## 一、概述
在 Node.js 中,`http` 模块是最核心的内置模块之一,它允许开发者快速搭建 HTTP 服务器或发起 HTTP 请求。
无论是本地调试 API,还是在生产环境中支撑一个 Web 服务,几乎所有 Node.js 项目都会直接或间接依赖 `http` 模块。
与浏览器的 `fetch` 或其他 HTTP 客户端不同,Node.js 的 `http` 模块提供了**更底层的接口**:
- 可以创建一个 **HTTP 服务器**,监听端口,接收并处理客户端请求;
- 可以作为 **HTTP 客户端**,向远程服务器发起请求;
- 提供对 **请求(IncomingMessage)** 和 **响应(ServerResponse)** 的底层控制权,例如分块传输、流式处理等。
由于其是底层 API,`http` 模块通常作为 Express、Koa、NestJS 等框架的基础,但理解它的工作原理仍然非常重要。
## 二、HTTP 服务器
### 2.1 创建服务器
使用 `http.createServer` 可以快速创建一个 HTTP 服务器:
```javascript
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, world!');
});
```
- **参数**:
`createServer` 接收一个回调函数 `(req, res)`,当有新的请求进入时,这个回调就会被执行。
- `req` 是 `http.IncomingMessage` 实例,表示请求对象。
- `res` 是 `http.ServerResponse` 实例,表示响应对象。
- **返回值**:
返回一个 `http.Server` 实例,它是一个事件驱动的对象,后续可以通过 `listen` 方法启动监听。
这种模式非常适合快速开发 Demo 或简单服务。但在复杂应用中,通常会把请求处理逻辑拆分出来,避免 `createServer` 回调函数里代码过于臃肿。
------
### 2.2 端口绑定与监听
创建服务器之后,还需要调用 `server.listen` 来让它真正运行起来。这个方法告诉操作系统:“请在某个端口等待请求,并交给我处理”。
常见的用法有三种:
1. **指定端口监听(最常见)**
```javascript
server.listen(3000, () => {
console.log('Server is running at http://localhost:3000');
});
```
- 这里 `3000` 是端口号。
- 回调函数会在服务成功启动时触发。
- 省略 `hostname` 参数时,服务器会监听所有可用的网络接口(包括 `localhost` 和外网 IP)。
> 实际场景:在开发环境中,我们通常监听 `localhost:3000`;在生产环境,很多时候服务器只监听一个内部端口(如 `127.0.0.1:8080`),然后由 Nginx 或其他反向代理转发外部请求。
2. **监听本地回环地址**
```javascript
server.listen(8080, '127.0.0.1');
```
- 这样服务器只会接受来自本机的请求,不会对外暴露。
- 适用于本地开发、测试,或者只需要被同一台机器上的其他服务调用的场景。
3. **通过 UNIX 域套接字监听**(Linux/Unix 环境)
```javascript
server.listen('/tmp/server.sock');
```
- 这里 `path` 是一个文件路径,表示使用 UNIX 域套接字进行通信。
- 适用于高性能 IPC(进程间通信)或与 Nginx 的本地 socket 转发结合使用。
- 注意:需要保证路径有权限写入,否则会抛出错误。
## 三、请求对象(IncomingMessage)
当客户端发起请求时,`http.createServer` 回调中的第一个参数 `req` 就是一个 `http.IncomingMessage` 实例,它封装了请求的所有信息,包括请求方法、URL、头信息以及请求体。
### 3.1 请求方法与 URL
`req.method` 和 `req.url` 是最基础的两个属性:
```javascript
const http = require('http');
http.createServer((req, res) => {
console.log('Request Method:', req.method);
console.log('Request URL:', req.url);
res.end('Check console for request details');
}).listen(3000);
```
- **req.method**:表示 HTTP 方法,如 `GET`、`POST`、`PUT`、`DELETE` 等。
- **req.url**:表示请求的路径,包括查询参数(query string)。
> 注意:它并不是完整的 URL,通常会结合 `URL` 类或第三方库(如 `querystring`、`url`)解析参数。
**应用场景**:
- 根据 `req.method` 做不同路由处理,例如 `GET /users` 返回用户列表,`POST /users` 创建新用户。
- 使用 `req.url` 解析路径和查询参数,实现路由匹配。
------
### 3.2 请求头(Headers)
`req.headers` 是一个对象,包含客户端发送的所有 HTTP 头信息:
```javascript
console.log(req.headers['user-agent']); // 浏览器信息
console.log(req.headers['content-type']); // 请求内容类型
```
- **注意事项**:HTTP 头的键名总是小写,无论客户端怎么发送都统一小写。
- **常用头**:
- `content-type`:指示请求体类型,如 `application/json`、`application/x-www-form-urlencoded`。
- `authorization`:常用于携带 JWT 或 Token。
- `cookie`:客户端 Cookie 信息。
**应用场景**:
- 判断请求类型决定如何解析请求体;
- 提取鉴权信息进行身份验证。
------
### 3.3 请求体(Body)处理
对于 `POST`、`PUT` 等方法,请求体可能包含数据。Node.js HTTP 模块将请求体作为 **流(Stream)** 处理,而不是一次性读取。
