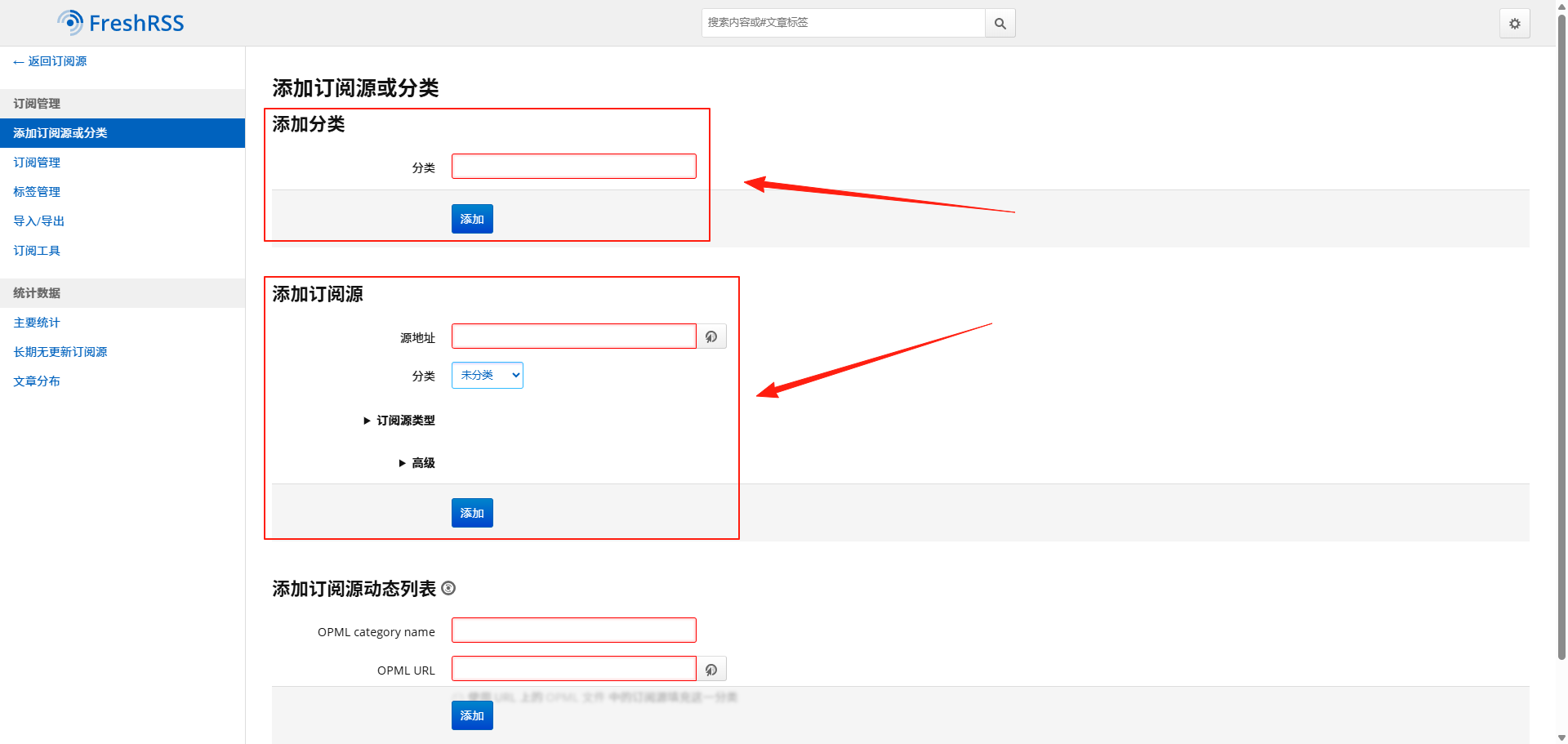
感谢订阅陶其的个人博客!
在 RESTful API 风格的接口开发中,Spring 框架提供了一系列常用的注解,这些注解可以帮助我们更方便地定义和处理 HTTP 请求。
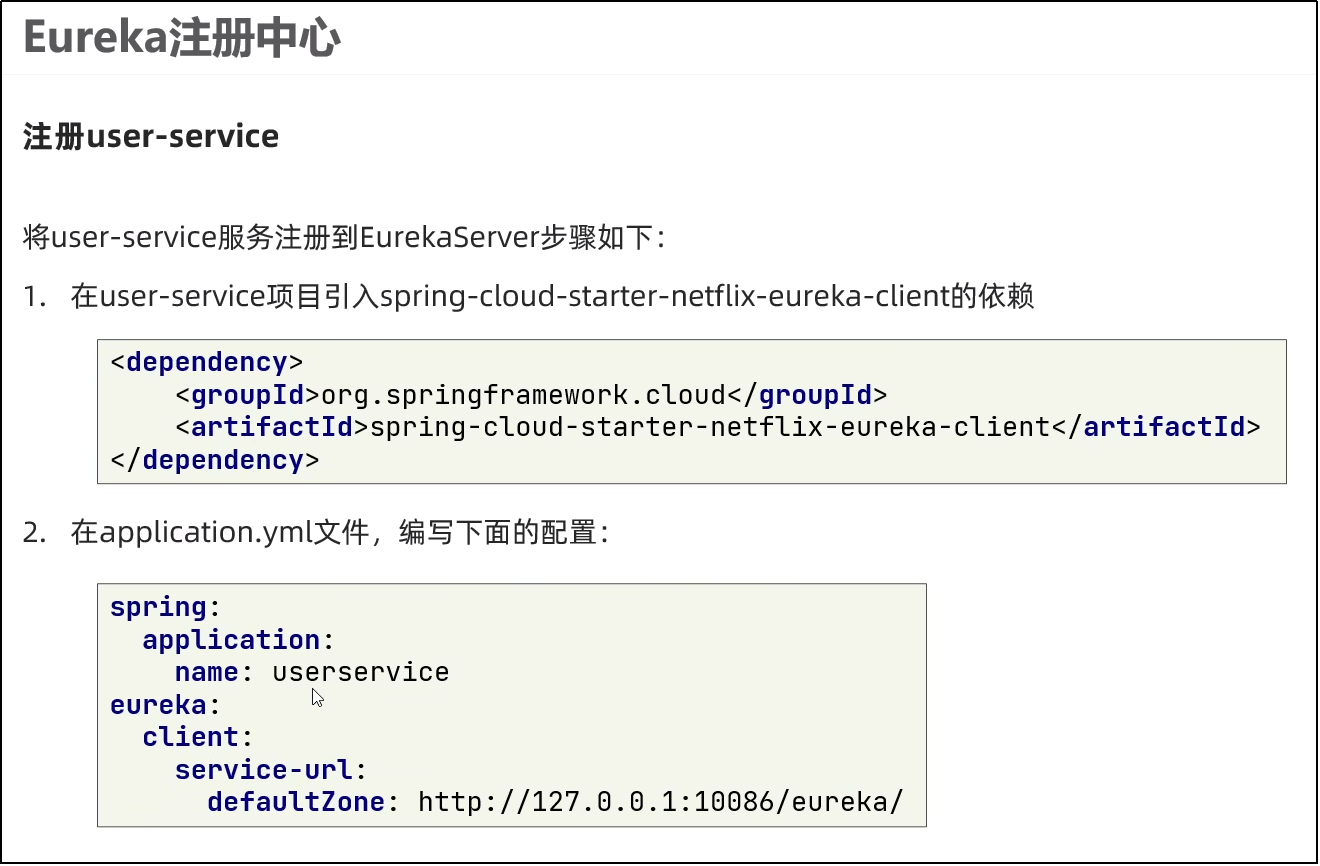
使用之前需要添加如下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
以下是一些常用注解的介绍、使用场景和简单示例:
一、控制类相关注解
1.1 @RestController
@RestController 是 Spring 框架中一个非常重要的注解,主要用于创建 RESTful 风格的控制器。
1.1.1 介绍
@RestController 是一个组合注解,它结合了 @Controller 和 @ResponseBody 的功能。
@Controller 用于标记一个类为 Spring MVC 的控制器。
@ResponseBody 用于将控制器方法的返回值直接作为 HTTP 响应体返回给客户端,不再经过视图解析器进行视图渲染。
因此,使用 @RestController 注解的类中的方法会直接返回数据,通常是 JSON 或 XML 格式。
1.1.2 使用场景
- 前后端分离开发: 在前后端分离的项目中,前端通常使用 JavaScript 框架(如 Vue.js、React.js),后端负责提供数据接口。
@RestController 可以方便地返回 JSON 数据给前端,满足前后端数据交互的需求。
- 微服务架构: 在微服务架构中,各个服务之间通过 RESTful API 进行通信。
@RestController 可以帮助快速构建服务的 API 接口,实现服务之间的数据交互。
- 开发 RESTful API: 当需要开发 RESTful 风格的 API 时,
@RestController 是首选的注解,它可以使代码更加简洁,符合 RESTful 规范。
1.1.3 简单使用示例
以下是一个使用 @RestController 创建 RESTful API 的简单示例:
@RestController
public class UserController {
// 处理 HTTP GET 请求,返回用户列表
@GetMapping("/users")
public List<String> getUsers() {
return Arrays.asList("Alice", "Bob", "Charlie");
}
// 处理 HTTP GET 请求,根据 ID 返回单个用户信息
@GetMapping("/users/{id}")
public String getUserById(Long id) {
return "User with ID: " + id;
}
}
在上述示例中,UserController 类被 @RestController 注解标记,其中的 getUsers 方法和 getUserById 方法会直接将返回值作为响应体返回给客户端。
例如,当客户端发送 GET 请求到 /users 时,会返回包含用户姓名的 JSON 数组。
1.1.4 原理
当 Spring 应用启动时,Spring 框架会扫描带有 @RestController 注解的类,并将其注册为控制器。
在处理请求时,Spring MVC 会根据请求的 URL 和 HTTP 方法匹配到相应的控制器方法。
由于 @RestController 包含 @ResponseBody 功能,控制器方法的返回值会被 HttpMessageConverter 转换为合适的格式(如 JSON、XML 等),然后直接作为 HTTP 响应体返回给客户端。
1.1.5 注意事项
- 返回值处理:
@RestController 注解的控制器方法返回值会直接作为响应体返回,因此要确保返回值类型可以被 HttpMessageConverter 正确处理。如果返回自定义对象,通常需要确保该对象的属性有对应的 getter 方法,以便正确转换为 JSON 或 XML 格式。
