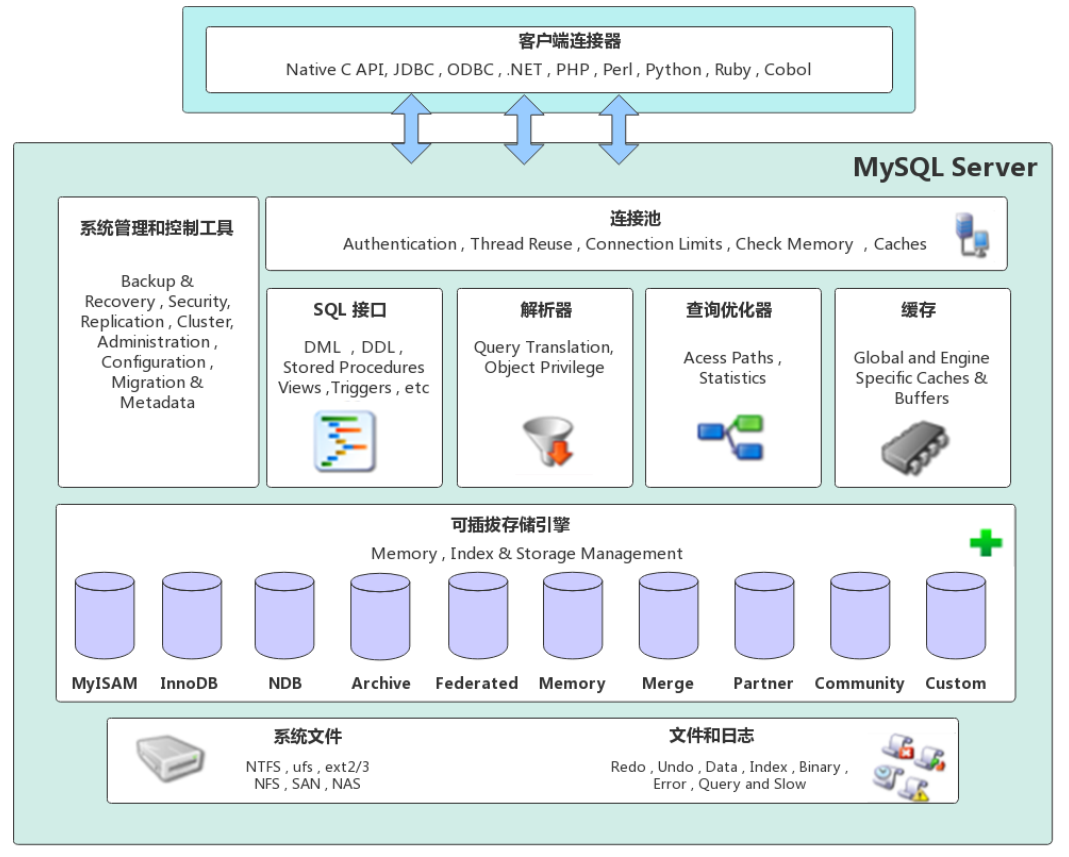
面试笔记:MySQL 相关03 – SQL语法与查询优化
感谢订阅陶其的个人博客!
SQL语法与查询优化
回目录: 《面试笔记:MySQL 相关目录》
上一篇: 《面试笔记:MySQL 相关02 – 索引》
01. 子查询与连接(join)查询
子查询:是嵌套在主查询中的查询,按“返回结果类型”和“是否依赖主查询”分类,核心是 “子结果驱动主查询”;
连接查询:是多表关联,核心是 “通过关联条件合并表数据”,按“是否保留不匹配行”分类,底层依赖驱动表和被驱动表的关联逻辑。
以下给出了4种核心子查询和5种核心连接查询,以及一种内部优化查询。
01. 标量子查询
返回单个值。
- 写法格式:子查询返回 1 行 1 列,可作为主查询的字段或条件值;
-- 示例:查询订单数最多的用户名称(子查询返回最大订单数) SELECT username FROM user WHERE user_id = (SELECT MAX(user_id) FROM order WHERE status = 1); - 性能开销:极低,仅执行 1 次子查询,结果直接代入主查询;
- 适用场景:主查询需依赖单个聚合值(如最大值、平均值)或特定单行数据。
02. 列子查询
返回单列多行。
- 写法格式:子查询返回 1 列 N 行,主查询用
IN/NOT IN/ANY/ALL匹配;-- 示例:查询有未支付订单的用户(子查询返回未支付订单的用户ID列表) SELECT username FROM user WHERE user_id IN (SELECT DISTINCT user_id FROM order WHERE status = 0); - 性能开销:中低,MySQL 5.7 + 会将其优化为 “半连接”(避免逐行匹配),子查询结果会被物化(存入临时表);
- 适用场景:主查询需匹配多个候选值(如 “在某个集合中”),子查询结果集不宜过大(建议 1 万行内)。
03. 行子查询
返回多行多列。
- 写法格式:子查询返回 N 行 N 列(通常 1-2 列),主查询用IN匹配行数据;
-- 示例:查询与“用户张三的上海地址”完全匹配的用户(返回id和city两列) SELECT username FROM user WHERE (user_id, city) IN (SELECT user_id, city FROM user_addr WHERE username = '张三' AND city = '上海'); - 性能开销:中,子查询结果集需按行匹配,建议结果集控制在 1 千行内;
- 适用场景:主查询需匹配 “多字段组合条件”(如联合主键、多维度筛选)。
04. 关联子查询
依赖主查询字段。
- 写法格式:子查询用主查询的字段作为条件(
EXISTS是典型用法),需用表别名区分;-- 示例:查询有有效订单的用户(子查询依赖主查询的user_id,找到匹配即停止) SELECT username FROM user u WHERE EXISTS (SELECT 1 FROM order o WHERE o.user_id = u.user_id AND o.status = 1); - 性能开销:中高,主查询每扫描 1 行,子查询触发 1 次(类似 “嵌套循环”);若子查询关联字段无索引,会导致全表扫描(如 10 万行主表触发 10 万次子查询);
- 适用场景:主查询需 “存在性校验”(如 “是否有相关数据”),优先用
EXISTS(找到匹配行立即停止)替代IN(需遍历全量结果集)。
05. 内连接
INNER JOIN,默认连接方式。
- 写法格式:仅保留两表中 “关联条件完全匹配” 的行(取交集),
INNER可省略;-- 示例:查询用户及其有效订单(仅返回有订单的用户和匹配的订单) SELECT u.username, o.order_no FROM user u INNER JOIN order o ON u.user_id = o.user_id -- 关联条件(必须写ON),INNER 可省略 WHERE o.status = 1; - 性能开销:低,MySQL 会自动选择 “小表作为驱动表”,若关联字段有索引,被驱动表可快速匹配(避免全表扫描);
- 适用场景:需获取多表 “交集数据”(如用户 + 关联订单、商品 + 关联分类),是业务中最常用的连接方式。
06. 左外连接
LEFT JOIN / LEFT OUTER JOIN
- 写法格式:保留左表所有行,右表无匹配时用
NULL填充,OUTER可省略;-- 示例:查询所有用户及其订单(无订单的用户也会显示,订单字段为NULL) SELECT u.username, o.order_no FROM user u LEFT JOIN order o ON u.user_id = o.user_id WHERE o.status = 1 OR o.order_no IS NULL; -- 注意:过滤右表需包含NULL - 性能开销:中低,驱动表是左表(需全扫左表),右表关联字段有索引则性能接近内连接;无索引则性能下降明显;
- 适用场景:需保留主表全量数据(如用户表),关联从表(如订单表)的可选数据(如 “统计所有用户的订单情况,包括无订单用户”)。
07. 右外连接
RIGHT JOIN / RIGHT OUTER JOIN
- 写法格式:保留右表所有行,左表无匹配时用
NULL填充,逻辑与左连接相反;-- 示例:查询所有订单及其所属用户(无匹配用户的订单也显示,用户字段为NULL) SELECT u.username, o.order_no FROM user u RIGHT JOIN order o ON u.user_id = o.user_id WHERE o.create_time > '2024-01-01'; - 性能开销:与左连接一致,驱动表是右表(需全扫右表);