```javascript
let body = '';
req.on('data', chunk => {
body += chunk; // 逐块累加数据
});
req.on('end', () => {
console.log('Received body:', body);
res.end('Request processed');
});
```
- **流式处理**的优势:
- 支持大文件上传,不会一次性占用大量内存;
- 可以在接收数据时就进行处理(如实时写入数据库或文件)。
- **注意事项**:
- `data` 事件可能触发多次,每次接收到的是 Buffer,需要根据 `content-type` 转换;
- `end` 事件表示整个请求体已接收完毕。
**实践建议**:
- 对于 JSON 数据,可在 `end` 中调用 `JSON.parse`;
- 对于文件上传,通常结合第三方库(如 `multer`、`busboy`)处理 multipart/form-data。
------
### 3.4 高级属性
- `req.httpVersion`:请求使用的 HTTP 版本(如 `1.1`、`2.0`)。
- `req.socket`:底层 TCP 套接字,可以获取客户端 IP、端口等。
- `req.rawHeaders`:原始头信息数组,保持客户端发送顺序。
**应用场景**:
- 日志记录客户端 IP 或请求来源;
- 在代理或负载均衡场景下,分析原始请求头。
## 四、响应对象(ServerResponse)
`http.createServer` 回调函数的第二个参数 `res` 是一个 `http.ServerResponse` 实例,用于构建并发送 HTTP 响应。理解 `res` 的工作方式,对于正确返回数据、设置状态码和响应头至关重要。
### 4.1 设置状态码
HTTP 状态码是服务器告诉客户端请求结果的标准方式。Node.js 提供了多种方式设置状态码:
```javascript
res.statusCode = 200; // 直接赋值
res.statusMessage = 'OK'; // 可选,自定义状态消息
res.end('Response body');
```
- **statusCode**:必须设置,默认为 200(成功)。
- **statusMessage**:可选,如果不设置,Node.js 会根据 `statusCode` 自动匹配标准文本。
**常用状态码示例**:
- 200 OK:请求成功
- 301 Moved Permanently:永久重定向
- 400 Bad Request:客户端请求错误
- 404 Not Found:请求资源不存在
- 500 Internal Server Error:服务器内部错误
**场景**:
- 根据业务逻辑返回不同状态码,例如验证失败返回 401,资源未找到返回 404。
- 与前端框架结合时,状态码可以用于条件渲染或错误提示。
------
### 4.2 设置响应头
响应头用于描述响应的元信息,如内容类型、缓存策略、CORS 等。可以使用 `setHeader` 方法:
```javascript
res.setHeader('Content-Type', 'application/json');
res.setHeader('Cache-Control', 'no-cache');
res.end(JSON.stringify({ message: 'Hello World' }));
```
- **注意事项**:
- 必须在调用 `res.write()` 或 `res.end()` 前设置;
- 同一个头字段调用多次会覆盖之前的值,可使用 `res.getHeader()` 检查。
**常用响应头**:
- `Content-Type`:指定响应体类型,如 `text/plain`、`application/json`、`text/html`。
- `Content-Length`:可选,告知客户端响应体字节长度;不设置 Node.js 会自动计算。
- `Set-Cookie`:用于发送 Cookie 给客户端。
- `Access-Control-Allow-Origin`:处理跨域请求。
------
### 4.3 发送响应体
最常见的发送方式是 `res.end()`,它既可以设置响应体,也会结束响应:
```javascript
res.end('Hello World'); // 发送文本
res.end(JSON.stringify({ ok: true })); // 发送 JSON
```
- 如果响应体较大,或需要分块发送,可以使用 `res.write()` + `res.end()`:
```javascript
res.write('Part 1\n');
res.write('Part 2\n');
res.end('End');
```
- **应用场景**:
- 流式处理大文件或长轮询;
- 分块传输 HTML 模板或日志数据;
- 与 `fs.createReadStream()` 配合,实现文件下载。
------
### 4.4 响应流(Stream)与管道
由于 `res` 继承自 `Writable Stream`,可以直接将文件流或其他可读流管道输出:
```javascript
import fs from 'fs';
const stream = fs.createReadStream('./large-file.txt');
stream.pipe(res);
```
- **优势**:
- 不需要一次性将整个文件读入内存,节省内存开销;
- 对大文件传输和实时数据推送非常高效。
**注意事项**:
- 管道会自动处理 `res.end()`,无需手动调用;
- 出现错误时要监听 `error` 事件,否则可能导致服务器崩溃。
------
### 4.5 重定向
通过设置状态码和 `Location` 响应头可以实现 HTTP 重定向:
```javascript
res.statusCode = 301;
res.setHeader('Location', 'https://example.com');
res.end();
```
- **301**:永久重定向
- **302**:临时重定向
- **应用场景**:
- URL 变更后保持 SEO;
- 登录验证后跳转到目标页面。
## 五、HTTP 客户端请求
Node.js 的 `http` 模块不仅可以创建服务器,还可以向远程服务器发起 HTTP 请求。这对于实现 API 调用、微服务通信或数据抓取非常重要。核心方法是 `http.request` 和 `http.get`。