- 异常处理: 由于
@RestController 主要用于返回数据,当发生异常时,需要进行合适的异常处理,避免将异常信息直接暴露给客户端。可以使用 @ExceptionHandler 或 @RestControllerAdvice 来统一处理异常。
- 路径映射: 要注意控制器方法的路径映射,避免出现路径冲突。可以使用
@RequestMapping、@GetMapping、@PostMapping 等注解来精确指定请求路径和 HTTP 方法。
二、请求类型相关注解
2.1 @RequestMapping
@RequestMapping 是 Spring 框架中用于映射 HTTP 请求到控制器方法的重要注解。
2.1.1 介绍
@RequestMapping 是一个通用的请求映射注解,可用于类和方法上。
当用于类上时,它为该类中的所有处理方法设置一个基础的请求路径;
当用于方法上时,它指定了该方法具体处理的请求路径。
通过 @RequestMapping 可以精确地定义哪些 HTTP 请求会被哪个控制器方法处理。
2.1.2 使用场景
- 请求路径映射: 在开发 RESTful API 时,需要将不同的 URL 请求映射到相应的处理方法上,
@RequestMapping 可以实现这一功能。
- 支持多种 HTTP 方法: 可以通过设置
method 属性来指定处理的 HTTP 方法(如 GET、POST、PUT、DELETE 等),满足不同业务场景下的请求处理需求。
- 请求参数和请求头匹配: 可以通过
params 和 headers 属性进一步细化请求匹配规则,只有当请求的参数或请求头满足指定条件时,才会调用相应的处理方法。
2.1.3 使用方式
2.1.3.1 用于类上设置基础路径
@RestController
@RequestMapping("/api")
public class ApiController {
@RequestMapping("/hello")
@ResponseBody
public String sayHello() {
return "Hello, World!";
}
}
在上述示例中,@RequestMapping("/api") 为 ApiController 类设置了基础路径,sayHello 方法处理的请求路径是 /api/hello。
2.1.3.2 指定 HTTP 方法
@RestController
@RequestMapping("/users")
public class UserController {
// 处理 GET 请求
@RequestMapping(value = "/", method = RequestMethod.GET)
@ResponseBody
public String getUsers() {
return "Get all users";
}
// 处理 POST 请求
@RequestMapping(value = "/", method = RequestMethod.POST)
@ResponseBody
public String createUser() {
return "Create a new user";
}
}
这里通过 method 属性分别指定了 getUsers 方法处理 GET 请求,createUser 方法处理 POST 请求。
2.1.3.3 基于请求参数和请求头匹配
@RestController
@RequestMapping("/products")
public class ProductController {
// 只有当请求包含参数 "category=electronics" 时才会处理
@RequestMapping(value = "/list", params = "category=electronics")
@ResponseBody
public String getElectronicsProducts() {
return "List of electronics products";
}
// 只有当请求头中包含 "X-API-Version: 1.0" 时才会处理
