SELECT id, employee_id, fun_first_name((select n from users u where u.id = e.uid))as first_name ,(select last_name from users u where u.id = e.uid)as last_name,EXISTS(SELECT1FROM projects WHERE manager_id = e.employee_id)AS is_managerFROM employees e;
解析并处理后得到SQL:
SELECT id, employee_id, fun_first_name((SELECT n FROM users u WHERE u.id = e.uid AND users.scope =12))AS first_name,(SELECT last_name FROM users u WHERE u.id = e.uid AND users.scope =12)AS last_name,EXISTS(SELECT1FROM projects WHERE manager_id = e.employee_id AND projects.scope =12)AS is_manager FROM employees eWHERE employees.scope =12
EXISTS (...) as ..不能写成( EXISTS (...) ) as ..,否则不会被解析为Select而是会被解析为Parenthesis,而该方法没有提供Parenthesis的解析,会导致被忽略
SELECT name FROMuser u WHERE u.math_score <(SELECTavg(score)FROM math )OR u.english_score >(SELECTavg(score)FROM english )AND(SELECT order_num FROM student )= u.order_num AND u.role_id IN(SELECT id FROM role )ANDEXISTS(SELECT*FROM customer WHERE id =6)ANDNOTEXISTS(SELECT*FROM customer WHERE id =7)
在这段SQL中,通过plainSelect.getWhere()得到的where的部分是:u.math_score < (SELECT avg(score) FROM math) OR u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) AND EXISTS (SELECT * FROM customer WHERE id = 6) AND NOT EXISTS (SELECT * FROM customer WHERE id = 7),该部分会作为参数传入Expression where中,这段复杂的where表达式中的子查询是采用拆分的方法解析到的,具体解析和追加的步骤如下:
expression.getLeftExpression() => u.math_score < (SELECT avg(score) FROM math)
expression.getRightExpression() => u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) AND EXISTS (SELECT * FROM customer WHERE id = 6) AND NOT EXISTS (SELECT * FROM customer WHERE id = 7)
第二次拆分:执行到processWhereSubSelect(expression.getLeftExpression(), whereSegment)处,将u.math_score < (SELECT avg(score) FROM math)传入processWhereSubSelect递归解析,这次执行仍然满足where instanceof FromItem == false,where instanceof BinaryExpression == true,u.math_score < (SELECT avg(score) FROM math)将被拆分为:
expression.getLeftExpression() => u.math_score
expression.getRightExpression() => (SELECT avg(score) FROM math)
接下来还会递归执行到processWhereSubSelect(expression.getLeftExpression(), whereSegment)处,将u.math_score传入processWhereSubSelect递归解析,没有满足条件的分支直接跳过,紧接着执行processWhereSubSelect(expression.getRightExpression(), whereSegment),将(SELECT avg(score) FROM math)传入processWhereSubSelect递归解析,这次执行满足where instanceof FromItem的条件,不需要拆分,执行processOtherFromItem对(SELECT avg(score) FROM math)进行过滤条件追加,至此,第一步拆分拆出来的bexpression.getLeftExpression()部分解析处理完成,第一段递归随即跳出。