### 5.1 http.request
`http.request` 是最底层、功能最强大的客户端方法,用于发起任意 HTTP 请求(GET、POST、PUT 等)。
```javascript
import http from 'http';
const options = {
hostname: 'example.com',
port: 80,
path: '/api/data',
method: 'POST',
headers: {
'Content-Type': 'application/json'
}
};
const req = http.request(options, res => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => { console.log('Response:', data); });
});
req.on('error', err => {
console.error('Request error:', err);
});
req.write(JSON.stringify({ name: 'Node.js' }));
req.end();
```
- **options 解释**:
- `hostname`:远程服务器域名或 IP 地址
- `port`:端口,HTTP 默认 80,HTTPS 默认 443
- `path`:请求路径,可包含查询参数
- `method`:请求方法,如 `GET`、`POST`
- `headers`:自定义请求头
- **req.write() / req.end()**:
- 对于带请求体的请求(如 POST),需要调用 `req.write()` 写入数据,再用 `req.end()` 结束请求;
- 对于 GET 请求,通常直接调用 `req.end()` 即可。
**应用场景**:
- 调用第三方 API;
- 服务间数据交互;
- 上传数据到远程服务器。
**注意事项**:
- 必须监听 `error` 事件,否则出现网络错误会导致进程崩溃;
- 对于 HTTPS 请求,应使用 `https` 模块(Node.js 内置)。
------
### 5.2 http.get
`http.get` 是 `http.request` 的简化版本,专门用于发起 GET 请求,内部已经自动调用了 `req.end()`。
```javascript
http.get('http://example.com/api/data', res => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => { console.log('GET Response:', data); });
}).on('error', err => {
console.error('GET request error:', err);
});
```
- **优点**:
- 简化了 GET 请求流程,无需手动调用 `req.end()`
- 更适合快速抓取数据或读取简单 API
- **注意事项**:
- 如果需要发送请求体或自定义方法(POST、PUT 等),仍然需要使用 `http.request`;
- 需要处理数据流,否则响应体过大可能导致内存问题。
------
### 5.3 响应事件
客户端请求返回的数据是一个 **流(IncomingMessage)**,支持标准事件:
- `data`:接收响应数据块
- `end`:响应接收完毕
- `error`:网络或协议错误
- `aborted`:请求被中止
**示例:使用事件组合处理响应**
```javascript
req.on('response', res => {
console.log('Status:', res.statusCode);
res.on('data', chunk => process.stdout.write(chunk));
res.on('end', () => console.log('\nRequest finished'));
});
```
**应用场景**:
- 流式读取大文件或图片数据;
- 实时处理数据流,如日志收集或 SSE(Server-Sent Events);
- 捕获错误、超时等异常情况,提高客户端健壮性。
------
### 5.4 超时与错误处理
HTTP 客户端请求可能遇到网络延迟或远程服务器异常,因此需要设置超时:
```javascript
const req = http.request(options, res => { /* ... */ });
req.setTimeout(5000, () => {
console.error('Request timed out');
req.abort();
});
req.on('error', err => console.error('Request error:', err));
req.end();
```
- **setTimeout**:指定毫秒数超时
- **req.abort()**:超时或需要中断请求时调用
- **错误监听**:防止未捕获异常导致 Node.js 进程退出
**实践建议**:
- 为所有客户端请求设置合理超时;
- 使用 `try/catch` 或错误事件捕获,确保服务稳定;
- 对高并发请求,可结合连接池或 `keep-alive` 提升效率。
## 六、HTTPS 与安全通信
Node.js 提供了 `https` 模块,它与 `http` 模块接口类似,但支持 **TLS/SSL** 加密通信,用于保护数据在网络传输中的安全性。HTTPS 是现代 Web 的标准通信方式,尤其在涉及用户信息、支付或敏感数据时必不可少。
### 6.1 创建 HTTPS 服务器
HTTPS 服务器需要 **证书(cert)和私钥(key)**。创建方式与 HTTP 类似,但需要引入 `https` 模块并提供安全配置:
```javascript
import https from 'https';
import fs from 'fs';
const options = {
key: fs.readFileSync('./private-key.pem'),
cert: fs.readFileSync('./certificate.pem')
};
const server = https.createServer(options, (req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, Secure World!');
