WordPress 倦意图片水印插件发布:轻松快捷控制图片水印
倦意图片水印 一款 WordPress 图片水印插件,由倦意原创,支持自动/手动添加水印、原图备份与恢复、在线 […]
随着 ai 的不断进化,claudecode、codex 等爆火,vibecodig 这个概念传播的越来越广了。现在一个不懂代码的人,通过 agent 工具也能实现自己想要的功能。
上个月codex 推出了双倍额度,正好无聊,于是便借此搬迁了博客,并且魔改了下主题。总体体验来说,codex 用起来还是不错的,至于和 claudecode 比起来,这就不知道了,因为 cc 的封号机制,好长时间没有用过了。
不过 codex 的前端 ui 审美是真不行,只会一味的卡片封装再封装,实在是太丑了。后面使用了 google 的 mcp 工具(chrome-devtools),对一些比较好看的博客进行了学习,后面进总算看的过去了。另外,codex 隔几次就会重置额度,体验确实不错。
随着 openclaw 的爆火,全民开始养龙虾,并且以此推动了 token 的发展,各厂家陆续推出专属 coding plan 等产品。
装龙虾已经成为了一种潮流,一种赚钱方式,当时全女团队上门帮忙装龙虾的图片还爆火过,说没有人进行炒作我是不信的。
周围不是计算机专业的人都曾询问过,让我帮忙装龙虾,不过我还是拒绝了。当时的氛围已然有一种没有装上龙虾就是跟不上时代的感觉。然而装完龙虾后的 token 费用等,却几乎没有被强调过。
大部分人在装完龙虾后不知道做什么,还有为养龙虾而费心费力。此外,龙虾背后的安全问题更是被忽略了。当龙虾完全掌控了电脑权限后,鬼知道会发生什么。不过后面又爆出来了安全问题,结果又一堆人花钱卸载龙虾。这一场风波还是挺离谱的。
不过龙虾的爆火却推动了另一种东西:token,即词元。
个人使用最多的就是 codex 了,由于 Antigravity 的歧视,claudecode 的使用额度对我来说还是太麻烦了,中转站更是很难依靠。
不过前几天 claudecode 又火了一次。由于打包时候的误操作,导致源码泄露,听说全是 ai 自己进行操作。所以进行 vibecoding 时候,代码等权限安全问题还是需要重视的。
我还是三月初接触到 codex 这类 agent 工具,由于之前使用的 copilot 基本能够解决代码问题,所以再也没有探索使用过其他工具了,比如 cursor 以及 claudecode。
三月 codex 的 app 出现了,于是便第一次体验了下。刚上手还是一脸懵逼的,毕竟之前从未了解过,只知道一点 agent 概念。后来才了解到 skill 还有 mcp 工具。
从我的理解来说,skill 就是包装过的提示词,可以让 ai 每次使用前先阅读 skill,知道应该如何操作。mcp 就是第三方应用的对外协议,可以让 ai 通过这个操作第三方应用。当然,这个纯属于我的小白理解。
最近各种 skill 爆火,将前女友、著名人物等进行蒸馏,变成 skill 使用,挺难绷住的。不过貌似有一些查找和精读文献 skill 貌似挺好用的。
此外,还有 openai 等推出的AGENT.md,相当于一个统一标准吧。在一个项目目录里,此文件用于告诉 ai 这个项目是什么,以及应该怎么操作等。等你换一个模型或者 agent 时候,依然可以通过阅读这个文件来了解项目,从而节省 token。