- 适用场景:需保留从表全量数据(如订单表),关联主表(如用户表)的可选数据(如 “统计所有近 3 个月订单,包括已删除用户的订单”)。
08. 全外连接
FULL JOIN / FULL OUTER JOIN
- 写法格式:保留左右两表所有行,无匹配时用
NULL填充;MySQL 不直接支持FULL JOIN,需用UNION合并左连接和右连接;-- 示例:查询所有用户和所有订单的关联数据(保留双方无匹配的行) SELECT u.username, o.order_no FROM user u LEFT JOIN order o ON u.user_id = o.user_id UNION -- 去重合并 SELECT u.username, o.order_no FROM user u RIGHT JOIN order o ON u.user_id = o.user_id; - 性能开销:高,需执行两次连接 + 去重操作,数据量大时效率低;
- 适用场景:极少用,仅需 “完整保留两表所有数据” 的特殊场景(数据对账、全量统计)。
09. 交叉连接
CROSS JOIN,笛卡尔积
- 写法格式:无关联条件,两表数据完全组合(行数 = 左表行数 × 右表行数),
CROSS JOIN可省略;-- 示例:用户表(3行)和商品表(2行)交叉连接,结果为6行 SELECT u.username, p.product_name FROM user u CROSS JOIN product p; - 性能开销:极高,行数呈指数级增长(1 万行 ×1 万行 = 1 亿行),几乎不用;
- 适用场景:仅用于 “全组合场景”(如生成所有用户 + 所有商品的测试数据),必须配合
WHERE过滤(否则会撑爆内存)。
10. 半连接
半连接不是独立的查询语法,而是 MySQL 5.7 + 默认启用的对列子查询(如IN子查询)的内部优化手段,目的是减少子查询与主查询的匹配开销。
用于优化“主查询匹配子查询结果集”的场景(如IN/EXISTS列子查询)。
核心逻辑是 “只判断匹配与否,不返回子查询的完整数据”,避免逐行匹配的低效问题。
简单说:普通子查询是 “子查询返回所有结果→主查询逐行比对”,半连接是 “主查询与子查询表直接关联→找到匹配行就停止”,本质是将子查询转化为类似JOIN的关联逻辑,提升性能。
触发条件:子查询是“列子查询”(返回单列多行),且子查询表与主查询表无关联(非关联子查询),例如WHERE id IN (SELECT uid FROM t2 WHERE status=1)。
写法格式:无特殊语法,仍用普通IN/EXISTS子查询写法,MySQL 会自动触发半连接优化(可通过EXPLAIN查看type列是否有SIMPLE/HASH JOIN,而非SUBQUERY)。
-- 示例:查询有未支付订单的用户(MySQL会自动用半连接优化)
SELECT username FROM user u WHERE u.user_id IN (SELECT DISTINCT o.user_id FROM order o WHERE o.status = 0);性能开销
- 低 – 中:远优于未优化的子查询(避免子查询结果集物化后逐行匹配)。
- 优化逻辑:MySQL 会选择以下方式之一执行半连接:
- 哈希半连接:对小表(子查询表)建哈希表,主表逐行匹配哈希键(适合大表)。
- 嵌套循环半连接:小表驱动大表,找到匹配行立即停止扫描(适合小表)。
- 物化半连接:子查询结果存入临时表并建索引,主表关联临时表(适合子查询结果集较小)。
适用场景
- 主查询需判断 “字段是否在子查询结果集中”(如
IN/EXISTS)。 - 子查询表数据量适中(1 万行内最佳),且子查询有过滤条件(如
WHERE status=1),能减少结果集大小。 - 替代场景:若子查询结果集极大(10 万行 +),建议手动改写为
JOIN(半连接优化效果会下降)。
注意项:
- 半连接是 MySQL 自动优化,无需专门手动去写语法,但需知道 “
IN子查询在 5.7 + 会被优化为半连接”,避免面试官问 “IN和JOIN哪个快” 时只说表面结论。 - 实践中,若
EXPLAIN显示子查询类型为SUBQUERY(未触发半连接),可通过 “子查询加DISTINCT” 或 “改写为JOIN” 强制优化(如上述示例加DISTINCT让结果集唯一,更易触发半连接)。
总结
1. 子查询 vs 连接查询:
- 简单场景(如单值匹配、存在性校验)用子查询(写法简洁);
- 复杂多表关联(如 3 表以上、需筛选多字段)用连接查询(性能更优,易优化);
- 关联子查询尽量改写为JOIN(避免嵌套循环,如
EXISTS适合小表,JOIN适合大表)。
2. 性能优化关键:
- 连接查询:关联字段必须建索引(如
order.user_id),小表驱动大表(减少循环次数); - 子查询:避免
NOT IN(NULL值会导致结果异常),用NOT EXISTS替代; - 外连接:右表过滤条件写在
ON(关联时过滤),左表过滤条件写在WHERE(关联后过滤)。
3. Java 开发实践场景:
- 列表查询(如用户列表 + 订单数):用
LEFT JOIN+GROUP BY; - 详情查询(如订单详情 + 用户信息):用
INNER JOIN; - 存在性校验(如判断用户是否有未支付订单):用
EXISTS子查询。
02. 子查询与join性能对比
子查询与join性能对比及适用场景
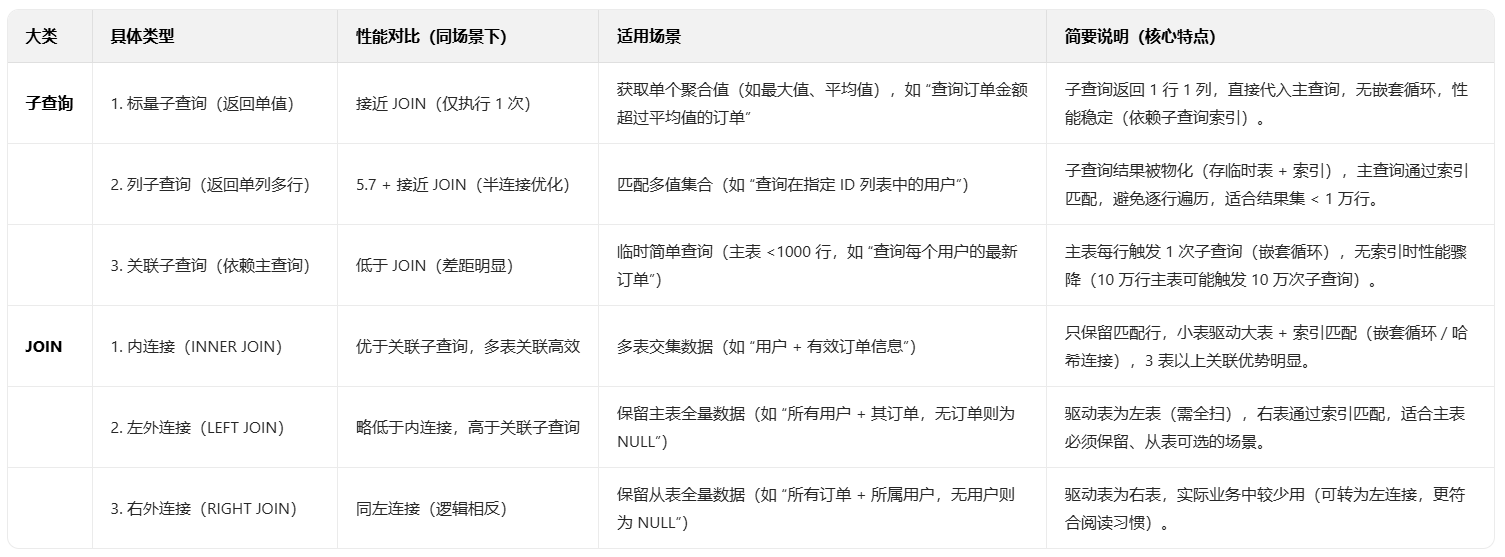
关键结论:
- 简单场景(单表校验、单值匹配)用子查询(简洁);