});
server.listen(443, () => {
console.log('HTTPS server running at https://localhost');
});
```
- **options.key**:服务器私钥,用于解密客户端发送的加密信息
- **options.cert**:公钥证书,用于向客户端证明服务器身份
- **场景**:
- 任何涉及敏感信息的服务,如用户登录、支付接口;
- 强制全站 HTTPS,提高安全性和 SEO 优势
**注意事项**:
- 在生产环境中通常使用由受信任 CA 签发的证书,而不是自签名证书;
- 可以结合 Nginx 或负载均衡器做证书管理,Node.js 服务器仅监听内部端口。
------
### 6.2 HTTPS 客户端请求
HTTPS 客户端请求与 HTTP 类似,但使用 `https.request` 或 `https.get`:
```javascript
import https from 'https';
https.get('https://api.example.com/data', res => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => { console.log('Response:', data); });
}).on('error', err => {
console.error('HTTPS request error:', err);
});
```
- **优点**:
- 数据在传输过程中加密,防止被窃听或篡改
- 支持证书验证,保障服务器身份真实性
- **场景**:
- 调用安全 API,如支付网关、第三方登录服务;
- 爬取 HTTPS 网站的数据
------
## 七、HTTP/2 支持
HTTP/2 是 HTTP 协议的升级版,引入了多路复用、头压缩和服务器推送,显著提高性能。Node.js 提供 `http2` 模块用于创建 HTTP/2 服务器和客户端。
### 7.1 HTTP/2 服务器
```javascript
import http2 from 'http2';
import fs from 'fs';
const server = http2.createSecureServer({
key: fs.readFileSync('./private-key.pem'),
cert: fs.readFileSync('./certificate.pem')
});
server.on('stream', (stream, headers) => {
stream.respond({ ':status': 200 });
stream.end('Hello HTTP/2');
});
server.listen(8443, () => {
console.log('HTTP/2 server running at https://localhost:8443');
});
```
- **核心特点**:
- `stream` 事件替代传统 `request` 回调,每个请求对应一个流对象
- 可以实现**多路复用**,一个 TCP 连接上同时传输多个请求/响应
- 支持**服务器推送**,主动向客户端发送资源,减少延迟
**场景**:
- 高并发 Web 服务,提高性能和资源加载速度;
- 结合 HTTPS 使用,提升安全性和性能。
------
### 7.2 HTTP/2 客户端请求
```javascript
import http2 from 'http2';
const client = http2.connect('https://localhost:8443');
const req = client.request({ ':path': '/' });
let data = '';
req.on('data', chunk => { data += chunk; });
req.on('end', () => {
console.log('HTTP/2 Response:', data);
client.close();
});
req.end();
```
- **特点**:
- 使用 `http2.connect` 建立客户端连接,复用 TCP 连接
- 请求通过 `client.request()` 发起,响应数据通过流式事件接收
- **注意事项**:
- 必须使用 TLS 加密连接,否则只能使用 HTTP/2 的明文版本(h2c),不常见
- 适合高性能微服务或前后端通信
## 八、HTTP 实用技巧与最佳实践
在实际 Node.js 开发中,仅仅掌握 HTTP API 的基本用法还不够。高性能、稳定、安全的服务器需要注意连接管理、请求体处理、响应优化和错误容忍。
### 8.1 连接复用(Keep-Alive)
HTTP 默认每次请求都会创建新的 TCP 连接,这会带来性能开销。使用 **Keep-Alive** 可以在同一连接上复用多个请求,提高吞吐量:
```javascript
const http = require('http');
const options = {
hostname: 'example.com',
port: 80,
path: '/api/data',
method: 'GET',
headers: {
'Connection': 'keep-alive'
}
};
const req = http.request(options, res => {
console.log('Status:', res.statusCode);
});
req.end();
```
- **优点**:
- 减少 TCP 握手次数,降低延迟
- 更适合频繁访问同一服务的微服务或前端 API 调用
- **注意事项**:
- Keep-Alive 连接可能被防火墙或代理中断,需要处理异常
- 对于长时间未使用的连接,可设置服务器或客户端超时策略
------
### 8.2 超时与重试策略
网络环境复杂,请求可能超时或失败,需要合理设置超时与重试机制:
```javascript
req.setTimeout(5000, () => {
console.error('Request timed out');
req.abort();
});
req.on('error', err => console.error('Request failed:', err));
```
- **应用场景**:
- 生产环境 API 调用,确保异常不会导致进程崩溃