AI 的发展速度对我个人来讲还是太快了,大多数人已经告别了古法编程,许多公司面试还会询问是否使用过 agent 工具进行 ai 编程。
不过就业环境貌似变得更加艰巨,现在不仅要懂编程,还要会 ai。本是提升编码效率的工具,却变成了裁员。
还记得下面这句话:
你们搞大模型的就是码奸,你们已经害死前端兄弟了,还要害死后端兄弟,测试兄弟,运维兄弟,害死网安兄弟,害死ic兄弟,最后害死自己害死全人类
谁看到能够绷住。还有蒸馏同事的 skill。

忍不住问一句敢问路在何方~
linux 驱动结束后,又重新学了会 C++,跟着侯捷老师视频过了一遍,后面又学了下 STL 以及 现代C++。
学完后本想做个项目,可惜和嵌入式相关的实在太少了。于是又转头学起了 xv6。
此外,一直不知道研究哪方面,主要方向是图像识别。组里全是搞 yolo 的,还得自己找数据集,大一买的游戏本显存还不够,跑不动,实在太难了。
此外还有遥感方向识别,然后相比 yolo,遥感对我来说更是天书,233。
后面再多看点文献找找灵感吧,争取研二暑假前写完小论文,出去实习。
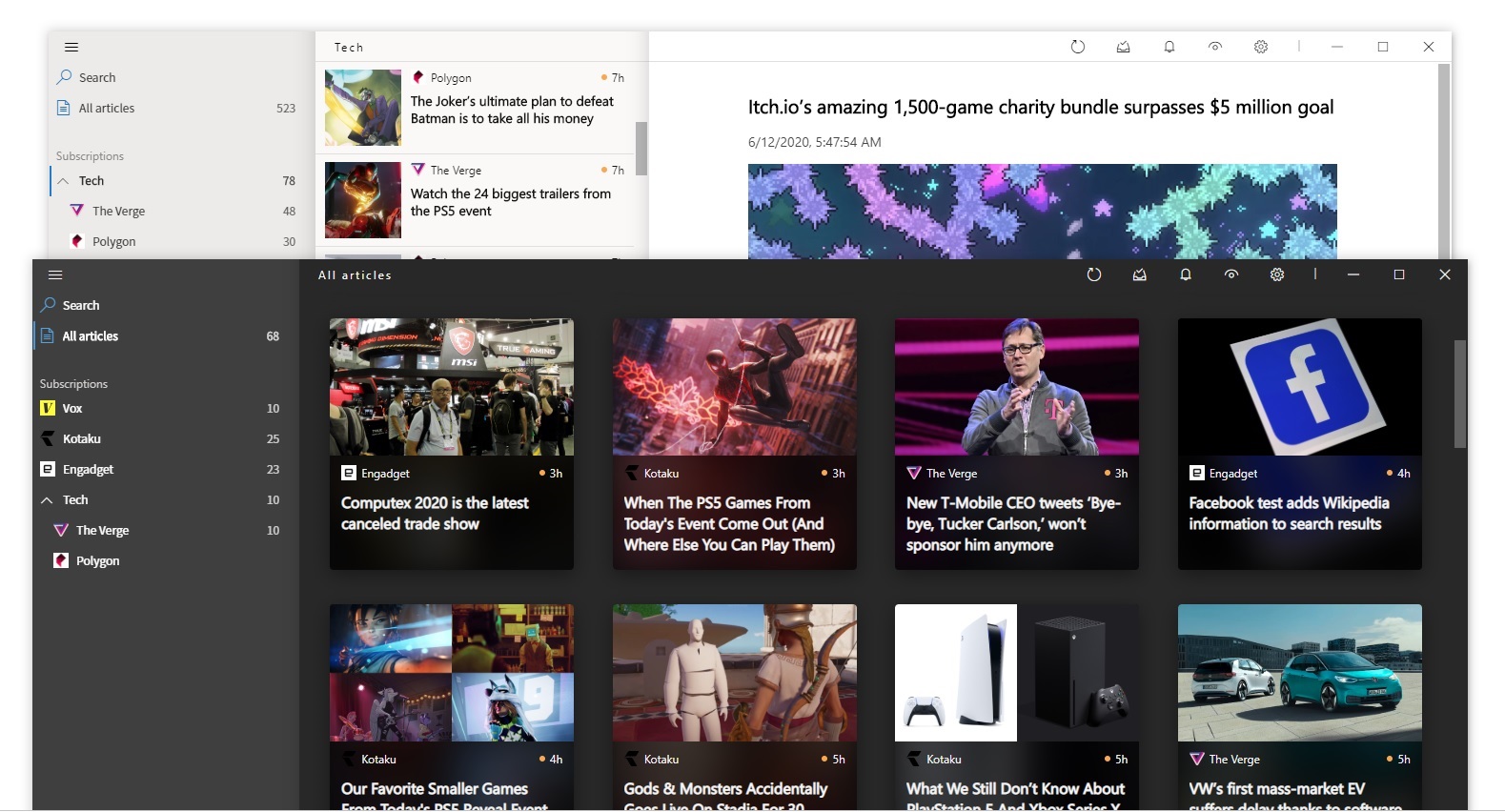
由于之前在网上搜寻到RSS订阅工具都差强人意,今天闲来无事,偶然发现了一款颜值非常高的开源免费RSS订阅器:Fluent Reader , 于是便想写一篇文章安利下
如果想要使用,微软商店直接搜索下载即可,也可以前往 GitHub 上下载,此仓库包含了APP端软件包
至于更多RSS订阅源可跳转相关链接处
RSS(Really Simple Syndication,真正简单的分发)是一种用于发布和订阅网站内容的数据格式和协议。它通过简单的 XML 格式来传递网站的文章、新闻、博客等信息,允许用户通过订阅器(RSSReader)获取网站内容的最新更新,而无需直接访问网站。
RSS 最早出现在 1999 年,由 Netscape 公司创立。随后,RSS 标准逐渐发展,演变为不同的版本和格式。常见的 RSS 版本包括 RSS 0.9x、RSS 1.0、RSS 2.0 和 Atom 等。
RSS 的工作原理如下:
RSS 的优点包括:
随着社交媒体和其他内容分发平台的兴起,RSS 的使用逐渐减少。然而,RSS 仍然被许多网站和博客用于提供内容更新,并且一些专门的订阅器应用程序仍然广泛使用,满足了一部分用户对于个性化内容订阅的需求。

GitHub地址:Fluent Reader
RSS入门指南:高效获取信息,你需要这份 RSS 入门指南 - 少数派 (sspai.com)
使用体验:Windows平台最美RSS阅读器-Fluent Reader上手体验 - 知乎 (zhihu.com)
友情提醒:卸载软件时,记得导出相关订阅源进行备份
又到了写年终总结的时候了。
每天一记的日记我肯定坚持不下去,但是每年一次的年终总结,我应该能坚持下。
万卷古今消永日,一窗昏晓送流年
在万卷书中消磨自己整日时光,南窗下让自己生命的河流静静地流过。
这首诗句是陆游写的,用来感叹读书对时间的消磨以及对内心的充实。
非常贴合2023年我的校园生活(并不是指读了许多书,hh)
2023年,应该算是大学中最稳定的一年了,也是最充实的一年。
没有初入校园的懵懂,也没有大三后期对人生该驶向何处的迷茫。
我可以拥有一定的时间去探索感兴趣的方向,也可以选择去一些风景名地来开阔自己的内心。
青春没有售价,一切皆在脚下
其实今年并没有去了很多地方,因为实在做不到真正的穷游,哈哈。