- 多表关联、复杂聚合、主表数据量大时,优先用 JOIN(性能更稳定)。
03. 复杂查询的执行逻辑
1. group by/having
GROUP BY 和 HAVING 是 MySQL 中用于数据分组聚合的核心语法,执行逻辑: “数据过滤→分组→聚合→二次过滤” 。
1. 核心执行逻辑
GROUP BY 的作用是 “按指定字段将数据分组”;
HAVING 则是 “对分组后的结果进行过滤”。
整体执行流程分四步,顺序不可颠倒:
1) 原始数据过滤(WHERE 子句);
- 先通过
WHERE筛选符合条件的原始数据(如WHERE status = 1过滤无效数据),减少后续处理的数据量。 - 原理:
WHERE是 “分组前过滤”,仅保留满足条件的行,不涉及聚合操作,可利用索引快速筛选(如status字段有索引时,直接定位有效行)。
2) 分组操作(GROUP BY 子句);
- 按
GROUP BY后的字段(如GROUP BY user_id)将上一步过滤后的数据分组,相同值的行被归为一组。 - 底层处理:
- 若分组字段有索引,MySQL 会直接按索引顺序分组(无需额外排序,效率高);
- 若无索引,会创建临时表存储分组数据,或对数据进行文件排序(
Using temporary或Using filesort,可通过EXPLAIN查看)。
3) 聚合计算(聚合函数);
- 对每个分组执行聚合函数(如
COUNT(*)统计行数、SUM(amount)计算总和),生成每个分组的聚合结果。 - 原理:聚合函数仅作用于分组内的数据,每个分组最终输出一行结果(包含分组字段和聚合值)。
4) 分组结果过滤(HAVING 子句);
- 用
HAVING筛选聚合后的分组(如HAVING COUNT(*) > 5保留行数超 5 的组),最终返回符合条件的分组。 - 原理:
HAVING是 “分组后过滤”,可直接使用聚合函数(因聚合结果已生成)。
2. 关键区别与实践注意
1) WHERE 与 HAVING 的核心区别
WHERE作用于分组前的原始数据,不能使用聚合函数(如WHERE COUNT(*) > 5会报错);HAVING作用于分组后的结果,可以使用聚合函数(如HAVING SUM(amount) > 1000合法)。
2) 性能优化实践(重点)
- 优先用
WHERE过滤:尽量在分组前通过WHERE减少数据量(如GROUP BY user_id HAVING user_id > 100可改为WHERE user_id > 100 GROUP BY user_id,减少分组计算量)。 - 分组字段加索引:避免临时表和文件排序(如
GROUP BY create_time时,给create_time建索引,EXPLAIN中无Using temporary即为优化生效)。 - 避免
SELECT非分组字段:MySQL 5.7+ 默认开启ONLY_FULL_GROUP_BY模式,SELECT后只能出现GROUP BY字段或聚合函数(如SELECT user_id, username, COUNT(*)若username未在GROUP BY中,会报错,需规范写法)。
3. 典型场景举例
- 统计高频用户:查询 “订单数超 10 单的用户及其总消费”,用
GROUP BY user_id HAVING COUNT(*) > 10。 - 按时间分组分析:查询 “每月订单金额超 10 万的月份”,用
GROUP BY month(create_time) HAVING SUM(amount) > 100000。
2. limit 分页
LIMIT 分页是 MySQL 中用于从查询结果中截取指定范围数据的核心语法(如 LIMIT offset, size 取第 offset + 1 到 offset + size 行),其执行逻辑围绕 “全量查询→排序→截取” 展开,实际使用中需重点关注性能问题。
1. 基本执行逻辑
LIMIT 本身不参与数据筛选,而是对 “查询 + 排序后” 的结果集进行截取,核心流程分三步:
1) 执行主查询获取原始数据
- 先执行
WHERE、JOIN等条件筛选,得到所有符合条件的行(如SELECT * FROM order WHERE status=1筛选有效订单)。
2) 排序处理(若有 ORDER BY)
- 若包含
ORDER BY(分页几乎必带,否则结果无序),MySQL 会按指定字段排序:- 若排序字段有索引(如
ORDER BY create_time且create_time有索引),直接利用索引顺序获取有序数据(效率高); - 若无索引,需在内存或磁盘中进行 “文件排序”(
Using filesort,可通过EXPLAIN查看),排序过程会消耗额外 CPU/IO。
- 若排序字段有索引(如
3) 截取指定范围数据
- 从排序后的完整结果集中,跳过前 offset 行,返回接下来的 size 行(如 LIMIT 20, 10 即跳过前 20 行,返回 10 行)。
2. 核心性能问题:offset 过大导致效率低下
当 offset 很大时(如 LIMIT 100000, 10),性能会急剧下降,原因是:
- MySQL 必须先扫描并排序前 100010 行数据,然后丢弃前 100000 行,仅返回最后 10 行,大量计算被浪费;
- 若排序无索引(依赖文件排序),会产生临时文件,进一步加剧性能损耗(10 万行数据排序可能耗时数百毫秒)。
3. 实践优化方案(重点,体现工程经验)
针对 offset 过大的问题,结合 Java 开发中常见的分页场景(如列表页、历史记录查询),优化手段如下:
1) 基于 “主键 / 唯一索引” 分页(最常用)
利用主键或唯一索引的有序性,通过 WHERE 条件直接定位起始位置,避免全量扫描:
-- 代替 LIMIT 100000, 10(低效)