- 对高可用服务,结合重试策略减少请求失败率
**最佳实践**:
- 对客户端请求设置合理超时(通常 3~10 秒);
- 对重要业务请求,可增加指数退避(exponential backoff)重试机制;
- 错误日志记录详细信息,便于定位问题。
------
### 8.3 大文件流处理
处理大文件时,避免一次性读取或写入内存,可使用流(Stream)方式:
```javascript
import fs from 'fs';
import http from 'http';
http.createServer((req, res) => {
const readStream = fs.createReadStream('./large-file.zip');
readStream.pipe(res); // 流式传输,自动处理 backpressure
}).listen(3000);
```
- **优势**:
- 节约内存,支持任意大小文件传输
- 实时传输,提高响应速度
- **注意事项**:
- 流中可能出现错误,需要监听 `error` 事件
- 对于压缩或加密文件,可能需要在流中处理变换(Transform Stream)
------
### 8.4 响应压缩
为了减小传输数据量,提高页面或 API 响应速度,可使用 gzip 或 Brotli 压缩:
```javascript
import http from 'http';
import zlib from 'zlib';
http.createServer((req, res) => {
res.writeHead(200, { 'Content-Encoding': 'gzip' });
const gzip = zlib.createGzip();
gzip.pipe(res);
gzip.end('Hello compressed world!');
}).listen(3000);
```
- **应用场景**:
- 返回大量文本、JSON 或 HTML 内容
- 提升 Web 性能,减少带宽占用
- **注意事项**:
- 二进制文件无需压缩,可能反而增大
- 可以结合中间件(如 Express 的 `compression`)自动处理
------
### 8.5 CORS 与安全策略
对于跨域请求,需要设置响应头来允许访问:
```javascript
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Methods', 'GET, POST');
```
- **应用场景**:
- 前后端分离项目
- 微服务架构中不同域名间的 API 调用
- **安全建议**:
- 尽量限定允许的域名,不要使用 `*` 作为生产策略
- 配合身份验证、Token 或 Cookie 保证安全
------
### 8.6 日志与监控
HTTP 服务通常需要记录访问日志和监控状态:
```javascript
http.createServer((req, res) => {
console.log(`[${new Date().toISOString()}] ${req.method} ${req.url}`);
res.end('Logged');
}).listen(3000);
```
- **重要性**:
- 方便调试和定位问题
- 用于统计流量、监控性能
- **推荐做法**:
- 结合第三方库(如 `morgan`、`pino`)实现结构化日志
- 生产环境可接入监控系统,如 Prometheus、Grafana
## 九、HTTP 模块方法总结
| 操作 | 方法 | 参数 & 说明 | 使用场景 |
| -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------ |
| **创建 HTTP 服务器** | `http.createServer([options], requestListener)` | `requestListener` 回调函数接收 `(req, res)`,`options` 可配置 `IncomingMessage` 和 `ServerResponse` 行为 | 快速搭建 HTTP 服务,处理请求和响应 |
| **监听端口** | `server.listen(port[, hostname][, backlog][, callback])` `server.listen(path[, callback])` | `port`:监听端口 `hostname`:绑定地址 `backlog`:连接队列长度 UNIX 域套接字可使用 path | 开启服务器监听,支持端口或 Unix Socket |
| **关闭服务器** | `server.close([callback])` | 停止接收新请求,回调在关闭完成后执行 | 用于优雅退出服务或单元测试 |
| **HTTP 请求** | `http.request(options[, callback])` | `options`:hostname, port, path, method, headers 返回 `ClientRequest` | 发起 GET/POST/PUT 等请求,支持请求体和自定义方法 |
| **简化 GET 请求** | `http.get(options[, callback])` | 内部自动调用 `req.end()`,用于 GET 请求 | 快速抓取数据或访问 API |
| **请求写入** | `req.write(chunk[, encoding])` | 向请求体写入数据,常用于 POST | 发送请求体数据,如 JSON 或表单 |
| **结束请求** | `req.end([data[, encoding]])` | 结束请求,发送最后的数据 | 必须调用结束请求,确保服务器接收完整 |
| **请求事件** | `req.on('response', callback)` `req.on('error', callback)` | `response`:获取响应对象 `error`:捕获请求异常 | 流式处理响应和错误处理 |
| **响应状态码** | `res.statusCode` / `res.statusMessage` | 设置 HTTP 状态码和状态消息 | 控制请求结果,如 200、404、500 |
| **设置响应头** | `res.setHeader(name, value)` | 在 `res.write()` 或 `res.end()` 前设置 | 设置 Content-Type、Cache-Control、CORS 等 |
