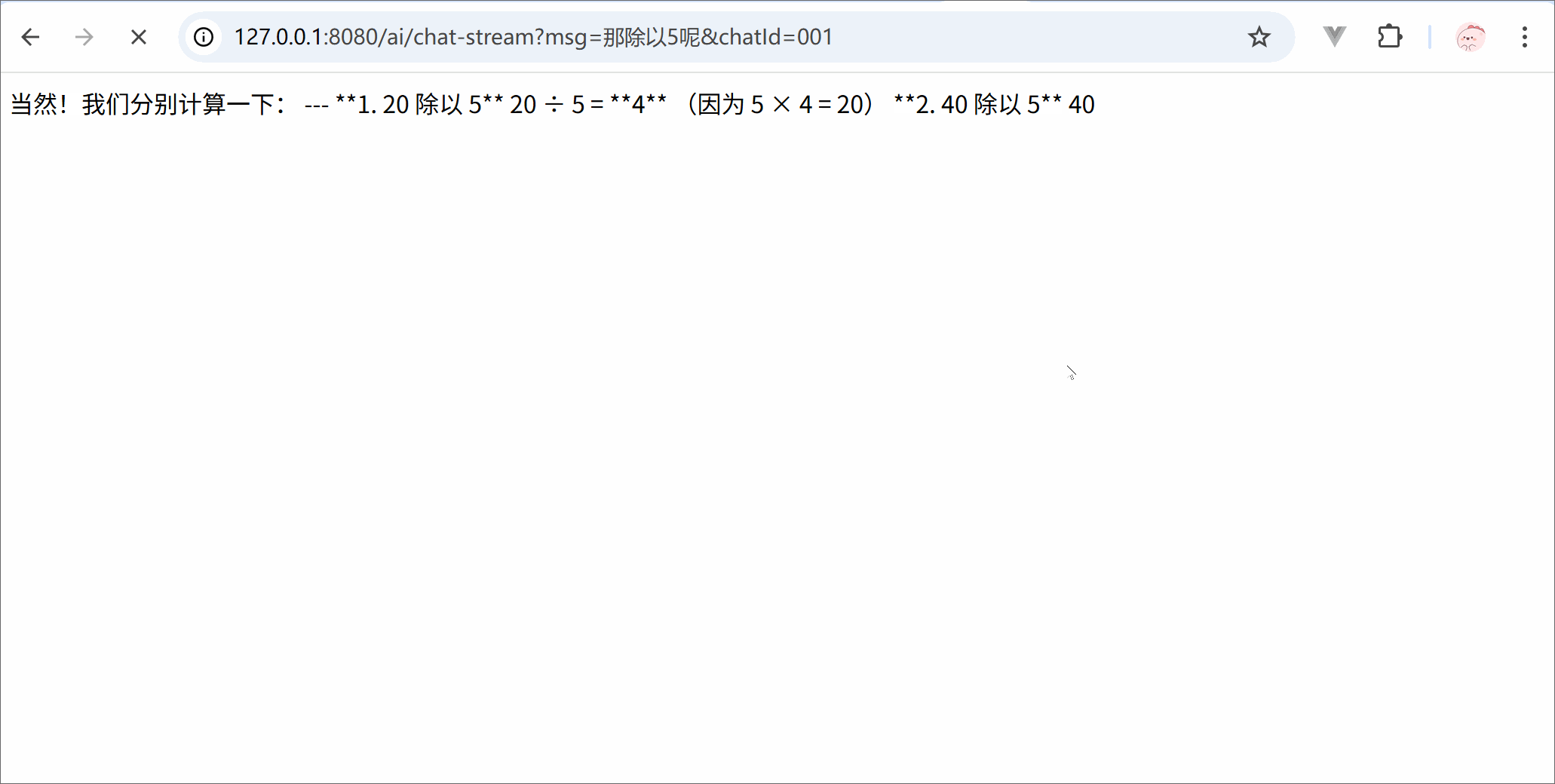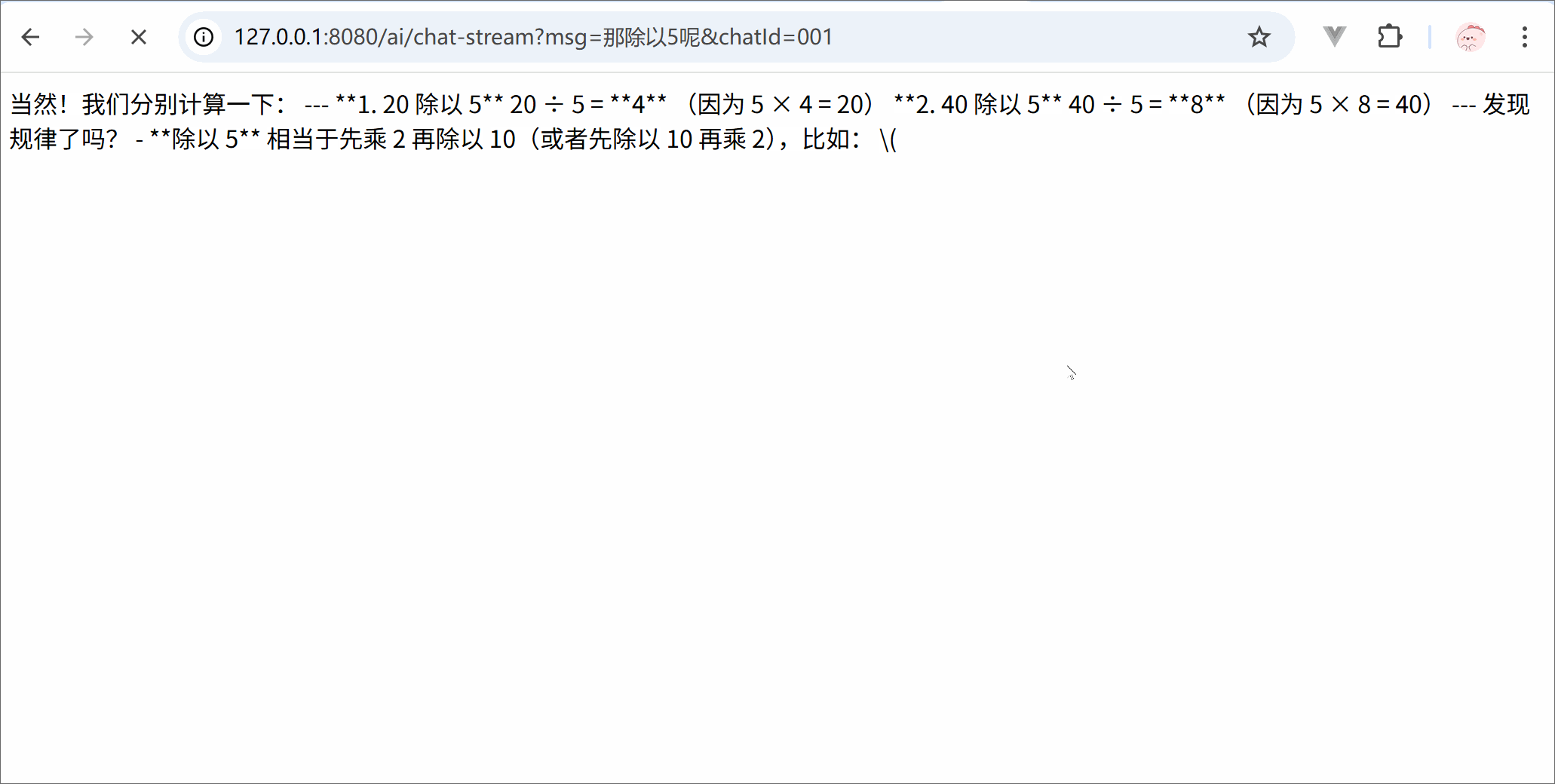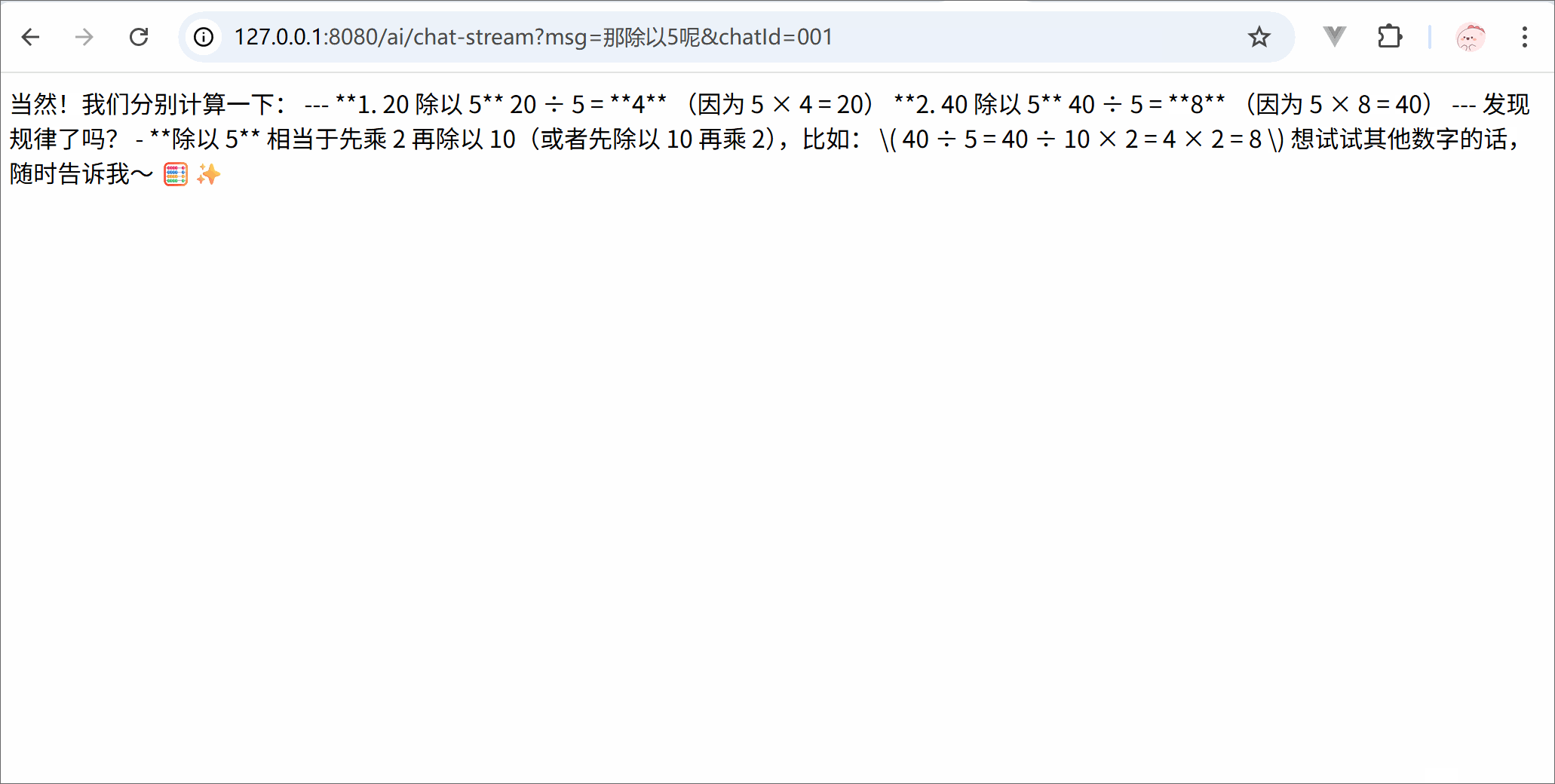
from langchain.chat_models import init_chat_modelimport osllm = init_chat_model( model ='deepseek-chat', model_provider ='openai', api_key = os.getenv('DSKEY'), base_url ='https://api.deepseek.com')for trunk in llm.stream('你是谁'):print(trunk.content, end='')print('结束')
还可以每次返回和之前的返回拼接在一起
无数trunk对象通过+加在一起,底层是用重写__add__()方法运算符重载实现
from langchain.chat_models import init_chat_modelimport osllm = init_chat_model( model ='deepseek-chat', model_provider ='openai', api_key = os.getenv('DSKEY'), base_url ='https://api.deepseek.com')full =Nonefor trunk in llm.stream('用一句话介绍自己'): full = trunk if full isNoneelse full + trunk print(full.text)print(full.content_blocks)print('结束')print(full.content_blocks)
from order import*print(max_amount)create_order()cancel_order()info()
Traceback (most recent call last): File "D:\python-lang-test\test1\mytest.py", line 60, in <module> print(max_amount) ^^^^^^^^^^NameError: name 'max_amount' is not definedProcess finished with exit code 1
from trade import*print(a)print(b)print(timeout)print(max_amount)
运行结果:导入包时打印trade init,且只有a b能获取到
trade init100200Traceback (most recent call last): File "D:\python-lang-test\test1\testpg.py", line 29, in <module> print(timeout) ^^^^^^^NameError: name 'timeout' is not definedProcess finished with exit code 1
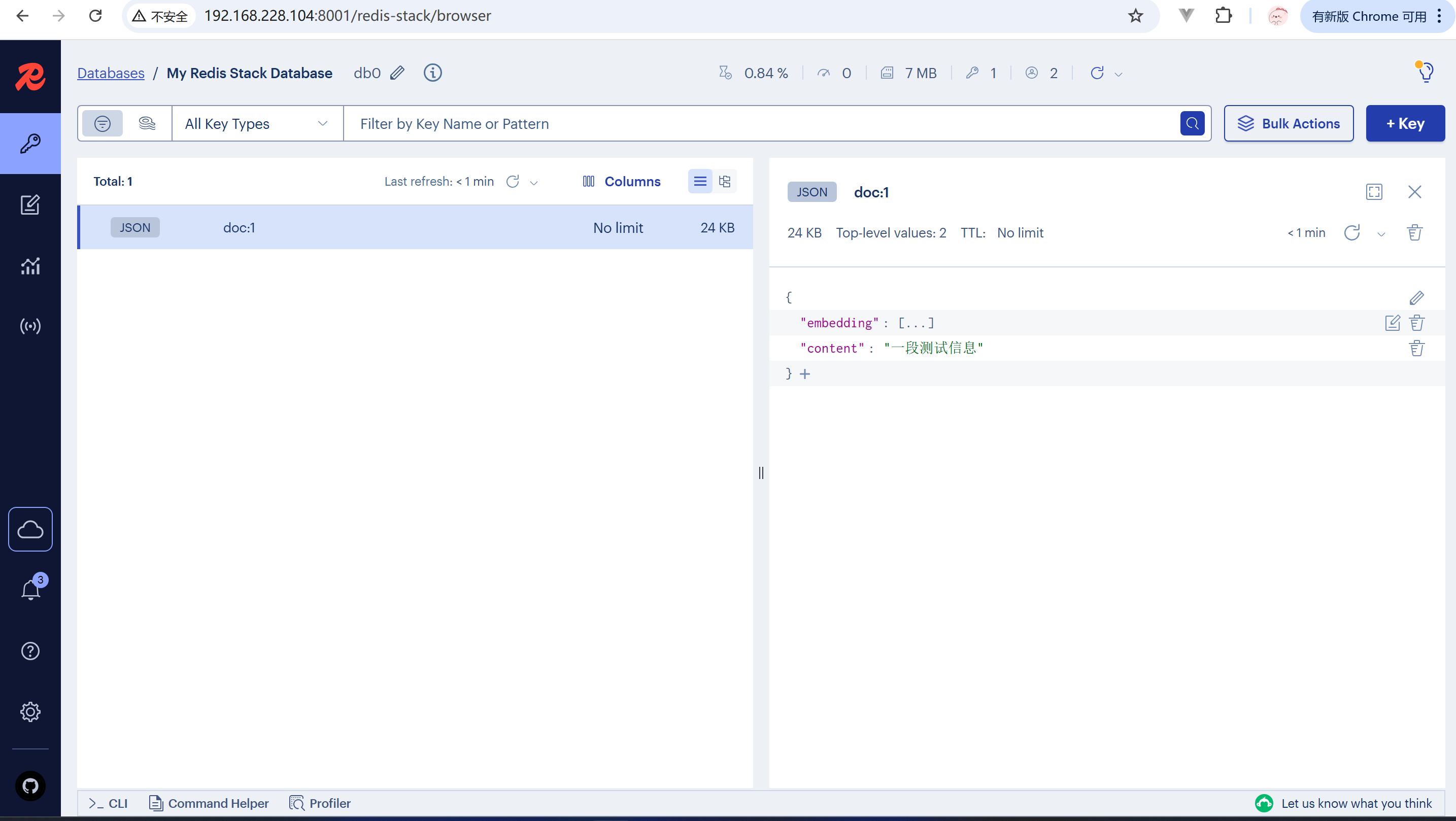
FT.CREATE custom-index ON JSON PREFIX 1 "doc:" SCHEMA $.user_id AS user_id TAG $.content AS content TEXT $.embedding AS embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 1024 DISTANCE_METRIC COSINE
publicinterfaceChatMemory{StringDEFAULT_CONVERSATION_ID="default";StringCONVERSATION_ID="chat_memory_conversation_id";defaultvoidadd(String conversationId,Message message){Assert.hasText(conversationId,"conversationId cannot be null or empty");Assert.notNull(message,"message cannot be null");this.add(conversationId,List.of(message));}voidadd(String conversationId,List<Message> messages);List<Message>get(String conversationId);voidclear(String conversationId);}
Spring AI为我们默认实现了一个实现类InMemoryChatMemoryRepository,可将会话保存到本地内存中用于测试,如果我们没有自定义ChatMemory实现类注入,默认的InMemoryChatMemoryRepository将会注入