SELECT * FROM order
WHERE id > 100000 -- 上一页最后一条数据的id
ORDER BY id
LIMIT 10;原理:主键索引是有序的,id > 100000 可直接定位到起始行,无需扫描前 10 万行,性能提升 10 倍以上。
2) 避免 SELECT *,只查必要字段
减少数据传输量和内存占用,尤其大表(如包含 text 字段的表):
-- 只查需要的字段(如订单号、金额、时间)
SELECT order_no, amount, create_time FROM order
WHERE id > 100000
LIMIT 10;3) 确保排序字段有索引
分页必须带 ORDER BY,且排序字段需建索引(如 create_time 索引),避免文件排序:
-- 给 create_time 建索引:CREATE INDEX idx_order_create_time ON order(create_time)
SELECT * FROM order
WHERE status=1
ORDER BY create_time DESC -- 利用索引排序
LIMIT 20, 10;4) 限制最大分页页数
业务上避免允许用户访问过大页数(如 “只显示前 100 页”),超过则提示 “数据过多,请缩小范围”(如电商平台常见做法),从源头减少大 offset 场景。
04. order by 的排序原理
MySQL 的ORDER BY用于对查询结果按指定字段排序,其核心原理是 “利用索引有序性直接取数” 或 “无索引时通过内存 / 磁盘排序”,性能差异主要源于是否能借助索引避免额外排序操作。
1. 核心排序原理
1. 利用索引排序
Using index,高效。
若排序字段(或多字段排序的前缀)有有序索引(如 B + 树索引,本身按字段值有序存储),MySQL 会直接沿索引顺序读取数据,无需额外排序,这是最优情况。
- 原理:B + 树索引的叶子节点按索引字段值升序(或降序,取决于建索引时的指定)排列,
ORDER BY字段与索引顺序一致时,可直接通过索引定位并返回有序数据,避免排序开销。 - 示例:
订单表order有索引idx_create_time(create_time升序),执行SELECT id, create_time FROM order ORDER BY create_time时,MySQL 直接沿idx_create_time的叶子节点顺序取数,无需排序(EXPLAIN中Extra列显示Using index)。
2. 文件排序
Using filesort,低效。
若排序字段无索引,或排序顺序与索引顺序不一致(如索引是升序,ORDER BY用降序且无对应降序索引),MySQL 会触发 “文件排序”:先将数据加载到内存 / 临时文件,完成排序后再返回结果。
-
执行步骤:
- 从表中读取符合
WHERE条件的行(无索引时全表扫描); - 将 “排序字段值 + 行指针(指向原始数据位置)” 存入
sort_buffer(排序缓冲区); - 若
sort_buffer装不下所有数据,会将数据分块,先在内存中排序,再写入临时文件(磁盘); - 最后合并所有分块的排序结果,得到全局有序的结果集,再通过行指针取原始数据返回。
- 从表中读取符合
-
示例:
订单表order的create_time无索引,执行SELECT * FROM order ORDER BY create_time时,MySQL 会先扫描全表,将create_time和行指针存入sort_buffer,排序后再取完整数据(EXPLAIN中Extra列显示Using filesort)。
2. 影响排序性能的关键因素
- 是否使用索引:索引排序性能远高于文件排序(毫秒级 vs 秒级,数据量大时差距更大)。
sort_buffer大小:由sort_buffer_size参数控制(默认 256KB),若数据量超过该值,会触发磁盘临时文件排序(IO 开销剧增)。- 查询字段多少:
SELECT *会导致sort_buffer中存储更多字段(增加内存占用),而只查必要字段可减少sort_buffer压力,加速排序。
3. 实践优化建议
1. 给排序字段建合适的索引:
- 单字段排序:直接给排序字段建索引(如
ORDER BY create_time→ 建idx_create_time)。 - 多字段排序(如
ORDER BY a, b DESC):建联合索引(a, b DESC),索引顺序与排序顺序完全一致(避免索引失效)。
2. 避免SELECT *,只查必要字段:
- 例如,列表页只需
id、name、create_time,则SELECT id, name, create_time ...,减少sort_buffer中存储的数据量,避免磁盘排序。
3. 控制排序数据量:
先用WHERE过滤无效数据(如WHERE status=1),减少进入排序阶段的行数(如从 100 万行滤到 1 万行,排序效率提升 100 倍)。
4. 大结果集排序用分页配合索引:
如 “按时间排序分页查询订单”,建(create_time, id)联合索引,用WHERE create_time > ?定位分页起点,避免全量排序。
4. 总结
ORDER BY的优化核心是 “能用上索引就避免文件排序”:索引排序依赖 B + 树的有序性,高效低耗;文件排序需内存 / 磁盘排序,性能差。实际开发中,通过 “建匹配索引 + 精简查询字段 + 提前过滤数据” 可显著提升排序性能,这也是处理订单列表、用户日志等需排序场景的常规优化手段。
05. 慢查询的定位与分析
MySQL 的慢查询(执行时间超过阈值的 SQL)是性能优化的核心切入点,定位与分析需结合日志工具、执行计划和业务场景。
1. 慢查询的定位
慢查询的定位:通过日志捕获目标 SQL。