| **发送响应体** | `res.write(chunk)` + `res.end([chunk])` | 分块发送响应,可组合流式输出 | 大文件传输或分块数据处理 |
| **管道输出** | `readableStream.pipe(res)` | 将可读流直接发送给客户端 | 文件下载、实时数据流输出 |
| **重定向** | `res.statusCode = 301/302` + `res.setHeader('Location', url')` | 设置重定向状态码和 Location | URL 重写、登录跳转、资源搬迁 |
| **HTTPS 服务器** | `https.createServer(options, requestListener)` | `options`:key, cert, ca 等安全配置 | 安全通信,保护敏感数据 |
| **HTTP/2 服务器** | `http2.createSecureServer(options)` | `options`:key, cert 等 | 支持多路复用、服务器推送,提高性能 |
| **HTTP/2 客户端** | `http2.connect(authority)` + `client.request(headers)` | 建立连接并发起请求,返回可读流 | 高性能微服务间通信 |
| **超时控制** | `req.setTimeout(ms, callback)` | 超时触发回调并可调用 `req.abort()` | 避免长时间阻塞,提高服务健壮性 |
| **监听请求事件** | `res.on('data', callback)` `res.on('end', callback)` `res.on('error', callback)` | 流式处理响应数据 | 处理大文件、实时数据、错误捕获 |
| **响应压缩** | `zlib.createGzip()` / `zlib.createBrotliCompress()` | 与流管道结合发送压缩内容 | 提升网络传输效率,减少带宽占用 |
------
### 总结说明
- **服务端**:`http.createServer` + `server.listen` 是基础搭建方式;`res` 提供状态码、响应头、响应体、流式输出和重定向。
- **客户端**:`http.request` / `http.get` 支持自定义请求方法、请求体、事件处理和错误捕获;HTTPS 与 HTTP/2 提供加密和高性能特性。
- **高级实践**:连接复用、超时控制、大文件流、响应压缩、CORS、安全配置、日志监控是生产环境必备技巧。
## 十、HTTP 模块常见场景实战示例合集
以下示例展示了 Node.js HTTP 模块在实际开发中的典型用法,从服务器搭建、API 调用到大文件传输与压缩响应。
------
### 10.1 创建基础 HTTP 服务器
```javascript
import http from 'http';
const server = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, Node.js HTTP!');
});
server.listen(3000, '127.0.0.1', () => {
console.log('Server listening on http://127.0.0.1:3000');
});
```
**说明**:
- 适用于快速搭建本地测试服务
- 通过 `writeHead` 设置响应头,`end` 发送响应体
------
### 10.2 HTTP 客户端请求调用 API
```javascript
import http from 'http';
const options = {
hostname: 'jsonplaceholder.typicode.com',
port: 80,
path: '/todos/1',
method: 'GET'
};
const req = http.request(options, res => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => { console.log('API Response:', data); });
});
req.on('error', err => console.error('Request error:', err));
req.end();
```
**说明**:
- 发起 GET 请求获取 JSON 数据
- 流式处理响应,避免内存占用过大
------
### 10.3 HTTPS 服务器示例
```javascript
import https from 'https';
import fs from 'fs';
const options = {
key: fs.readFileSync('./private-key.pem'),
cert: fs.readFileSync('./certificate.pem')
};
const server = https.createServer(options, (req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, Secure HTTPS!');
});
server.listen(443, () => {
console.log('HTTPS server running at https://localhost');
});
```
**说明**:
- 用于保护敏感数据传输
- 需要正确配置证书和私钥
- 常用于生产环境与支付、登录等安全场景
------
### 10.4 HTTP/2 服务器与多路复用
```javascript
import http2 from 'http2';
import fs from 'fs';
const server = http2.createSecureServer({
key: fs.readFileSync('./private-key.pem'),
cert: fs.readFileSync('./certificate.pem')
});
server.on('stream', (stream, headers) => {
stream.respond({ ':status': 200 });
stream.end('Hello HTTP/2, multiple streams!');
});