唯一的一次远门,也就是做了两小时高铁的南京,体验了下疫情解封后的疯狂。
也就是上面这篇文章里描述的那样,其他时候基本都是在当地以及附近玩玩了。
除了这个外,就是基本的三点一线了,偶尔出去下趟馆子,也就是下面这篇文章所述
没办法,今年发生的能够谈谈的基本都被写出来了,我也没法用来凑字数了。
如今,一到年底,各大APP都会争先推送各种总结报告,既然如此,我也给博客写一份年总报告吧。
在2023年这一年中,小E的小窝一共更新了 27篇文章,其中大部分都是技术文章。
相比文章,碎碎念 达到了惊人的 38条 ,平均每个月吐槽3次。果然,吐槽是人的本质。
不过好在文章数和碎碎念数量一样,说明我更新的也是挺频繁的。
除此之外,访客量达到了 349771,点击量则是 761959,emm,除去友链经常互访的小伙伴们,数据还是不错的,哈哈。
其实一开始也没想到会有这么多人访问,毕竟只是一个私人博客,也没啥营养东西。不过友链和B站教程视频倒是引流了不少,也算是一个不错的礼物——送给自己的博客。
因为博客是一时兴起搭建的,许多地方设置的不是很合理。
一开始我是打算用来记录生活和学习笔记等文章,确实做到了这一步。不过因为各种文章都发布在这一个博客中,导致比较杂乱。因此,我打算后面将学习记录以及教程文章全部搬迁到其他地方,而这个博客单纯当作一个记录和吐槽生活的地方。至于什么时候,应该得明年吧(确实是明年,hh)。
下面就是最重要的地方了。
每次写年终总结时都会觉得时间过得飞快,现在也一样。
刚搭建博客时候是大一暑假,现在已经到了大三寒假了。工作 or 考研是一个不得不面对的问题。这也是一个使人成长的问题。
友链里面的朋友们已经都开始实习了,而我现在却一点准备也没有,除了一个破简历,总结了大学所学的所有知识。
不过现如今,我的学历已经不够看了,因此,我选择了考研。当然,考研也是面向工作。
至于考公,一直从未出现在我的选择里。因为我也有一个年薪百万的IT梦,哈哈,开个玩笑。
今年考公的人数也在增加,恰巧是考研减少的人数。考公的难度和考研的难度,对我来说,应该是一样的,都很难。
既如此,不如先考研,如果运气好,考上了,到时候再考虑是考公或者工作。如果考不上,那么我估计会二战。如果运气好点,能够找到一个凑活的工作,那么便是边工作边二战了。
既然做了选择,下面就该努努力了。博客也该放一放了,毕竟没啥文章能写。有可能下一篇文章就是2024年的年终总结了,哈哈。希望一战上岸吧(虽然上岸后还有无数个岸)
单纯的对一些经常用的 git 命令进行总结,方便以后查询使用,没啥营养
git add # 提交到 暂存区
git commit -m "commnet" # 提交到 版本库
git branch -M main # 重新命名分支
git remote add origin # 添加远程仓库
git pull origin master # 从名为 origin 的远程仓库的 master 分支拉取最新的提交,并将其合并到当前分支
git push origin main # 将本地仓库的文件push到远程仓库(若 push 不成功,可加 -f 进行强推操作)
git diff read.txt # 查看文件变化git reset --hard HEAD^ # 恢复到上一个版本
git reset --hard HEAD~10 # 恢复到网上10个版本
git reset --hard commitID # 恢复到指定commit版本git restore # 工作区