定位慢查询的核心是开启慢查询日志,记录执行时间超标的 SQL,为后续分析提供依据。
1. 慢查询日志配置(5.7 版本)
通过修改my.cnf(或my.ini)配置,开启并定制日志规则:
slow_query_log = 1 # 开启慢查询日志(默认:0,关闭)
slow_query_log_file = /var/log/mysql/slow.log # 日志文件路径(需MySQL有写入权限)
long_query_time = 1 # 慢查询阈值(单位秒,默认10秒,建议生产设1-2秒)
log_queries_not_using_indexes = 1 # 记录未使用索引的查询(即使未超阈值,可选)
log_output = FILE # 日志输出方式(FILE/table,5.7默认:FILE)配置后重启 MySQL 生效,也可通过SET GLOBAL动态开启(无需重启,适合临时排查):
SET GLOBAL slow_query_log = 1;
SET GLOBAL long_query_time = 1;2. 日志收集工具
-
mysqldumpslow(自带工具):简单统计慢查询,适合快速定位高频问题:
# 查看访问次数最多的10条慢查询 mysqldumpslow -s c -t 10 /var/log/mysql/slow.log # 查看总执行时间最长的10条慢查询 mysqldumpslow -s t -t 10 /var/log/mysql/slow.log优势:轻量,适合初步筛选;
不足:无法分析趋势或复杂统计。 -
pt-query-digest(Percona 工具包):生产环境常用,可按执行时间、频率、用户等维度分析,输出 SQL 模板、平均耗时、扫描行数等关键信息:
pt-query-digest /var/log/mysql/slow.log > slow_analysis.txt优势:能识别重复 SQL(如参数不同但结构相同的查询),定位 “隐形高频慢查询”(单条耗时 0.8 秒,但每秒执行 100 次,总耗时 80 秒)。
2. 慢查询的分析
慢查询的分析:通过执行计划定位根因。
捕获慢查询后,需用EXPLAIN分析其执行逻辑,重点关注是否全表扫描、是否用对索引、是否有额外排序 / 临时表。
1. 核心分析工具:EXPLAIN
对慢查询执行EXPLAIN,查看关键字段:
type:访问类型(性能从好到差:const>eq_ref>ref>range>ALL)。ALL表示全表扫描(需优先优化)。key:实际使用的索引(NULL表示未用索引)。rows:预估扫描行数(值越大,效率越低)。Extra:额外信息(关键警告:Using filesort(需排序且无索引)、Using temporary(需创建临时表)、Using where;Using filesort(全表扫描后排序,性能极差))。
2. 常见慢查询原因及分析(结合EXPLAIN)
- 全表扫描(
type=ALL,key=NULL):- 原因:查询条件无索引(如:
WHERE status=1但status无索引),或索引失效(如:WHERE name LIKE '%abc'左模糊匹配导致索引失效)。
- 原因:查询条件无索引(如:
JOIN关联无索引(rows极大):- 原因:被驱动表的关联字段无索引(如
t1 JOIN t2 ON t2.uid = t1.id,t2.uid无索引),导致被驱动表全表扫描。
- 原因:被驱动表的关联字段无索引(如
- 排序无索引(
Extra=Using filesort):- 原因:
ORDER BY字段无索引,或排序顺序与索引不一致(如索引是create_time ASC,但查询用ORDER BY create_time DESC且无降序索引)。
- 原因:
- 子查询嵌套(
type=DEPENDENT SUBQUERY):- 原因:关联子查询导致主表每行触发一次子查询(如
WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.uid = t1.id)),无索引时性能骤降。
- 原因:关联子查询导致主表每行触发一次子查询(如
3. 慢查询的优化方向
分析出原因后,针对性优化:
1. 加索引:
- 为查询条件、
JOIN关联字段、排序字段建索引(如:WHERE+ORDER BY字段建联合索引,如idx_status_create_time (status, create_time))。
2. 改写 SQL:
- 子查询改
JOIN(如关联子查询改写为INNER JOIN,减少嵌套循环); - 避免左模糊匹配(
LIKE '%abc'改为LIKE 'abc%',或用全文索引); - 大分页改范围查询(
LIMIT 100000,10改为WHERE id > 100000 LIMIT 10)。
3. 控制数据量:
- 用
WHERE提前过滤无效数据(如WHERE create_time > '2024-01-01'),减少扫描和排序行数。
4. 8.0 版本的优化
- 慢查询日志支持表存储:除文件外,可将日志写入
mysql.slow_log表(log_output = TABLE),支持 SQL 查询分析(如按时间范围统计)。 - 日志内容更丰富:新增
query_id(唯一标识)、rows_affected等字段,方便关联性能模式(Performance Schema)数据。 - 动态调整更灵活:
long_query_time支持小数(如 0.5 秒),且修改后立即生效(无需重启连接)。
5. 总结
慢查询定位与分析的核心流程是:开启日志捕获 → 工具统计筛选 → EXPLAIN分析执行计划 → 针对性优化(索引 / 改写 SQL)。