expression.getLeftExpression() => u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) AND EXISTS (SELECT * FROM customer WHERE id = 6)
expression.getRightExpression() => NOT EXISTS (SELECT * FROM customer WHERE id = 7)
同理,取出expression.getLeftExpression()进行第四次拆分:
where instanceof BinaryExpression:
expression.getLeftExpression() => u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role)
expression.getRightExpression() => EXISTS (SELECT * FROM customer WHERE id = 6)
第五次拆分:
where instanceof BinaryExpression:
expression.getLeftExpression() => u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num
expression.getRightExpression() => u.role_id IN (SELECT id FROM role)
第六次拆分:
where instanceof BinaryExpression:
expression.getLeftExpression() => u.english_score > (SELECT avg(score) FROM english)
expression.getRightExpression() => (SELECT order_num FROM student) = u.order_num
第七次拆分:
where instanceof BinaryExpression:
expression.getLeftExpression() => u.english_score
expression.getRightExpression() => (SELECT avg(score) FROM english)
expression.getRightExpression() => (SELECT avg(score) FROM english)
u.english_score不满足任何分支,直接跳过,(SELECT avg(score) FROM english)是子查询,调用processOtherFromItem()处理。
处理第六次拆分的RightExpression:
where instanceof BinaryExpression:
expression.getLeftExpression() => (SELECT order_num FROM student)
expression.getRightExpression() => u.order_num
(SELECT order_num FROM student)是子查询,调用processOtherFromItem()处理,u.order_num不满足任何分支,直接跳过
处理第五次拆分的RightExpression:
where instanceof InExpression:
expression.getLeftExpression() => u.role_id
expression.getRightExpression() => (SELECT id FROM role)
u.role_id不满足任何分支,直接跳过,(SELECT id FROM role),通过IN解析子查询,然后调用processOtherFromItem()处理
处理第四次拆分的RightExpression:
where instanceof ExistsExpression:
expression.getRightExpression() => (SELECT * FROM customer WHERE id = 6)
EXISTS (SELECT * FROM customer WHERE id = 6)满足where instanceof ExistsExpression的情况,提取出(SELECT * FROM customer WHERE id = 6)子查询,调用processOtherFromItem()处理
处理第三次拆分的RightExpression:
where instanceof NotExpression:
expression.getExpression() => EXISTS (SELECT * FROM customer WHERE id = 7)
先调用processWhereSubSelect()从NOT EXISTS (SELECT * FROM customer WHERE id = 7)中提取出EXISTS (SELECT * FROM customer WHERE id = 7),再走到where instanceof ExistsExpression分支提取出子查询(SELECT * FROM customer WHERE id = 7)调用processOtherFromItem()处理
至此,WHERE语句中所有需要追加条件的表都解析追加完成了,最终得到SQL如下:
SELECT name FROMuser u WHERE(u.math_score <(SELECTavg(score)FROM math WHERE math.scope =12)OR u.english_score >(SELECTavg(score)FROM english WHERE english.scope =12)AND(SELECT order_num FROM student WHERE student.scope =12)= u.order_num AND u.role_id IN(SELECT id FROM role WHERE role.scope =12)ANDEXISTS(SELECT*FROM customer WHERE id =6AND customer.scope =12)ANDNOTEXISTS(SELECT*FROM customer WHERE id =7AND customer.scope =12))ANDuser.scope =12
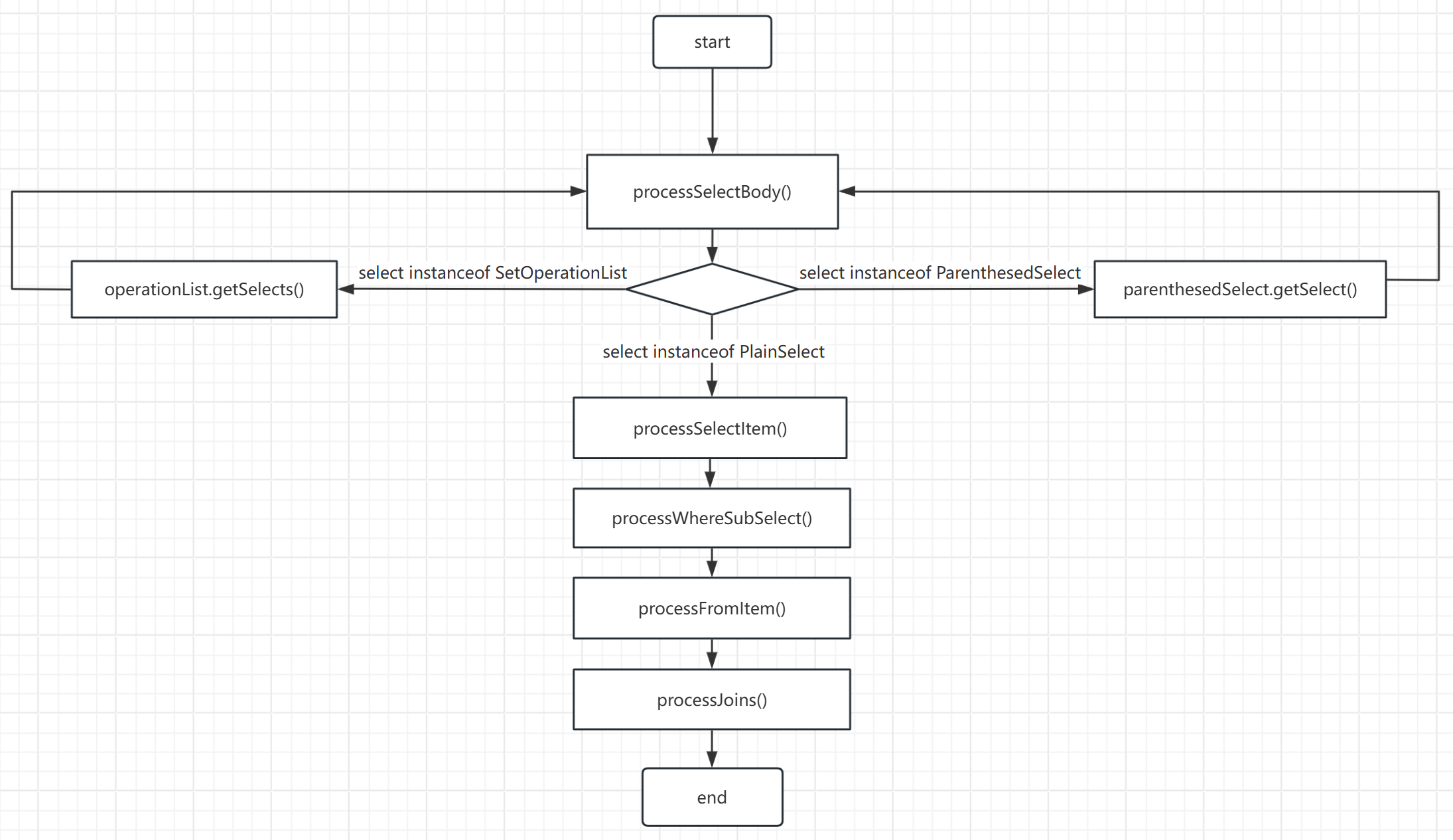
/** * 处理子查询等 */protectedvoidprocessOtherFromItem(FromItem fromItem,finalString whereSegment){// 去除括号// while (fromItem instanceof ParenthesisFromItem) {// fromItem = ((ParenthesisFromItem) fromItem).getFromItem();// }if(fromItem instanceofParenthesedSelect){Select subSelect =(Select) fromItem;processSelectBody(subSelect, whereSegment);}elseif(fromItem instanceofParenthesedFromItem){ logger.debug("Perform a subQuery, if you do not give us feedback");}}
SELECT u.id, u.name FROM userinfo u, dept d, role r WHERE u.p =1AND u.dept_id = d.id AND u.rid = r.id AND userinfo.scope =12AND dept.scope =12AND role.scope =12
3.7.2 INNER JOIN
SELECT u.id, u.name FROM userinfo u INNERJOIN dept d ON u.dept_id = d.id INNERJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u INNERJOIN dept d ON u.dept_id = d.id AND userinfo.scope =12AND dept.scope =12INNERJOIN role r ON u.rid = r.id AND role.scope =12WHERE u.p =1
3.7.3 LEFT JOIN
SELECT u.id, u.name FROM userinfo u LEFTJOIN dept d ON u.dept_id = d.id LEFTJOIN role r ON u.rid = r.id WHERE u.p =1
LEFT JOIN取的是FROM表的全部数据,是最简单的一种情况,方法开始执行时,参数mainTables中传入userinfo,joins中存放的则是dept,role两张表,局部变量mainTable和leftTable均为userinfo,因为LEFT JOIN取的是userinfo表的全部数据,因此mainTables中的userinfo就是驱动表,过滤条件加在WHERE上。LEFT JOIN的dept和role两张表都是被驱动表,过滤条件加在ON上。
SELECT u.id, u.name FROM userinfo u LEFTJOIN dept d ON u.dept_id = d.id AND dept.scope =12LEFTJOIN role r ON u.rid = r.id AND role.scope =12WHERE u.p =1AND userinfo.scope =12
3.7.4 RIGHT JOIN
SELECT u.id, u.name FROM userinfo u RIGHTJOIN dept d ON u.dept_id = d.id RIGHTJOIN role r ON u.rid = r.id WHERE u.p =1
RIGHT JOIN取的是JOIN后的表的全部数据,和LEFT JOIN正好相反,方法开始执行时,参数mainTables中传入userinfo,joins中存放的则是dept,role两张表,局部变量mainTable和leftTable均为userinfo
SELECT u.id, u.name FROM userinfo u RIGHTJOIN dept d ON u.dept_id = d.id AND userinfo.scope =12RIGHTJOIN role r ON u.rid = r.id AND dept.scope =12WHERE u.p =1AND role.scope =12
3.7.5 先INNER再RIGHT