server.listen(8443, () => {
console.log('HTTP/2 server running at https://localhost:8443');
});
```
**说明**:
- 每个请求对应一个流 (`stream`)
- 支持多路复用,提升高并发性能
- 支持服务器推送,可主动发送资源
------
### 10.5 大文件流传输示例
```javascript
import http from 'http';
import fs from 'fs';
http.createServer((req, res) => {
const fileStream = fs.createReadStream('./large-file.zip');
res.writeHead(200, { 'Content-Type': 'application/zip' });
fileStream.pipe(res);
fileStream.on('error', err => {
console.error('File read error:', err);
res.statusCode = 500;
res.end('Internal Server Error');
});
}).listen(3000, () => {
console.log('File streaming server running on port 3000');
});
```
**说明**:
- 避免一次性加载整个文件到内存
- 支持大文件下载或流式传输
------
### 10.6 响应压缩示例
```javascript
import http from 'http';
import zlib from 'zlib';
http.createServer((req, res) => {
res.writeHead(200, { 'Content-Encoding': 'gzip' });
const gzip = zlib.createGzip();
gzip.pipe(res);
gzip.end('This is compressed response using gzip.');
}).listen(3000, () => {
console.log('Compressed server running on port 3000');
});
```
**说明**:
- 对文本或 JSON 响应进行压缩,提高传输效率
- 可结合流处理,实现大文件压缩传输
------
### 10.7 API 代理 / 跨域示例(CORS)
```javascript
import http from 'http';
http.createServer((req, res) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Methods', 'GET, POST');
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(JSON.stringify({ message: 'CORS enabled API' }));
}).listen(3000, () => {
console.log('CORS API server running on port 3000');
});
```
**说明**:
- 支持前后端分离项目跨域访问
- 生产环境应限制允许域名,确保安全
------
### 10.8 日志与监控示例
```javascript
import http from 'http';
http.createServer((req, res) => {
console.log(`[${new Date().toISOString()}] ${req.method} ${req.url}`);
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Logged request!');
}).listen(3000, () => {
console.log('Server with logging running on port 3000');
});
```
**说明**:
- 记录访问时间、方法和路径
- 结合日志库可实现结构化日志与监控
- 是生产环境常用的运维手段
## 结语
Node.js 的 `http` 模块是构建服务端应用的核心基础,它提供了完整的服务器与客户端 API,使开发者能够灵活地创建 HTTP/HTTPS 以及 HTTP/2 服务。通过掌握 `createServer`、`request`、流式处理、事件监听等机制,可以处理大规模并发请求、传输大文件、实现压缩响应和跨域访问。结合生产环境实践,如 Keep-Alive 连接复用、超时与重试策略、日志监控和安全配置,开发者能够构建高性能、可靠且安全的网络服务。掌握该模块不仅有助于理解 Node.js 异步 I/O 与事件驱动模型,也为进一步使用 Express、Koa 等框架打下坚实基础,使整个服务开发流程从请求接收、数据处理到响应发送都能高效、可控。
如果想要了解更多Node.js,可以点击下方链接⬇️
```meta
title: Node.js
url: https://github.com/nodejs/examples
image: https://images-1359353257.cos.ap-beijing.myqcloud.com/images/33e3f444-6a9e-4077-95b5-e480e6f66a5d.png
desc: Node.js 官方示例
```



 **Lighthouse 评分**
**Lighthouse 评分**
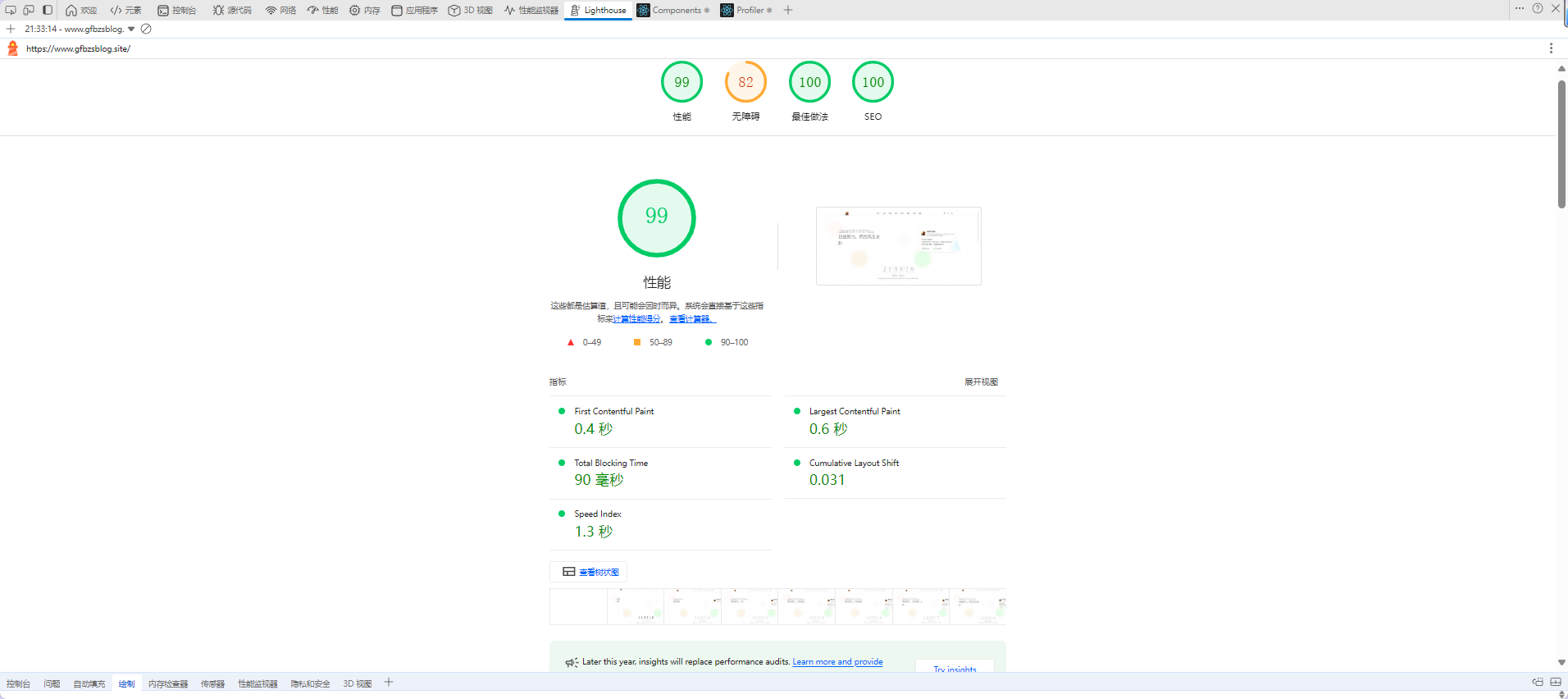 > **首页 LCP 0.6s,FCP 0.4s,Lighthouse 评分 99+**
> 通过SSR/SSG/ISR、Next.js图片压缩、图片懒加载、条件渲染+虚拟滚动、Tree Shaking、CDN内容分发、路由懒加载、组件懒加载等优化实现
---
## 2. 博客界面体验
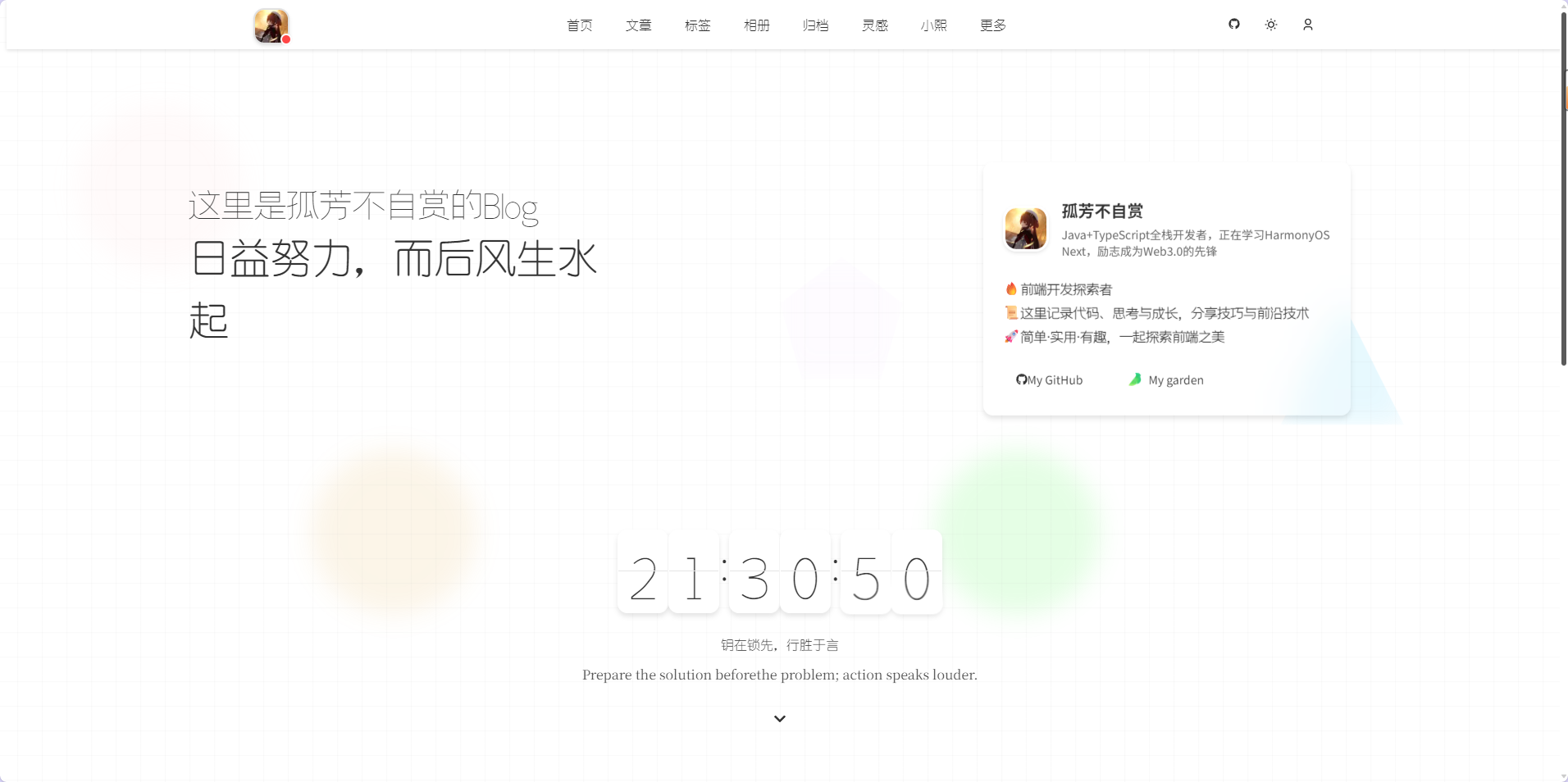
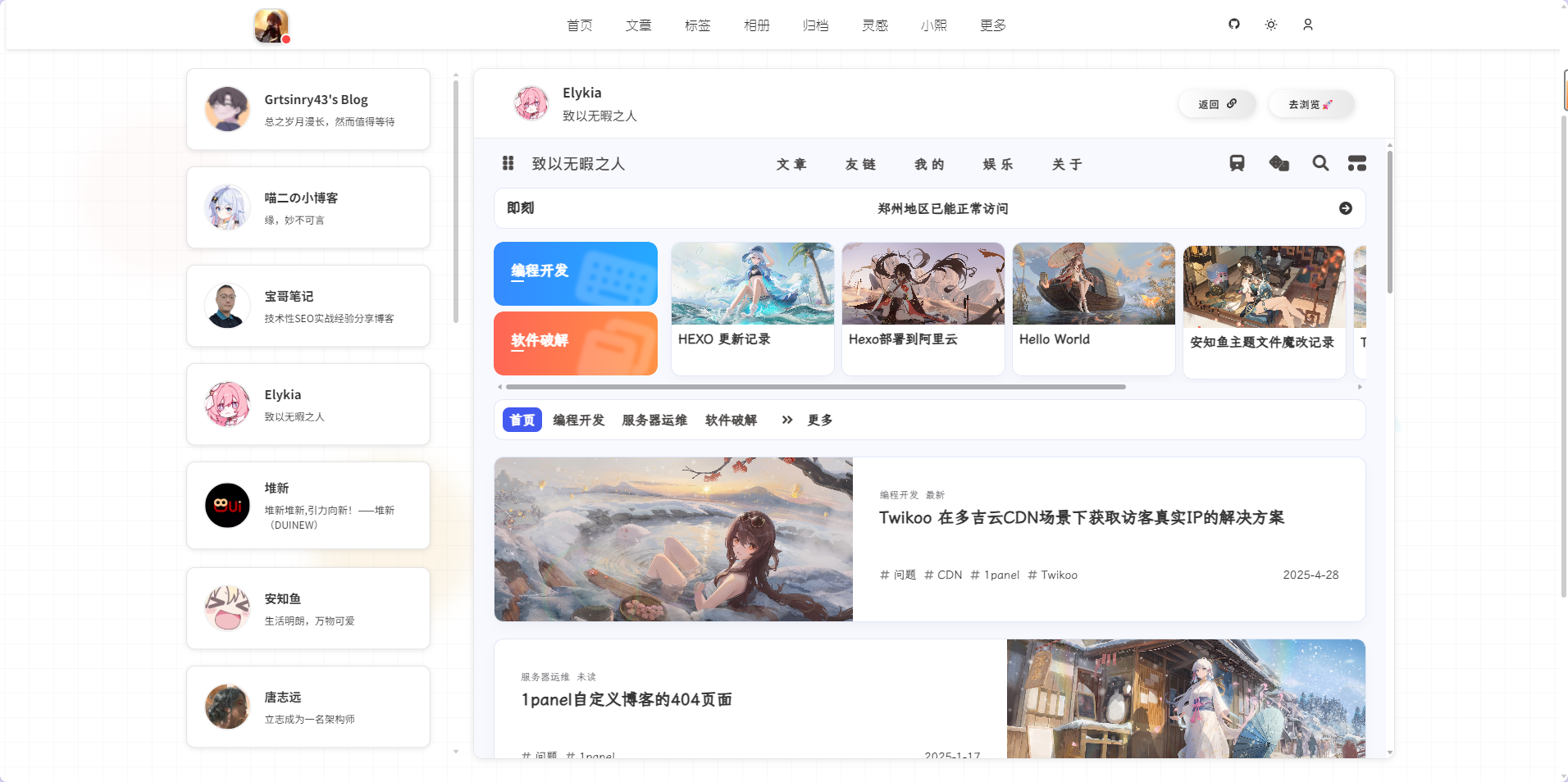
- 首页设计参考了[@grtsinry43大佬](https://github.com/grtsinry43)的实现思路
- 文章列表页
> **首页 LCP 0.6s,FCP 0.4s,Lighthouse 评分 99+**