实践中,需结合业务场景(如订单表慢查询多与user_id、create_time索引相关),优先解决 “高频 + 高耗时” 的慢查询。
06. 复杂SQL的拆分与改写
大表分页优化:延迟关联、书签分页。
MySQL 大表分页是业务中高频痛点(如订单列表、日志查询),普通LIMIT offset, size在offset较大时(如LIMIT 100000,10)性能极差:因 MySQL 需扫描前 10 万行再丢弃,仅取最后 10 行,IO 开销剧增。
复杂 SQL 拆分与改写的核心思路是减少无效扫描行数,常用优化手段包括延迟关联、书签分页。
1. 普通分页的性能瓶颈
普通分页 SQL 示例(订单表order,按create_time逆序):
SELECT * FROM `order` ORDER BY create_time DESC LIMIT 100000, 10;问题:当offset=100000时,MySQL 需先遍历索引找到第 10 万行的位置(即使有create_time索引),再回表读取 10 行数据,前 10 万行的扫描属于无效开销,数据量越大越慢。
2. 关键优化方法
1. 延迟关联(延迟回表)
概念:先通过覆盖索引获取目标数据的主键(或唯一键),再关联原表获取完整字段,避免 “早期回表” 带来的大量 IO。
原理:利用索引的 “覆盖查询” 特性(只查主键,无需回表)快速定位目标行,再通过主键关联原表取数,减少扫描和回表的数据量。
优化后 SQL 示例:
-- 子查询用索引获取主键(覆盖索引,无需回表)
SELECT o.*
FROM `order` o
JOIN (SELECT id FROM `order` ORDER BY create_time DESC LIMIT 100000, 10) tmp
ON o.id = tmp.id;- 优势:子查询仅扫描索引获取id(轻量),关联原表时仅取 10 行完整数据,性能比普通分页提升 5-10 倍(10 万 + offset 场景)。
- 适用场景:需展示完整字段、支持任意跳页(如第 100 页、第 200 页)的列表。
2. 书签分页(游标分页 / 键集分页)
概念:用 “上一页最后一条记录的唯一标识”(书签,如id或create_time+id)作为条件,替代offset直接定位下一页起点,完全避免无效扫描。
原理:利用主键 / 唯一索引的有序性,通过WHERE条件跳过前面数据,直接从书签位置取数。
优化后 SQL 示例:假设上一页最后一条记录的create_time='2024-01-01 10:00:00'、id=100000,下一页查询:
SELECT *
FROM `order`
WHERE create_time < '2024-01-01 10:00:00'
OR (create_time = '2024-01-01 10:00:00' AND id < 100000)
ORDER BY create_time DESC, id DESC
LIMIT 10;- 关键:用
create_time+id作为书签(create_time可能重复,需加id保证唯一性),通过索引直接定位,无offset开销。 - 优势:性能极致(无论翻多少页,扫描行数固定为
LIMIT size); - 局限:不支持 “跳页”(如直接到第 100 页),仅适合 “上一页 / 下一页”“加载更多” 场景(APP / 移动端常用)。
3. 覆盖索引分页
覆盖索引分页:若查询字段(如id, order_no, create_time)全部包含在索引中,直接用索引查询,无需回表:
-- 索引`idx_create_time_order_no (create_time DESC, order_no, id)`覆盖所有查询字段
SELECT id, order_no, create_time
FROM `order`
ORDER BY create_time DESC
LIMIT 100000, 10;4. 限制最大 Offset
业务上禁止offset超过阈值(如 10000),引导用户通过筛选条件(如 “按时间范围筛选”)缩小数据范围,避免大 offset 查询。
5. 分表分页
超大规模表(亿级)需水平分表(如按create_time分表),分页时先定位分表,再在分表内分页,避免跨表扫描。
3. 总结
大表分页优化的核心是 “用索引定位替代无效扫描”:
- 需支持跳页选延迟关联,通过覆盖索引减少回表;
- 移动端 / 加载更多选书签分页,用唯一键直接定位;
- 极致性能选覆盖索引分页,避免回表开销。
07. JOIN优化
小表驱动大表、 避免 cross join。
1. JOIN 优化的核心逻辑
MySQL 中 JOIN 的底层实现以Nested Loop Join(嵌套循环连接)为主:外层循环遍历 “驱动表” 的数据,内层循环用驱动表的字段去 “被驱动表” 中匹配数据。。就像Java里的双层for循环。
优化的核心是减少外层循环次数 + 降低内层匹配成本,这也是 “小表驱动大表” 的原理基础。
2. 优化1:小表驱动大表
1. 原理
“小表” 指参与 JOIN 的数据集更小的表(而非物理表大小)。
用小表做驱动表(外层循环),大表做被驱动表(内层循环),可显著减少外层循环次数,从而降低整体 IO 和匹配开销。
- 举例:小表有 100 行,大表有 100 万行
- 小表驱动大表:外层循环 100 次,内层每次匹配大表 → 总匹配 100 次;
- 大表驱动小表:外层循环 100 万次,内层每次匹配小表 → 总匹配 100 万次;
- 性能差异一目了然。
2. 实践判断与示例
- 如何判断 “小表”:
- 通过
EXPLAIN看rows字段(预估扫描行数),行数少的就是 “小表”; - 或业务逻辑中明确数据量更小的表(如字典表、配置表)。
- 通过
- SQL 示例(用户表