SELECT u.id, u.name FROM userinfo u INNERJOIN dept d ON u.dept_id = d.id RIGHTJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.nameFROM userinfo uINNERJOIN dept d ON u.dept_id = d.id AND userinfo.scope =12AND dept.scope =12RIGHTJOIN role r ON u.rid = r.id AND dept.scope =12WHERE u.p =1AND role.scope =12
3.7.6 先RIGHT再INNER
SELECT u.id, u.name FROM userinfo u RIGHTJOIN dept d ON u.dept_id = d.id INNERJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u RIGHTJOIN dept d ON u.dept_id = d.id AND userinfo.scope =12INNERJOIN role r ON u.rid = r.id AND dept.scope =12AND role.scope =12WHERE u.p =1
3.7.7 先INNER再LEFT
SELECT u.id, u.name FROM userinfo u INNERJOIN dept d ON u.dept_id = d.id LEFTJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u INNERJOIN dept d ON u.dept_id = d.id AND userinfo.scope =12AND dept.scope =12LEFTJOIN role r ON u.rid = r.id AND role.scope =12WHERE u.p =1
3.7.8 先LEFT再INNER
SELECT u.id, u.name FROM userinfo u LEFTJOIN dept d ON u.dept_id = d.id INNERJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u LEFTJOIN dept d ON u.dept_id = d.id AND dept.scope =12INNERJOIN role r ON u.rid = r.id AND userinfo.scope =12AND role.scope =12WHERE u.p =1
3.7.9 先RIGHT再LEFT
SELECT u.id, u.name FROM userinfo u RIGHTJOIN dept d ON u.dept_id = d.id LEFTJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u RIGHTJOIN dept d ON u.dept_id = d.id AND userinfo.scope =12LEFTJOIN role r ON u.rid = r.id AND role.scope =12WHERE u.p =1AND dept.scope =12
3.7.10 先LEFT再RIGHT
SELECT u.id, u.name FROM userinfo u LEFTJOIN dept d ON u.dept_id = d.id RIGHTJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u LEFTJOIN dept d ON u.dept_id = d.id AND dept.scope =12RIGHTJOIN role r ON u.rid = r.id AND userinfo.scope =12WHERE u.p =1AND role.scope =12
3.7.11 FROM子查询JOIN表
LEFT JOIN:
SELECT u.id, u.name FROM(SELECT*FROM userinfo ) u LEFTJOIN dept d ON u.dept_id = d.id LEFTJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM(SELECT*FROM userinfo WHERE userinfo.scope =12) u LEFTJOIN dept d ON u.dept_id = d.id AND dept.scope =12LEFTJOIN role r ON u.rid = r.id AND role.scope =12WHERE u.p =1
RIGHT JOIN:
SELECT u.id, u.name FROM(SELECT*FROM userinfo ) u RIGHTJOIN dept d ON u.dept_id = d.id RIGHTJOIN role r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM(SELECT*FROM userinfo WHERE userinfo.scope =12) u RIGHTJOIN dept d ON u.dept_id = d.id RIGHTJOIN role r ON u.rid = r.id AND dept.scope =12WHERE u.p =1AND role.scope =12
3.7.12 FROM表JOIN子查询
RIGHT JOIN:
SELECT u.id, u.name FROM userinfo u RIGHTJOIN(SELECT*FROM dept ) d ON u.dept_id = d.id RIGHTJOIN(SELECT*FROM role ) r ON u.rid = r.id WHERE u.p =1