@RequestMapping(value = "/details", headers = "X-API-Version=1.0")
@ResponseBody
public String getProductDetails() {
return "Product details for API version 1.0";
}
}
使用curl命令
curl "http://localhost:8080/products/list?category=electronics"
当你执行这个命令时,因为请求中包含了参数 category=electronics,所以会匹配到 getElectronicsProducts 方法,最终会返回 "List of electronics products"。
2.1.4 原理
在 Spring 应用启动时,Spring 框架会扫描所有带有 @RequestMapping 注解的类和方法,并将这些映射信息存储在 HandlerMapping 中。
当有 HTTP 请求到达时,Spring MVC 会根据请求的 URL、HTTP 方法、请求参数和请求头信息,在 HandlerMapping 中查找匹配的处理方法,然后调用该方法处理请求。
2.1.5 注意事项
- 路径冲突: 要确保不同的请求映射路径不会发生冲突。如果多个方法的请求映射规则相同,Spring 会抛出异常。
- 注解的组合使用: 可以将
@RequestMapping 与其他注解(如 @PathVariable、@RequestParam、@RequestBody 等)结合使用,以处理不同类型的请求参数。
- 性能考虑: 过多复杂的请求映射规则可能会影响请求处理的性能,因此应尽量保持请求映射规则的简洁性。
2.2 @GetMapping
2.2.1 介绍
@GetMapping 是一个组合注解,相当于 @RequestMapping(method = RequestMethod.GET)。
用于处理 HTTP GET 请求,它可以将 HTTP GET 请求映射到特定的处理方法上。
2.2.2 使用场景
主要用于从服务器获取资源,例如获取单个资源、资源列表等。
2.2.3 使用示例
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.List;
@RestController
public class ProductController {
@GetMapping("/products")
public List<String> getAllProducts() {
return Arrays.asList("Product1", "Product2", "Product3");
}
}
2.2.4 请求时的示例
当客户端发起请求时,使用如下地址:
GET http://localhost:8080/products
服务器会调用 getAllProducts 方法,并返回包含产品名称的列表。
2.3 @PostMapping
2.3.1 介绍
@PostMapping 相当于 @RequestMapping(method = RequestMethod.POST)。
用于处理 HTTP POST 请求,通常用于创建新的资源。
2.3.2 使用场景
当需要向服务器提交数据以创建新资源时使用,如创建用户、创建订单等。
2.3.3 简单使用示例
User类代码此处省略。
@RequestBody注解在 3.3 小节会讲解。
@RestController
public class UserController {
@PostMapping("/users")
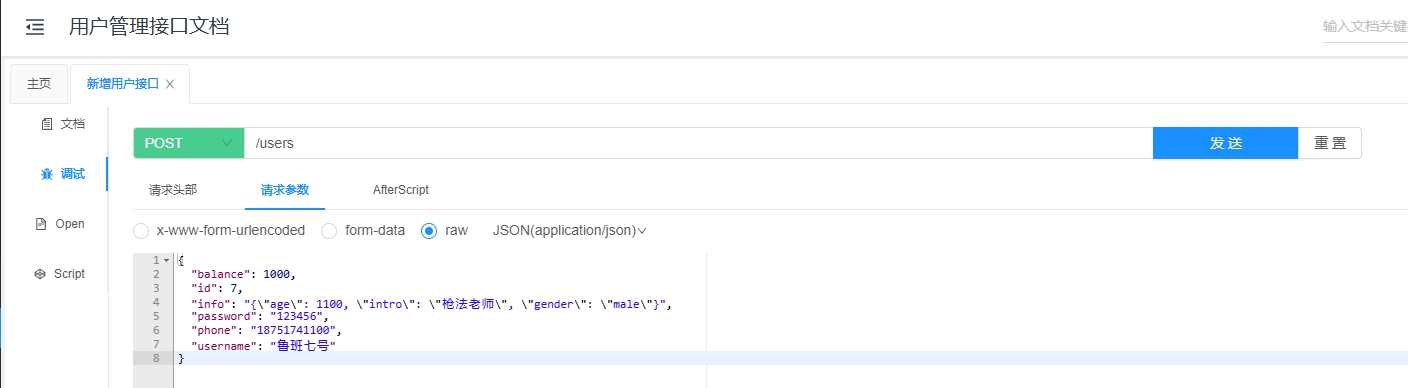
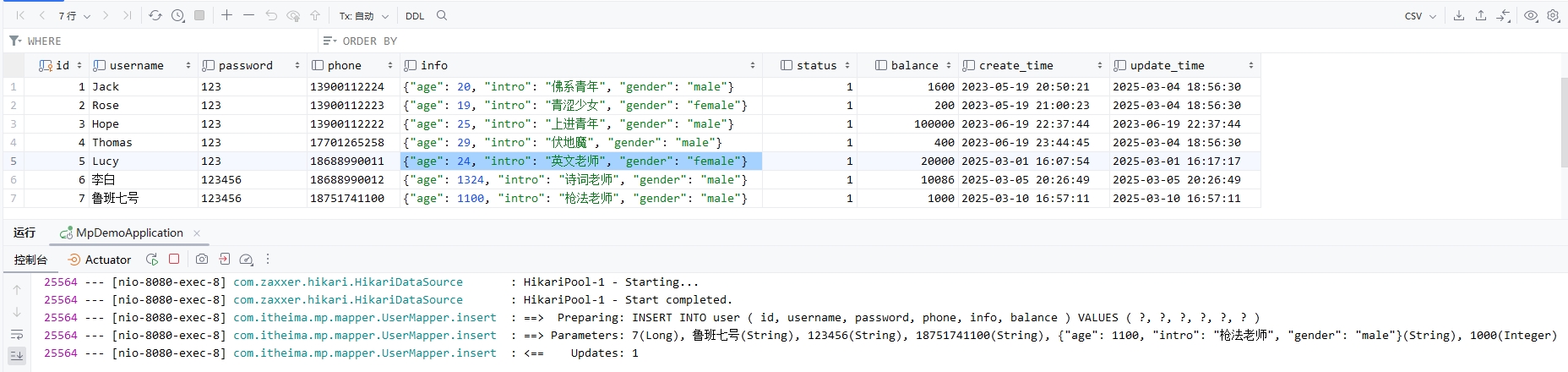
public String createUser(@RequestBody User user) {
return "User created: " + user.getName();
}
}
2.3.4 请求时的示例
客户端可以使用如下请求创建一个新用户:
POST http://localhost:8080/users
Content-Type: application/json
{
"name": "John Doe",
"age": 30
}
服务器会将请求体中的 JSON 数据映射到 User 对象,并调用 createUser 方法。
2.4 @PutMapping
2.4.1 介绍
@PutMapping 相当于 @RequestMapping(method = RequestMethod.PUT)。
用于处理 HTTP PUT 请求,通常用于更新整个资源。
2.4.2 使用场景
当需要更新资源的所有属性时使用,例如更新用户的所有信息。
2.4.3 简单使用示例
User类代码此处省略。
@PathVariable注解在 3.1 小节会讲解。
@RestController
public class UserController {
@PutMapping("/users/{id}")
public String updateUser(@PathVariable Long id, @RequestBody User user) {
return "User with ID " + id + " updated: " + user.getName();
}
}
2.4.4 请求时的示例
客户端可以使用如下请求更新用户信息:
PUT http://localhost:8080/users/1
Content-Type: application/json
{
"name": "Updated Name",
"age": 35
}
这里的 1 是用户的 ID,服务器会将其作为 @PathVariable 绑定到 id 参数,同时将请求体中的 JSON 数据映射到 User 对象,然后调用 updateUser 方法。
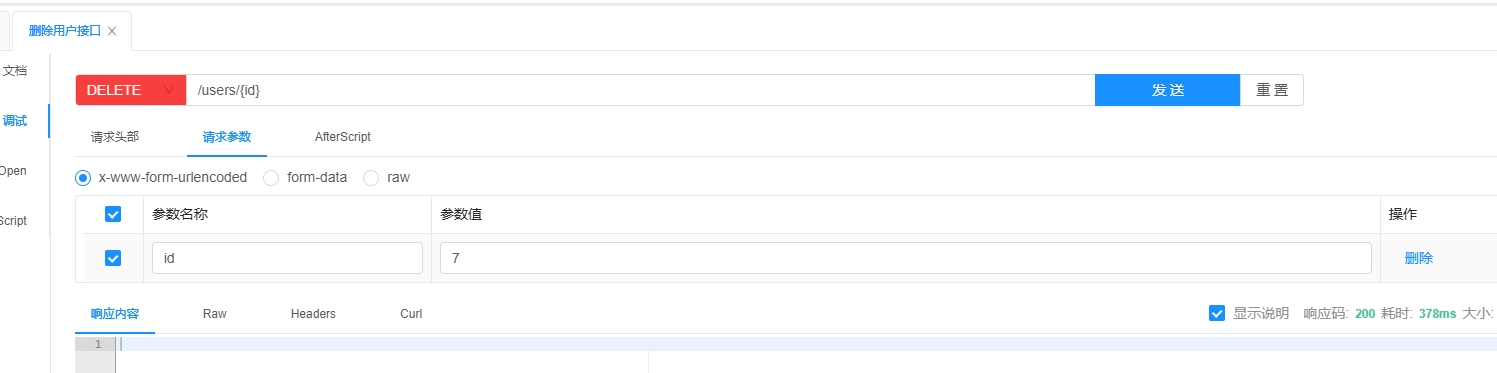
2.5 @DeleteMapping
2.5.1 介绍
@DeleteMapping 相当于 @RequestMapping(method = RequestMethod.DELETE)。
用于处理 HTTP DELETE 请求,通常用于删除资源。
2.5.2 使用场景
当需要从服务器删除某个资源时使用,例如删除用户、删除订单等。
2.5.3 简单使用示例
@RestController
public class ProductController {
@DeleteMapping("/products/{id}")
public String deleteProduct(@PathVariable Long id) {
return "Product with ID " + id + " deleted";
}
}
2.5.4 请求时的示例
客户端可以使用如下请求删除指定 ID 的产品:
DELETE http://localhost:8080/products/2
这里的 2 是产品的 ID,服务器会将其作为 @PathVariable 绑定到 id 参数,然后调用 deleteProduct 方法。
三、请求参数相关注解
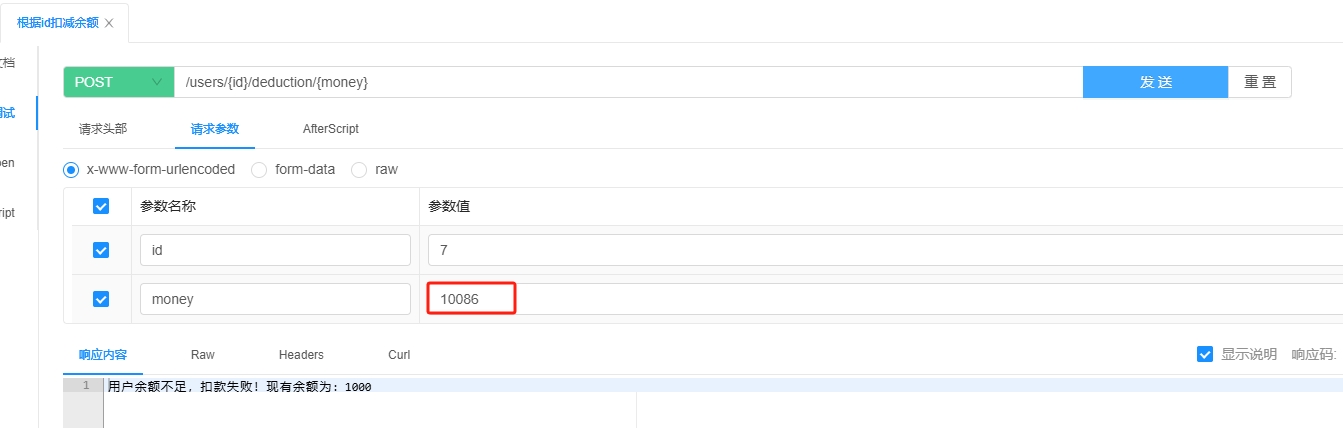
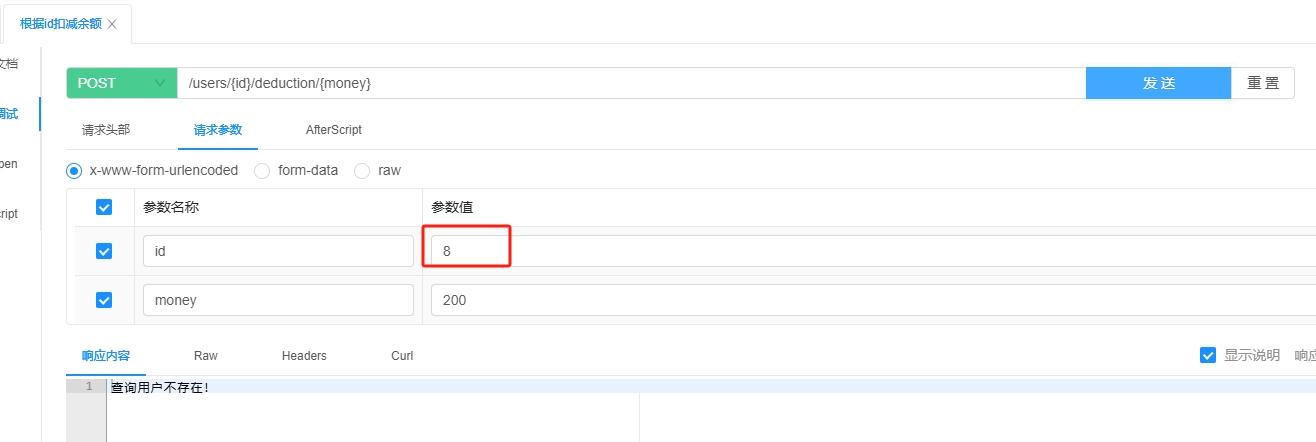
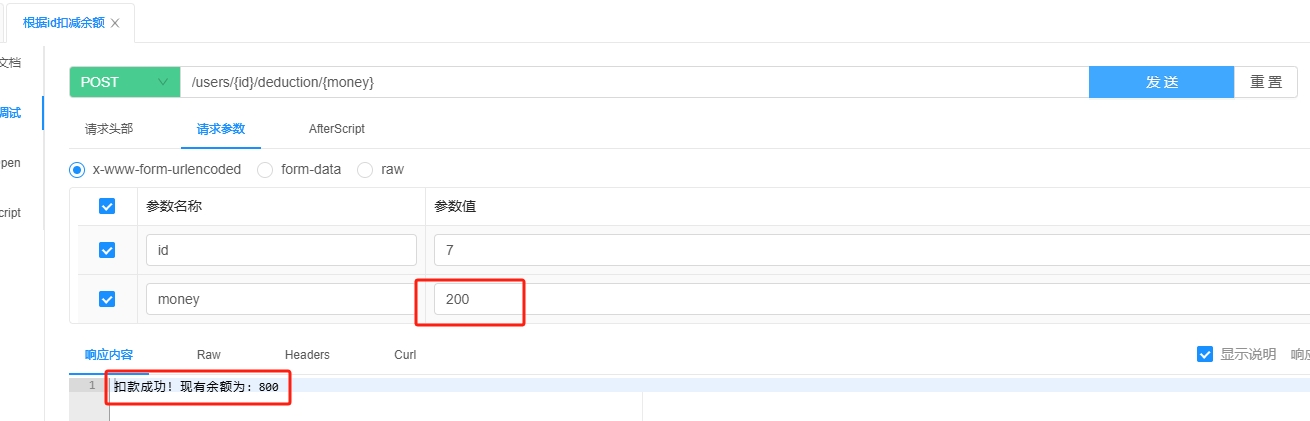
3.1 @PathVariable
3.1.1 介绍
@PathVariable 用于从 URL 路径中获取变量值。
它允许在 URL 中定义参数占位符,并将实际的参数值绑定到方法的参数上。
@PathVariable 注解的参数默认是必填的。
当客户端发送的请求 URL 中没有包含该路径变量时,Spring 会将该请求视为不匹配任何处理方法,返回 404 状态码。不可设置可选,是参数也是请求路径,所以必填。
3.1.2 使用场景
当需要在 URL 中传递参数时使用,例如根据用户 ID 获取用户信息、根据产品 ID 删除产品等。
当传入的参数名与方法的参数名不同时,可以将传入的参数名与方法参数名绑定:
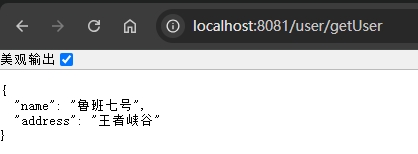
@GetMapping("/{username}")
public String searchByName(@PathVariable("username") String name) {
return "name:" + name;
}
或者写成:
@GetMapping("/{username}")
public String searchByName(@PathVariable(value = "username") String name) {
return "name:" + name;
}
3.1.3 简单使用示例
@RestController
public class OrderController {
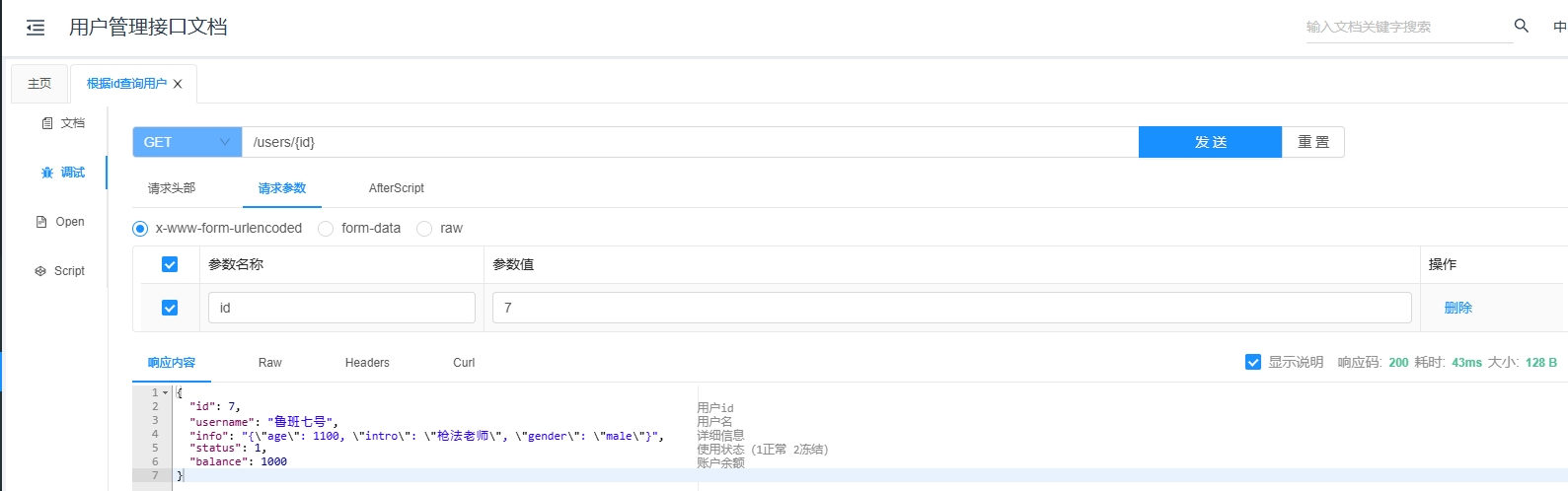
@GetMapping("/orders/{orderId}")
public String getOrder(@PathVariable Long orderId) {
return "Order with ID: " + orderId;
}
}
3.1.4 请求时的示例
客户端可以使用如下请求获取指定 ID 的订单信息:
GET http://localhost:8080/orders/123
这里的 123 是订单的 ID,服务器会将其作为 @PathVariable 绑定到 orderId 参数,然后调用 getOrder 方法。
3.2 @RequestParam
3.2.1 介绍
@RequestParam 用于从 URL 的查询参数中获取值。
它可以将查询参数绑定到方法的参数上。
@RequestParam 注解的参数默认是必填的。
当客户端发送请求时,如果没有提供该参数,Spring 会抛出 MissingServletRequestParameterException 异常。
可以通过将 @RequestParam 的 required 属性设置为 false 来将参数变为可选的。
同时,可以使用 defaultValue 属性为参数设置默认值。
3.2.2 使用场景
当需要在 URL 中传递简单的参数时使用,例如根据用户名搜索用户、根据价格范围筛选产品等。
当传入的参数名与方法的参数名不同时,可以将传入的参数名与方法参数名绑定:
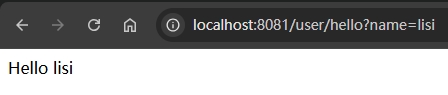
@GetMapping("/search")
public String search(@RequestParam("username") String name) {
return "name:" + name;
}
或者写成:
@GetMapping("/search")
public String search(@RequestParam(value = "username") String name) {
return "name:" + name;
}
3.2.3 简单使用示例
@RestController
public class UserController {
@GetMapping("/users/search")
public String searchUsers(@RequestParam String name) {
return "Searching for users with name: " + name;
}
}
3.2.4 请求时的示例
客户端可以使用如下请求搜索指定名称的用户:
GET http://localhost:8080/users/search?name=John
服务器会将查询参数 name 的值 John 绑定到 searchUsers 方法的 name 参数上。
3.3 @RequestBody
3.3.1 介绍
@RequestBody 用于将 HTTP 请求体的内容绑定到方法的参数上。
通常用于处理 POST 和 PUT 请求。
它会根据请求的 Content-Type 自动将请求体中的数据转换为合适的 Java 对象。
3.3.2 使用场景