user是小表,订单表order是大表):
-- 推荐:小表user驱动大表order(INNER JOIN中MySQL会自动优化,但LEFT JOIN需显式控制)
SELECT u.username, o.order_no
FROM user u
INNER JOIN `order` o ON u.id = o.user_id;
-- LEFT JOIN需注意:左表是驱动表,因此左表必须是小表
SELECT u.username, o.order_no
FROM user u -- 小表放左表(驱动表)
LEFT JOIN `order` o ON u.id = o.user_id;3. 注意点
INNER JOIN:MySQL 优化器会自动选择小表作为驱动表,无需手动调整;LEFT JOIN:驱动表固定为左表,因此必须将小表放在左表位置(否则会用大表驱动小表,性能暴跌);RIGHT JOIN:驱动表固定为右表,需将小表放在右表位置(实际开发中建议用LEFT JOIN替代,更符合阅读习惯)。
3. 优化2:避免 CROSS JOIN(笛卡尔积)
1. CROSS JOIN 的危害
CROSS JOIN会返回两张表的笛卡尔积(行数 = 表 A 行数 × 表 B 行数),若表 A 有 1 万行、表 B 有 10 万行,结果会有 10 亿行,直接导致数据库 CPU/IO 打满、查询超时。
2. 常见触发场景
- 显式使用
CROSS JOIN关键字且无ON条件; JOIN时遗漏ON关联条件(如SELECT * FROM A JOIN B);WHERE条件无法过滤笛卡尔积(如关联字段值全为NULL)。
3. 如何避免
- 任何
JOIN必须加ON关联条件(即使是INNER JOIN); - 禁止显式使用无关联条件的
CROSS JOIN; - 若需关联但无直接字段,通过业务逻辑补充关联条件(如时间范围、状态过滤)。
4. 优化补充
1. 被驱动表的关联字段必须加索引
被驱动表的ON字段(如order.user_id)需建索引,否则内层循环会全表扫描,即使小表驱动大表也会很慢。
2. 避免SELECT *
只查询需要的字段,减少数据传输量(尤其大表有大字段如TEXT时)。
3. 提前过滤数据
用WHERE先过滤驱动表和被驱动表的无效数据(如WHERE o.status=1),减少参与 JOIN 的行数。
5. 总结
MySQL JOIN 优化的核心是:
- 小表驱动大表:利用嵌套循环的特性减少外层循环次数,
LEFT JOIN需手动控制驱动表; - 杜绝笛卡尔积:
JOIN必须加ON条件,避免CROSS JOIN; - 索引兜底:被驱动表的关联字段加索引,是
JOIN性能的基础保障。
08. count的性能差异
count(1)、count(*)、count(字段)
1. count 的本质
count 的本质:统计 “非 NULL 行数”。
count()是聚合函数,核心作用是统计查询结果集中符合条件的 “非 NULL 行数”,不同参数的差异在于 “统计范围” 和 “是否需要判断 NULL”,这直接决定性能。
2. 三种 count 的区别与性能对比
1. count(*)
统计所有行数(含 NULL)。
逻辑:专门用于统计表 / 结果集的总行数。
MySQL 对其有特殊优化:会优先选择最小的非聚集索引(覆盖索引)扫描,若没有则用聚集索引,避免全表扫描。
特点:包含 NULL 值(因为不判断字段,只统计行数),性能最优。
2. count(1)
统计所有行数(占位符)。
逻辑:用常量1作为占位符,统计所有行数(无论字段是否为 NULL)。
MySQL 优化器会将其与count(*)视为等价,底层执行计划完全相同。
特点:性能与count(*)几乎无差异,属于 “语法糖”。
3. count(字段)
统计字段非 NULL 的行数。
逻辑:需逐行检查该字段是否为 NULL,仅统计非 NULL 的行数。性能分两种情况:
- 字段是索引字段:用索引扫描(比全表快),但需判断
NULL; - 字段是非索引字段:全表扫描 + 判断
NULL,性能最差。
特点:性能低于count(*)/count(1),且结果可能不等于总行数(因为字段可能为 NULL)。
3. 性能排序
从快到慢:count(*) ≈ count(1) > ount(索引字段) > count(非索引字段)
关键原因:
count(*)/count(1)无需判断字段NULL,且 MySQL 会选最优索引;count(字段)需额外判断NULL,非索引字段还需全表扫描。
4. 实践建议
- 统计总行数:优先用
count(*)(语义最清晰,MySQL 优化最好),而非count(1)或count(主键); - 统计字段非
NULL行数:若需此逻辑,确保字段加索引(如count(user_name)需user_name有索引); - 避免误区:
- 认为
count(主键)更快:实际count(*)会选更小的索引,比主键索引(聚集索引)扫描更快; - 认为
count(1)比count(*)快:MySQL 优化后两者无区别,count(*)更符合语义。
- 认为
5. 总结
- 核心差异:
count(*)/count(1)统计总行数(含NULL),性能最优;count(字段)统计非NULL行数,性能较差; - 实践选择:统计总数用
count(*),统计非NULL字段用count(索引字段); - 优化关键:利用 MySQL 对
count(*)的索引优化,避免count(非索引字段)的全表扫描。
6. 扩展
统计user表email非null的总行数,email是普通索引,是SELECT COUNT(email) FROM user快,还是SELECT COUNT(*) FROM user WHERE email IS NOT NULL快?