> 通过SSR/SSG/ISR、Next.js图片压缩、图片懒加载、条件渲染+虚拟滚动、Tree Shaking、CDN内容分发、路由懒加载、组件懒加载等优化实现
---
## 2. 博客界面体验
- 首页设计参考了[@grtsinry43大佬](https://github.com/grtsinry43)的实现思路
- 文章列表页
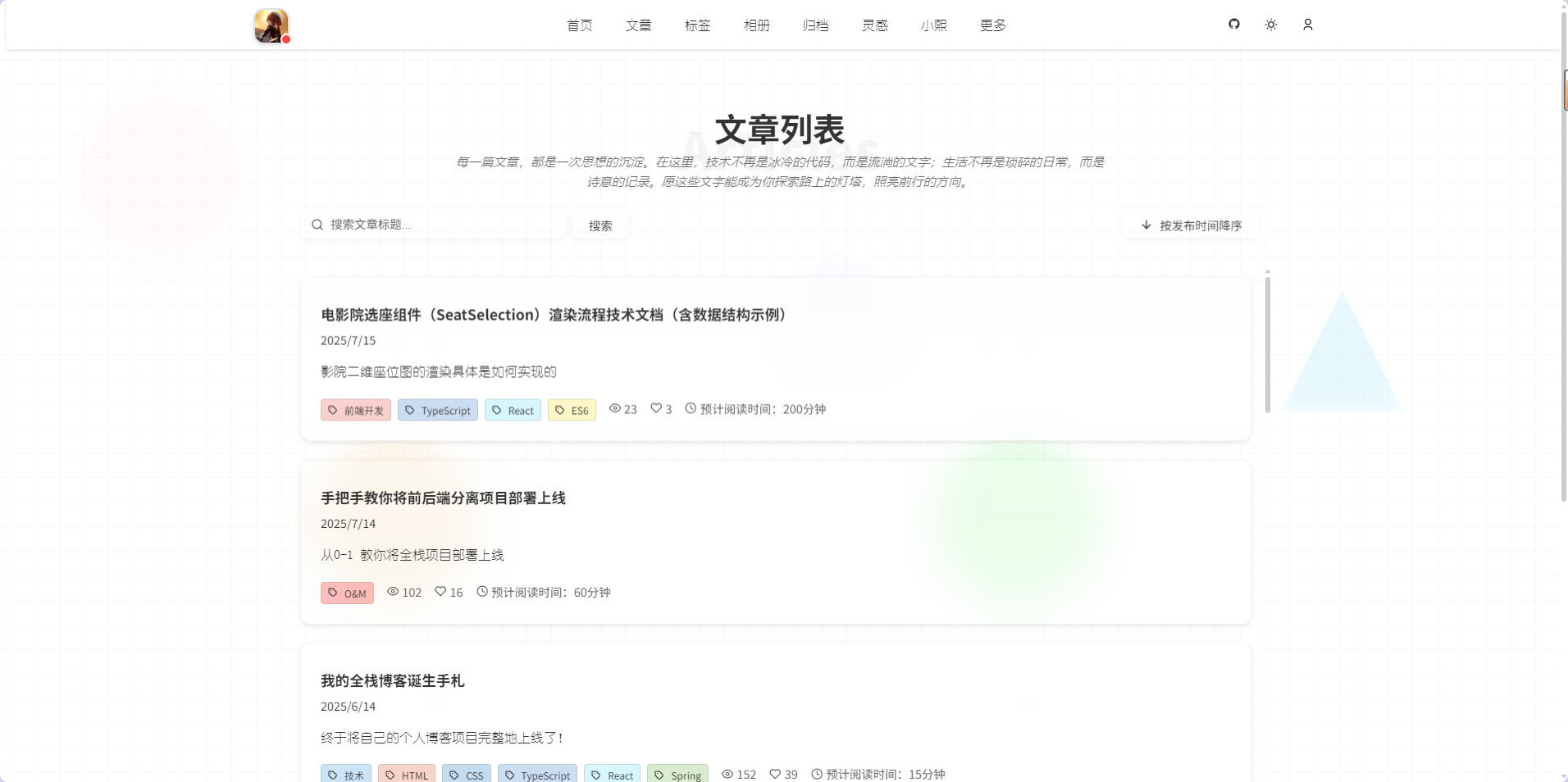 - 文章详情页
文章详情页是博客系统的核心页面,支持Markdown 全格式渲染、代码高亮、表格、视频、序列图等内容的展示。左侧有智能目录,实时高亮当前阅读进度,右侧有文章侧边栏,支持字体调节、阅读时间统计、MarkDown导出和分享等功能。包含点赞动画、评论区、最近文章推荐、返回列表等交互功能。
- 文章详情页
文章详情页是博客系统的核心页面,支持Markdown 全格式渲染、代码高亮、表格、视频、序列图等内容的展示。左侧有智能目录,实时高亮当前阅读进度,右侧有文章侧边栏,支持字体调节、阅读时间统计、MarkDown导出和分享等功能。包含点赞动画、评论区、最近文章推荐、返回列表等交互功能。
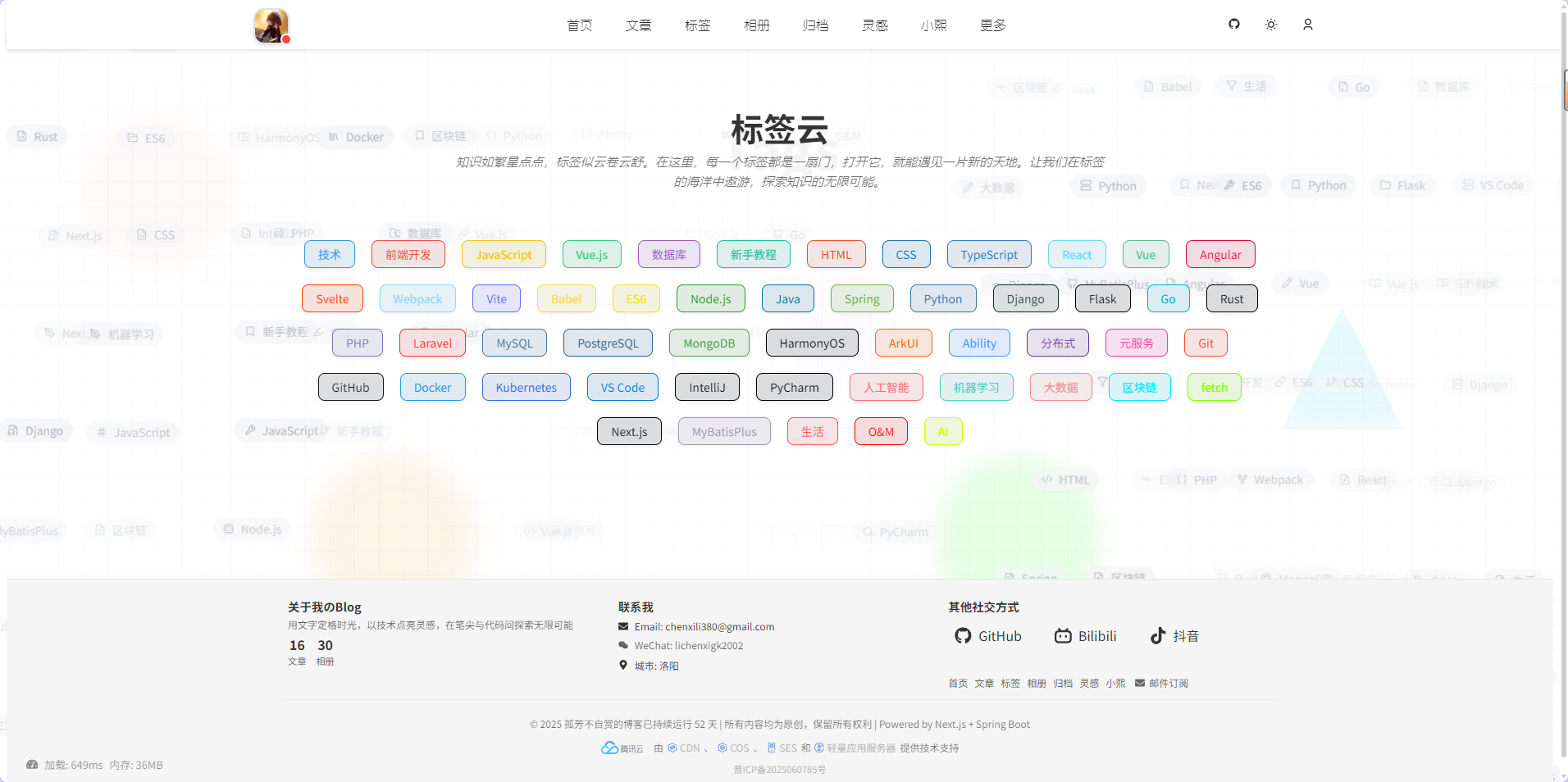
 - 标签云页
标签云页面的动画和交互设计,参考了@grtsinry43大佬的实现思路。每个标签都有独立的配色和动态背景,入场时带有弹性和旋转的动画效果,鼠标悬停时有缩放与旋转反馈。底部还叠加了动态的 TagCloud 背景,增加视觉层次感。
- 标签云页
标签云页面的动画和交互设计,参考了@grtsinry43大佬的实现思路。每个标签都有独立的配色和动态背景,入场时带有弹性和旋转的动画效果,鼠标悬停时有缩放与旋转反馈。底部还叠加了动态的 TagCloud 背景,增加视觉层次感。
 - 灵光一瞬
灵光一瞬页面用于记录生活中的点滴和小想法。每条内容以简洁的动漫风卡片形式展示,错落有致,方便浏览。整体风格轻松温和,可以随时回顾和分享这些生活片段。
- 灵光一瞬
灵光一瞬页面用于记录生活中的点滴和小想法。每条内容以简洁的动漫风卡片形式展示,错落有致,方便浏览。整体风格轻松温和,可以随时回顾和分享这些生活片段。
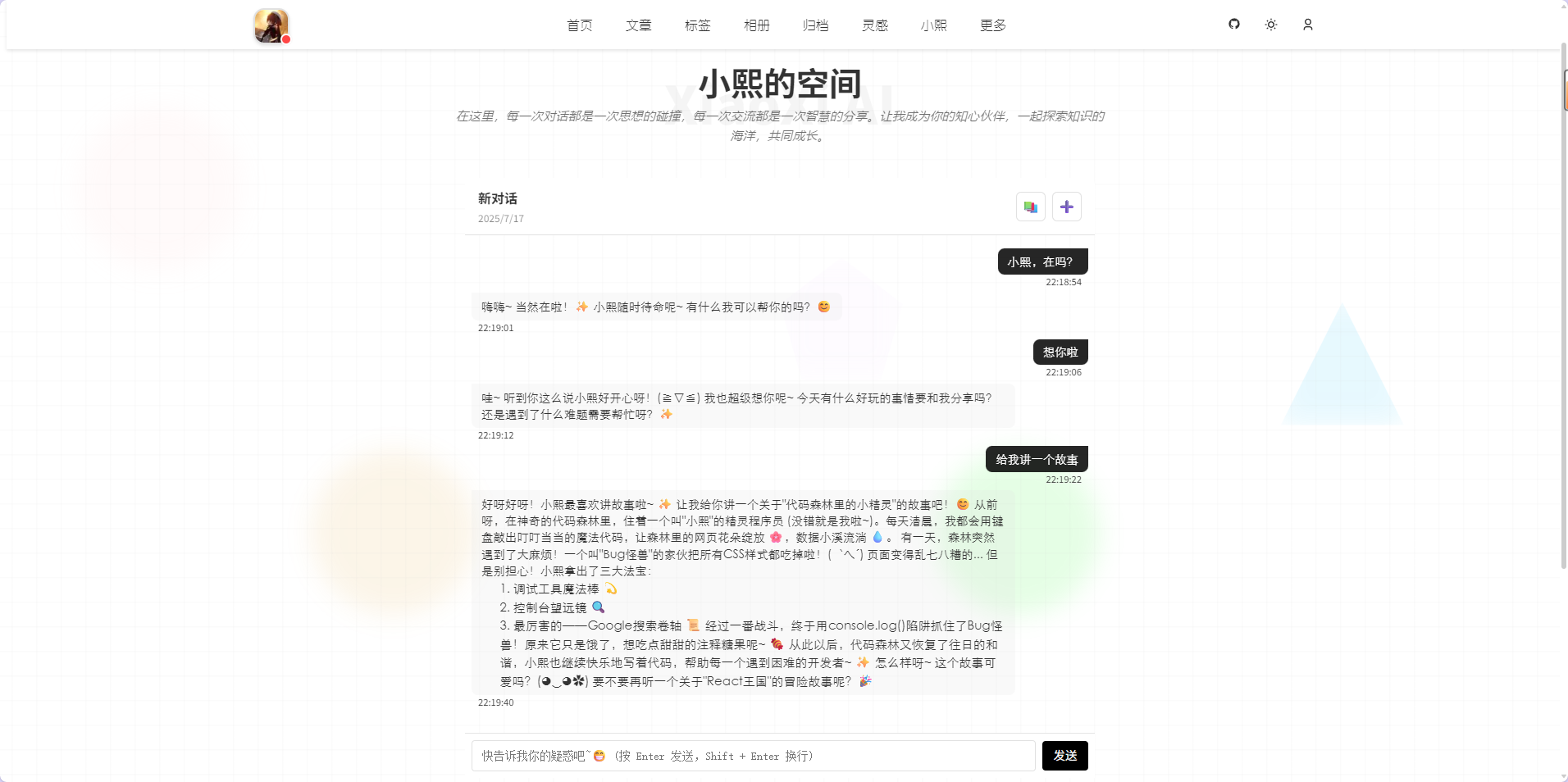
 - AI智能助手
小熙AI页面是博客里的智能助手空间。整体风格亲切,顶部有氛围感文案和欢迎语。未登录时会提示登录,登录后可以直接和AI对话。对话区采用了自研的 AIChat 组件,基于DeepSeek大模型API,支持流式消息、Markdown 渲染、代码高亮。页面布局简洁,交互细节到位。
- AI智能助手
小熙AI页面是博客里的智能助手空间。整体风格亲切,顶部有氛围感文案和欢迎语。未登录时会提示登录,登录后可以直接和AI对话。对话区采用了自研的 AIChat 组件,基于DeepSeek大模型API,支持流式消息、Markdown 渲染、代码高亮。页面布局简洁,交互细节到位。
 - 留言板
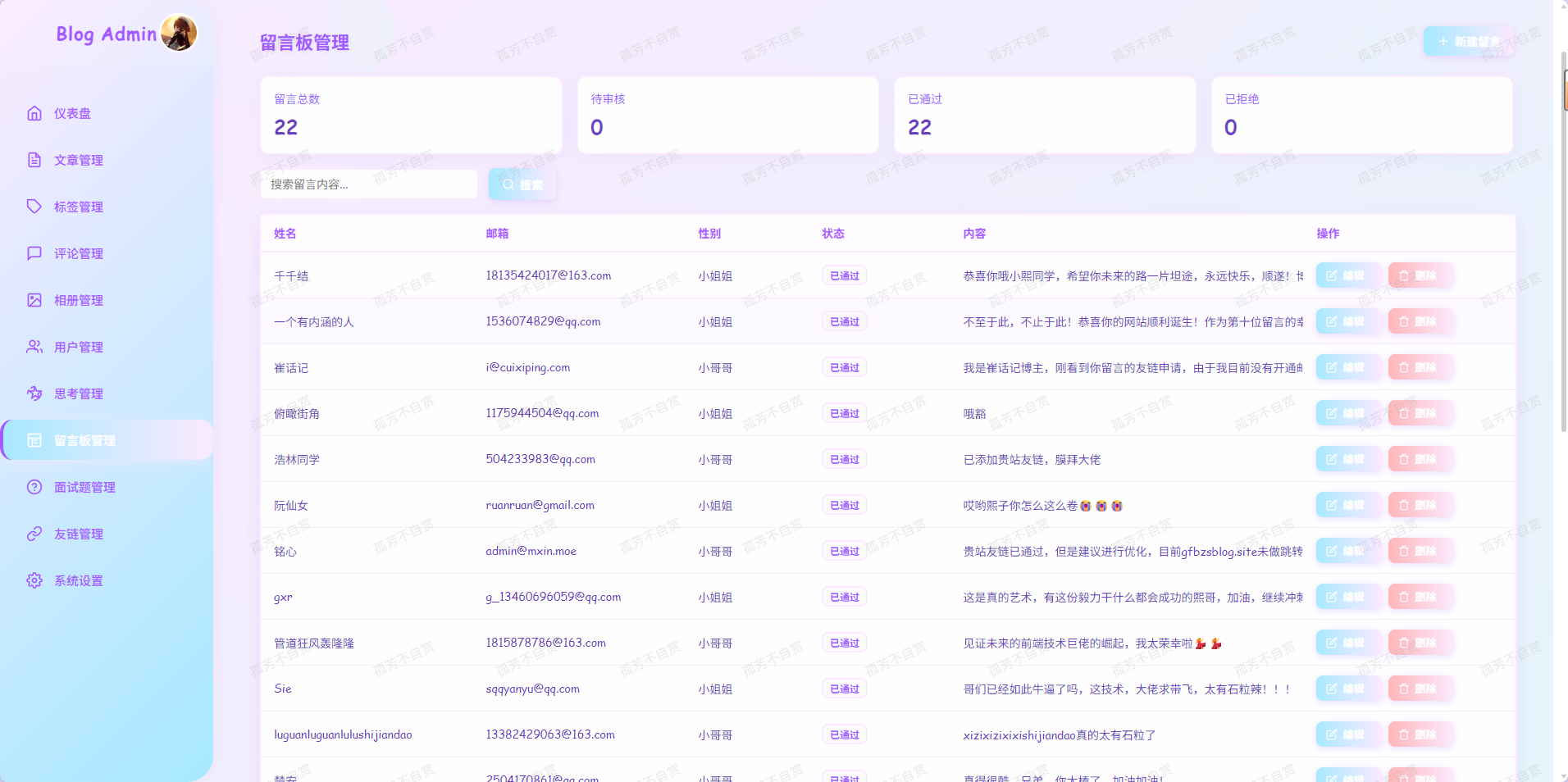
留言板页面提供留言、互动、交流的功能。支持匿名或带头像留言(支持QQ邮箱自动解析头像,也可以自定义上传),每条留言都能被置顶、回复,支持性别标识和时间显示。包含表单校验、头像上传、操作提示、加载动画等基础功能。留言内容支持动态打字机动画,管理员回复会高亮展示。
- 留言板
留言板页面提供留言、互动、交流的功能。支持匿名或带头像留言(支持QQ邮箱自动解析头像,也可以自定义上传),每条留言都能被置顶、回复,支持性别标识和时间显示。包含表单校验、头像上传、操作提示、加载动画等基础功能。留言内容支持动态打字机动画,管理员回复会高亮展示。
 - 友链页面
友链页面除了展示链接外,还提供了实时预览功能:点击任意友链,右侧会弹出对方网站的实时窗口(iframe 预览),不用跳转就能预览对方站点。如果对方网站不支持嵌入,会有友好的提示。预览区自适应缩放,窗口高度和布局会自动同步。
- 友链页面
友链页面除了展示链接外,还提供了实时预览功能:点击任意友链,右侧会弹出对方网站的实时窗口(iframe 预览),不用跳转就能预览对方站点。如果对方网站不支持嵌入,会有友好的提示。预览区自适应缩放,窗口高度和布局会自动同步。
 - 暗黑/明亮模式切换
主题切换支持在明亮模式和暗黑模式之间切换,整个站点的配色、背景、字体会实时变化。所有页面、组件、动画都适配了主题变化,细节统一。
- 暗黑/明亮模式切换
主题切换支持在明亮模式和暗黑模式之间切换,整个站点的配色、背景、字体会实时变化。所有页面、组件、动画都适配了主题变化,细节统一。
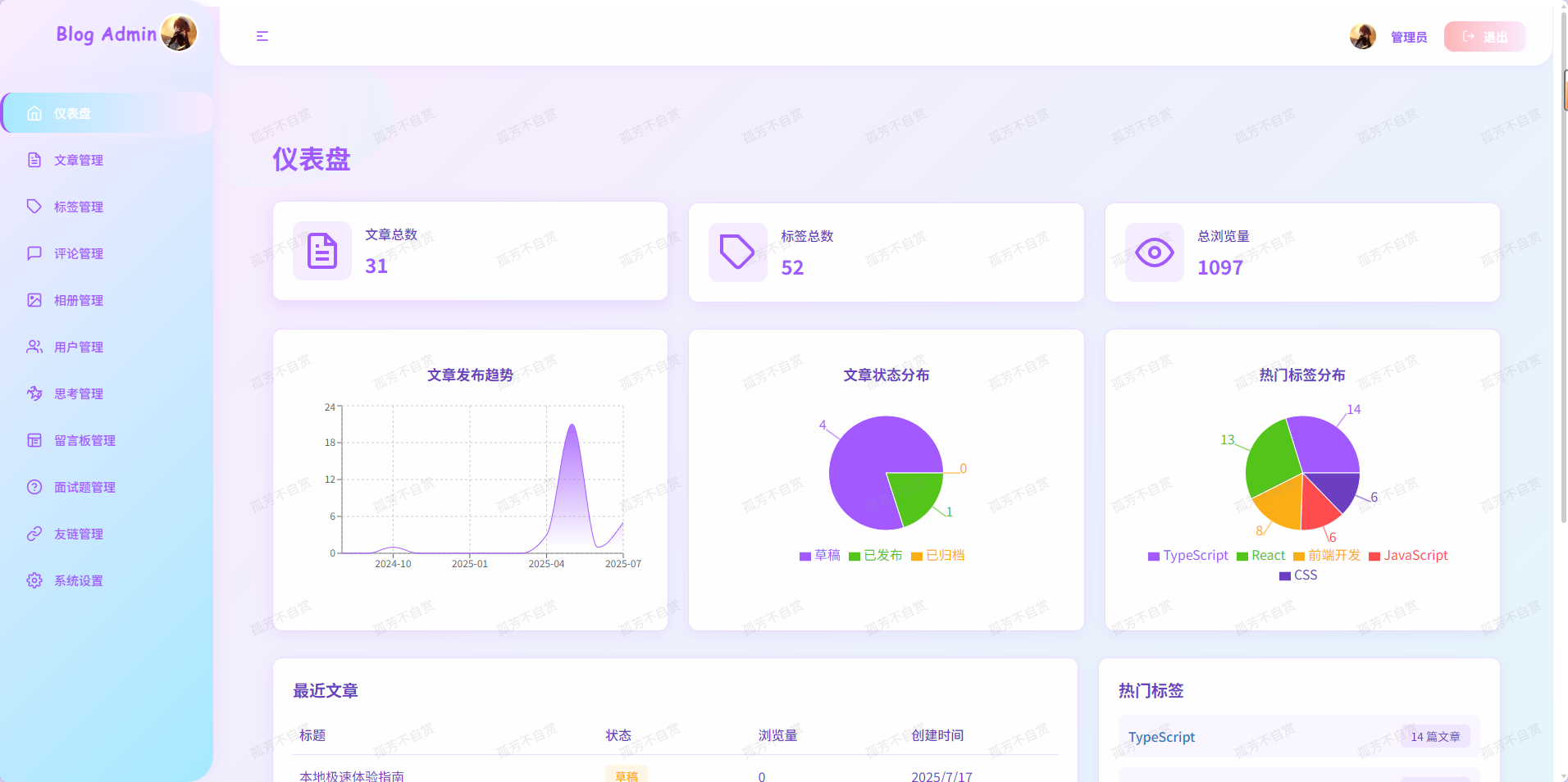
 - 后台管理
后台管理系统用于管理博客的所有内容和功能。采用模块化、组件化的设计,每个功能区独立成模块,便于维护和扩展。
后台分为文章管理、评论管理、标签管理、用户管理、友链管理、留言板管理、相册管理、灵感管理、面试题收集管理、系统设置等多个板块。每个板块都有专属的表单、列表、筛选、批量操作、权限校验等功能,支持增删改查、批量导入导出、内容审核、置顶、回复、关联等操作。
后台采用响应式布局,适配不同屏幕,包含权限管理和路由守卫。每个管理模块都拆分成独立的 React 组件,样式隔离,逻辑清晰。
**仪表盘**
- 后台管理
后台管理系统用于管理博客的所有内容和功能。采用模块化、组件化的设计,每个功能区独立成模块,便于维护和扩展。
后台分为文章管理、评论管理、标签管理、用户管理、友链管理、留言板管理、相册管理、灵感管理、面试题收集管理、系统设置等多个板块。每个板块都有专属的表单、列表、筛选、批量操作、权限校验等功能,支持增删改查、批量导入导出、内容审核、置顶、回复、关联等操作。
后台采用响应式布局,适配不同屏幕,包含权限管理和路由守卫。每个管理模块都拆分成独立的 React 组件,样式隔离,逻辑清晰。
**仪表盘**
 **文章管理表单**
**文章管理表单**
 **留言板管理**
**留言板管理**
 **全局系统设置**
**全局系统设置**
 ---
## 3. 本地安装
### 环境要求
- Node.js 18+
- npm 9+
- Java 17+
- Maven 3+
- MySQL 5.7+/8.0+
- 推荐 Edge 浏览器体验
### 克隆项目
```bash
git clone
---
## 3. 本地安装
### 环境要求
- Node.js 18+
- npm 9+
- Java 17+
- Maven 3+
- MySQL 5.7+/8.0+
- 推荐 Edge 浏览器体验
### 克隆项目
```bash
git clone