当需要传递复杂的对象数据时使用,例如创建用户时传递用户的详细信息、更新产品时传递产品的完整信息等。
3.3.3 简单使用示例
Product类代码省略。
@RestController
public class ProductController {
@PostMapping("/products")
public String createProduct(@RequestBody Product product) {
return "Product created: " + product.getName();
}
}
3.3.4 请求时的示例
客户端可以使用如下请求创建一个新的产品:
POST http://localhost:8080/products
Content-Type: application/json
{
"name": "New Product",
"price": 99.99
}
服务器会将请求体中的 JSON 数据映射到 Product 对象,并调用 createProduct 方法。
3.4 @RequestHeader
3.4.1 介绍
@RequestHeader 注解用于将 HTTP 请求头中的值绑定到方法的参数上。
通过该注解可以获取请求头中的特定信息,如 User - Agent、Authorization 等。
3.4.2 使用场景
当需要从请求头中获取一些必要的信息时使用,例如获取客户端的身份验证信息、请求的内容类型等。
3.4.3 简单使用示例
@RestController
public class HeaderController {
@GetMapping("/headers")
public String getHeaderInfo(@RequestHeader("User - Agent") String userAgent) {
return "User - Agent: " + userAgent;
}
}
3.4.4 请求时的示例
客户端发起请求时,请求头中会包含 User - Agent 信息:
GET http://localhost:8080/headers
User - Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
服务器会将请求头中的 User - Agent 值绑定到 getHeaderInfo 方法的 userAgent 参数上。
3.5 @CookieValue
3.5.1 介绍
@CookieValue 注解用于将 HTTP 请求中的 Cookie 值绑定到方法的参数上。
可以通过该注解获取指定名称的 Cookie 值。
3.5.2 使用场景
当需要从请求的 Cookie 中获取某些信息时使用,例如获取用户的会话 ID、用户偏好设置等。
3.5.3 简单使用示例
@RestController
public class CookieController {
@GetMapping("/cookies")
public String getCookieValue(@CookieValue("sessionId") String sessionId) {
return "Session ID: " + sessionId;
}
}
3.5.4 请求时的示例
客户端发起请求时,请求头中包含 Cookie 信息:
GET http://localhost:8080/cookies
Cookie: sessionId=1234567890
服务器会将 Cookie 中 sessionId 的值绑定到 getCookieValue 方法的 sessionId 参数上。
3.6 @MatrixVariable
3.6.1 介绍
@MatrixVariable 注解用于从 URL 的矩阵变量中获取值。
矩阵变量是一种在 URL 路径中传递多个参数的方式,使用分号(;)分隔不同的参数。
3.6.2 使用场景
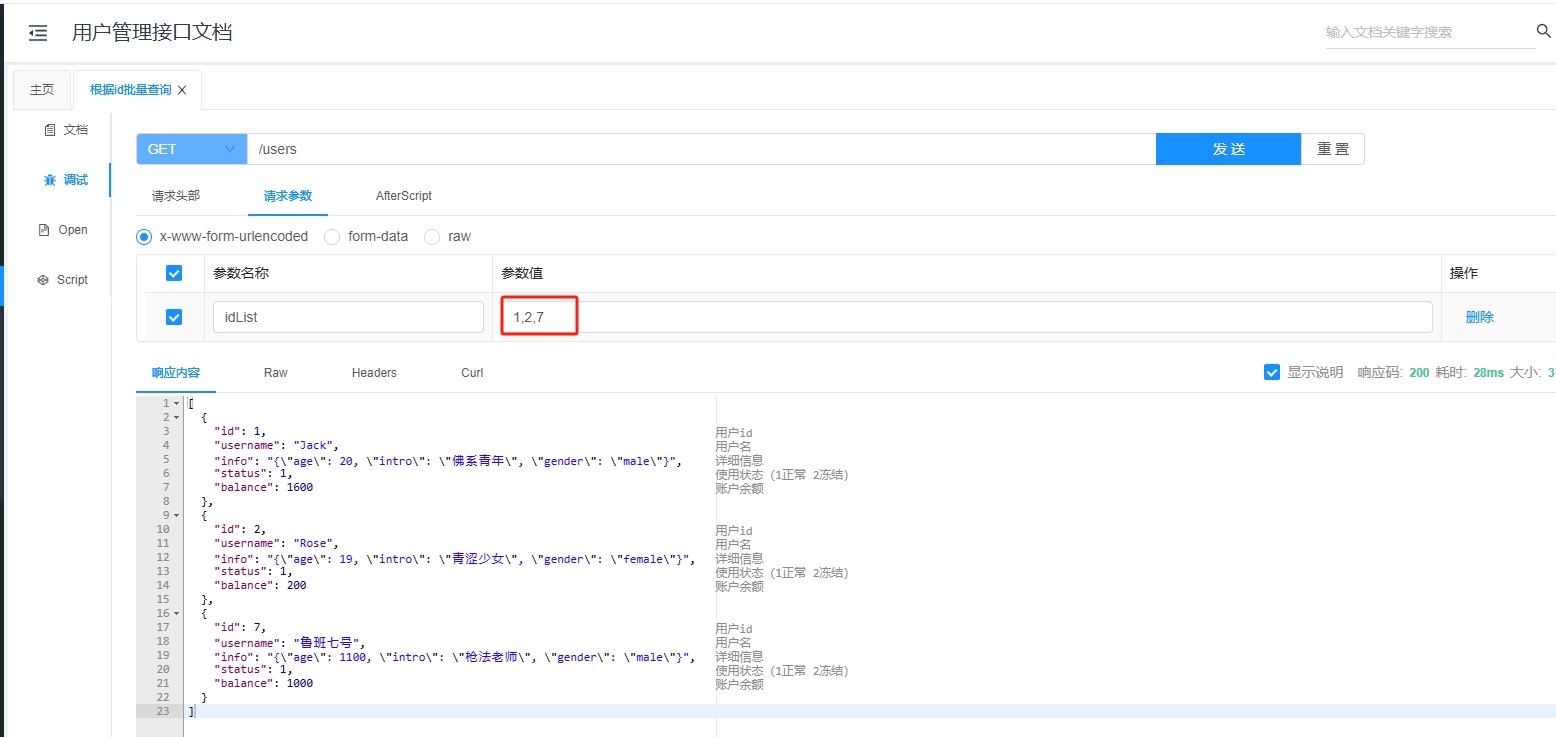
当需要在 URL 路径中传递多个相关参数时使用,例如在搜索商品时,同时传递商品的颜色、尺寸等参数。
3.6.3 简单使用示例
@RestController