答:基本相同,但是不推荐使用后者,推荐使用COUNT(email)。因为这个全程是索引,虽然需要索引扫描,但是后者使用了WHERE条件,同样也是需要进行索引扫描,同时还多出了一步条件过滤。同时COUNT(email)语义更明确。
09. IN和JOIN哪个快
先明确两者的底层逻辑
IN:属于 “子查询 / 值列表匹配”,本质是将子查询结果加载到内存后做匹配(或直接匹配值列表),适合 “单字段匹配” 场景;JOIN:属于 “多表关联”,底层以Nested Loop Join为主(小表驱动大表),通过关联字段索引直接匹配,适合 “多字段关联取值” 场景。
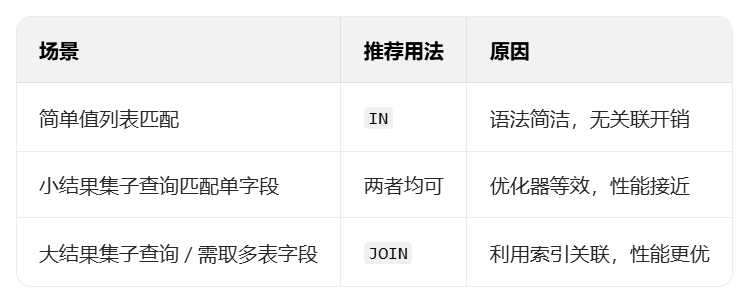
IN的优势:语法简单,适合 “单字段匹配” 的简单场景;JOIN的优势:支持多字段关联,大结果集下利用索引更高效,是复杂关联的首选。
10. MySQL的函数
MySQL 函数按功能可分为内置函数(系统提供,重点)和自定义函数(用户编写)。
1. 核心内置函数
1. 字符串函数
处理文本数据。
用于字符串拼接、截取、替换等,是业务中最常用的函数类别。
CONCAT(str1, str2,...):字符串拼接(如:拼接用户姓名和手机号:CONCAT(username, '-', mobile));SUBSTRING(str, pos, len):截取子串(如:取手机号后 4 位:SUBSTRING(mobile, 8, 4));REPLACE(str, old, new):替换字符串(如:清理内容中的特殊字符:REPLACE(content, '<', ''));LENGTH(str):获取字符串长度(如:校验用户名长度:WHERE LENGTH(username) > 6)。
实践:用户信息格式化、文本内容清洗场景高频使用。
2. 数值函数
处理数字运算。
用于数值计算、取整、进制转换等。
ROUND(num, n):四舍五入(如:金额保留 2 位小数:ROUND(amount, 2));ABS(num):取绝对值(如:计算差值的绝对值:ABS(score1 - score2));CEIL(num)/FLOOR(num):向上 / 向下取整(如:订单数量向上取整:CEIL(total/10));SUM(num)/AVG(num):求和 / 平均值(报表统计核心函数)。
实践:金额计算、数据统计场景必备。
3. 日期时间函数
处理时间数据。
用于时间获取、格式化、差值计算,是业务中仅次于字符串函数的高频函数。
NOW()/CURDATE():获取当前时间(含时分秒)/ 当前日期(仅年月日);DATE_FORMAT(date, fmt):时间格式化(如:订单时间转字符串:DATE_FORMAT(create_time, '%Y-%m-%d %H:%i:%s'));DATEDIFF(date1, date2):计算日期差值(如:用户注册天数:DATEDIFF(NOW(), register_time));DATE_ADD(date, INTERVAL expr unit):时间增减(如:计算 7 天后的日期:DATE_ADD(NOW(), INTERVAL 7 DAY))。
实践:订单时间筛选、会员有效期计算、报表时间维度统计。
4. 聚合函数
数据统计分析。
用于对多行数据进行聚合计算,需结合GROUP BY使用。
COUNT(*):统计总行数(用户数、订单数统计);SUM(field):求和(销售额、销量统计);MAX(field)/MIN(field):最大值 / 最小值(最高订单金额、最早注册时间);GROUP_CONCAT(field):分组拼接字符串(如:查询用户的所有订单号:GROUP_CONCAT(order_no))。
实践:报表系统、数据看板的核心函数。
5. 条件函数
逻辑判断。
用于实现 SQL 中的条件分支,替代复杂的WHERE判断。
IF(condition, val1, val2):简单条件判断(如:判断用户状态:IF(status=1, '正常', '禁用'));CASE WHEN:复杂条件分支(如:订单状态映射:CASE status WHEN 0 THEN '待支付' WHEN 1 THEN '已支付' ELSE '已取消' END);IFNULL(val, default):NULL值替换(如:用户昵称为空时显示默认值:IFNULL(nickname, '游客'))。
实践:查询结果格式化、动态状态展示。
6. 其他常用函数
UUID():生成唯一标识符(分布式场景临时 ID 生成);INSTR(str, substr):查找子串位置(如:判断内容是否含关键词:INSTR(content, 'MySQL') > 0);CAST(val AS type):类型转换(如:字符串转数字:CAST(score AS UNSIGNED))。
2. 面试高频考点
函数使用的性能陷阱。
1. 函数操作索引字段会导致索引失效
这是面试必问点!若对索引字段使用函数,MySQL 无法使用索引,会触发全表扫描。
- 反例:
WHERE DATE(create_time) = '2024-01-01'(对索引字段create_time用DATE()函数,索引失效); - 正例:
WHERE create_time >= '2024-01-01' AND create_time < '2024-01-02'(直接匹配字段范围,利用索引)。这个之所以能利用索引,是因为没有使用函数破坏索引的有序性,同时MySQL将给出的查询条件值'2024-01-01'和'2024-01-02'隐式的转换为了DATETIME类型,从而避免了将整个表的create_time字段转成其他类型,保证了原索引的可用性。
2. 聚合函数的NULL处理
COUNT(field)会忽略NULL值,COUNT(*)统计所有行(含NULL);SUM(field)中NULL值会被视为 0,但建议用IFNULL(field, 0)显式处理(避免语义歧义)。
3. 自定义函数的慎用场景
- 自定义函数(
CREATE FUNCTION)可实现复杂逻辑,但执行效率低(无法并行执行),且可能导致锁表,高并发场景建议用存储过程或应用层代码替代。
3. 总结
MySQL 函数是提升 SQL 灵活性的核心工具。
- 分类记忆:重点掌握字符串、日期、聚合、条件函数的常用用法;
- 性能陷阱:索引字段避免使用函数,否则索引失效;
- 实践优先:简单逻辑用内置函数,复杂逻辑优先应用层处理(避免 SQL 臃肿)。
回目录: 《面试笔记:MySQL 相关目录》
上一篇: 《面试笔记:MySQL 相关02 – 索引》
喜欢面试笔记:MySQL 相关03 – SQL语法与查询优化这篇文章吗?您可以点击浏览我的博客主页 发现更多技术分享与生活趣事。