SELECT u.id, u.name FROM userinfo u RIGHTJOIN(SELECT*FROM dept WHERE dept.scope =12) d ON u.dept_id = d.id RIGHTJOIN(SELECT*FROM role WHERE role.scope =12) r ON u.rid = r.id WHERE u.p =1AND userinfo.scope =12
LEFT JOIN:
SELECT u.id, u.name FROM userinfo u LEFTJOIN(SELECT*FROM dept ) d ON u.dept_id = d.id LEFTJOIN(SELECT*FROM role ) r ON u.rid = r.id WHERE u.p =1
处理LEFT的情况和RIGHT是一样的,得到的SQL形式也相同:
SELECT u.id, u.name FROM userinfo u LEFTJOIN(SELECT*FROM dept WHERE dept.scope =12) d ON u.dept_id = d.id LEFTJOIN(SELECT*FROM role WHERE role.scope =12) r ON u.rid = r.id WHERE u.p =1AND userinfo.scope =12
3.7.13 FROM子查询JOIN子查询
SELECT u.id, u.name FROM(SELECT*FROM userinfo ) u RIGHTJOIN(SELECT*FROM dept ) d ON u.dept_id = d.id RIGHTJOIN(SELECT*FROM role ) r ON u.rid = r.id WHERE u.p =1
这种情况本质上和FROM表JOIN子查询是一样的
SELECT u.id, u.name FROM(SELECT*FROM userinfo WHERE userinfo.scope =12) u RIGHTJOIN(SELECT*FROM dept WHERE dept.scope =12) d ON u.dept_id = d.id RIGHTJOIN(SELECT*FROM role WHERE role.scope =12) r ON u.rid = r.id WHERE u.p =1
3.7.14 不支持的情况
processJoins()方法似乎并不是万能的,有几种我遇到的不能支持的极端情况:
1.JOIN表和JOIN子查询混用时,使用了RIGHT会导致丢掉某个表的过滤条件
以下两个是重写过的SQL,都会导致userinfo表的scope条件丢失
SELECT u.id, u.name FROM userinfo u LEFTJOIN(SELECT*FROM dept WHERE dept.scope =12) d ON u.dept_id = d.id RIGHTJOIN role r ON u.rid = r.id LEFTJOIN(SELECT*FROM job WHERE job.scope =12) j ON u.jid = j.id WHERE u.p =1AND role.scope =12
SELECT u.id, u.nameFROM userinfo uRIGHTJOIN(SELECT*FROM dept WHERE dept.scope =12) d ON u.dept_id = d.idRIGHTJOIN role r ON u.rid = r.idWHERE u.p =1AND role.scope =12
例:这是一个重写过的SQL,因为from后的表不存在(因为是子查询),在执行leftTable = mainTable == null ? joinTable时,将left join的dept表错误的作为了驱动表,导致下次right join时以dept表为基准,将dept又追加一次dept.scope = 12,实际应当以(SELECT * FROM userinfo WHERE userinfo.scope = 12)为基准,这样就导致(SELECT * FROM userinfo WHERE userinfo.scope = 12)的记录不全
SELECT u.id, u.name FROM(SELECT*FROM userinfo WHERE userinfo.scope =12) u LEFTJOIN dept d ON u.dept_id = d.id AND dept.scope =12RIGHTJOIN role r ON u.rid = r.id AND dept.scope =12WHERE u.p =1AND role.scope =12
SELECTCASEWHEN id >=90THEN(SELECT id FROM system_users WHERE parent_dept_id =9)WHEN id >=80THEN(SELECT id FROM system_users WHERE parent_dept_id =6)WHEN(SELECT id FROM system_users WHERE parent_dept_id =5)>=70THEN(SELECT id FROM system_users WHERE parent_dept_id =5)ELSE100ENDAS grade FROM system_users WHERE system_users.scope =12