@RequestMapping("/products")
public class ProductController {
@GetMapping("/{category}/{productId}")
public String getProduct(@PathVariable String category, @PathVariable String productId,
@MatrixVariable(name = "color", pathVar = "productId", required = false) String color,
@MatrixVariable(name = "size", pathVar = "productId", required = false) String size) {
return "Category: " + category + ", Product ID: " + productId + ", Color: " + color + ", Size: " + size;
}
}
3.6.4 请求时的示例
GET http://localhost:8080/products/clothes/123;color=red;size=medium
服务器会从 URL 中提取矩阵变量 color 和 size 的值,并绑定到方法的相应参数上。
四、请求响应相关注解
4.1 @ResponseBody
4.1.1 介绍
@ResponseBody 注解用于将方法的返回值直接作为 HTTP 响应体返回给客户端,而不是进行视图解析。
通常与 @RestController 配合使用(@RestController 相当于 @Controller 和 @ResponseBody 的组合)。
4.1.2 使用场景
当需要返回 JSON、XML 等数据格式给客户端时使用,例如返回用户信息列表、产品信息等。
4.1.3 简单使用示例
@RestController
public class ResponseBodyController {
@GetMapping("/data")
@ResponseBody
public List<String> getData() {
return Arrays.asList("Data1", "Data2", "Data3");
}
}
4.1.4 请求时的示例
客户端发起请求:
GET http://localhost:8080/data
服务器会将 getData 方法返回的列表数据以 JSON 格式直接作为响应体返回给客户端。
如果不使用 @ResponseBody ,控制器方法的返回值会根据类型不同,被 Spring MVC 以视图解析、携带模型数据渲染视图或重定向等方式进行处理。
4.2 @ResponseStatus
4.2.1 介绍
@ResponseStatus 注解用于指定方法返回时的 HTTP 状态码。
可以在方法或类上使用,用于控制响应的状态信息。
4.2.2 使用场景
当需要自定义响应的状态码时使用。
例如在创建资源成功后返回 201 Created 状态码,在资源不存在时返回 404 Not Found 状态码等。
4.2.3 简单使用示例
@RestController
public class StatusController {
@GetMapping("/status")
@ResponseStatus(HttpStatus.CREATED) // 201
public String createResource() {
return "Resource created";
}
}
4.2.4 请求时的示例
客户端发起请求:
GET http://localhost:8080/status
服务器会返回 201 Created 状态码和响应体 "Resource created"。
五、异常处理相关注解
5.1 @ExceptionHandler
5.1.1 介绍
@ExceptionHandler 注解用于在控制器类中定义异常处理方法,当控制器中的方法抛出指定类型的异常时,会自动调用该注解标注的方法进行处理。
5.1.2 使用场景
当需要对控制器中可能出现的异常进行统一处理,避免异常信息直接暴露给客户端,同时给客户端返回友好的错误信息时使用。
5.1.3 简单使用示例
@RestController
@RequestMapping("/exception")
public class ExceptionController {
@GetMapping("/error")
public String throwException() {
throw new RuntimeException("Something went wrong!");
}
@ExceptionHandler(RuntimeException.class)
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
public String handleRuntimeException(RuntimeException ex) {
return "Error: " + ex.getMessage();
}
}
5.1.4 请求时的示例
GET http://localhost:8080/exception/error
当 throwException 方法抛出 RuntimeException 时,会自动调用 handleRuntimeException 方法进行处理,并返回相应的错误信息和 500 Internal Server Error 状态码。
5.2 @RestControllerAdvice
5.2.1 介绍
@RestControllerAdvice 是一个组合注解,相当于 @ControllerAdvice 和 @ResponseBody 的结合。
它用于定义全局的异常处理类,能够处理所有控制器中抛出的异常。
5.2.2 使用场景
当需要对整个应用中的控制器异常进行统一处理时使用,避免在每个控制器中重复编写异常处理代码。
5.2.3 简单使用示例
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ResponseEntity<String> handleGlobalException(Exception ex) {
return new ResponseEntity<>("Global Error: " + ex.getMessage(), HttpStatus.INTERNAL_SERVER_ERROR);
}
}
5.2.4 请求时的示例
当任何控制器中的方法抛出 Exception 类型的异常时,都会被 GlobalExceptionHandler 类中的 handleGlobalException 方法捕获并处理,返回统一的错误响应。
六、其他注解
6.1 @CrossOrigin
6.1.1 介绍
@CrossOrigin 注解用于解决跨域请求的问题。
在前后端分离的开发中,由于浏览器的同源策略,不同源的请求会受到限制,使用该注解可以允许跨域访问。
6.1.2 使用场景
当前后端项目运行在不同的域名或端口时,前端页面向后端 API 发送请求会产生跨域问题,此时可以使用 @CrossOrigin 注解来解决。
6.1.3 简单使用示例
@RestController
@CrossOrigin(origins = "https://www.tqazy.com")
public class CrossOriginController {
@GetMapping("/cross")
public String crossOriginRequest() {
return "Cross - origin request allowed";
}
}
6.1.4 请求时的示例
前端页面(运行在 https://www.tqazy.com )发起请求:
GET http://localhost:8080/cross
由于在控制器上使用了 @CrossOrigin 注解,允许 https://www.tqazy.com 域名的跨域请求,所以该请求可以正常访问。
喜欢RESTful API风格的Controller中的常用注解这篇文章吗?您可以点击浏览我的博客主页 发现更多技术分享与生活趣事。