git restore --staged # 暂存区,工作区需要执行上一步 add
git reset --hard HEAD^ # 工作区、暂存区、本地仓库都回退 commitrm file
git add file
git commit -m ""git branch test # 创建分支 test
git branch # 查看当前分支
git switch -c test # 创建test分支,然后切换到test分支 git branch test git checkout test
git switch master # 切换
git merge test # 合并指定分支到当前分支
git merge --no-ff -m "no-ff" test # 禁用快进(fast-forward)合并,强制创建一个新的合并提交
git branch -d test # 删除分支
git branch -D test # 强制删除
git log --graph # 查看分支合并图git stash save "Your stash message" # 保存工作进度
git stash list # 查看 stash 列表
git stash apply [] # 应用
git stash drop [] # 删除
git stash pop [] # 应用并删除
git cherry-pick # 将一个或多个提交从一个分支应用到另一个分支git remote -v # 查看远程库的信息
git switch -c dev origin/dev # 本地创建一个新分支 dev,并将其设置为跟踪远程仓origin/dev 分支
git branch -u origin/dev dev # 本地分支 dev 设置为跟踪远程仓库的 origin/dev 分支
git push origin master # 将本地仓库文件push到远程(若push不成功,可加-f进行强推)
git pull origin master # 从远程仓库origin的master分支拉取最新提交,并将其合并到当前分支
git rebase # 把本地未push的分叉提交历史整理成直线标签总是和某个commit挂钩。如果这个commit既出现在master分支,又出现在dev分支,那么在这两个分支上都可以看到这个标签。
git tag v1.0 # 打一个新标签V1.0,默认是打在最新提交的commit上
git log --pretty=oneline --abbrev-commit # 每一行包含了一个提交的简略哈希和提交信息
git tag v0.9 f52c633 # 在特点commit上打标签
git tag -a v0.1 -m "v0.1 released" 1094adb # 创建带有说明的标签,用-a指定标签名,-m指定说明文字
git tag # 查看所有标签
git show v0.9 # 查看标签信息,标签不是按时间顺序列出,而是按字母排序
git tag -d v0.1 # 删除标签
git push origin v1.0 # 推送标签到远程
git push origin --tags # 一次性推送全部尚未推送到远程的本地标签
git push origin -d tag tagName # 删除一个远程标签
git ls-remote --tags origin # 查看删除远程tags执行效果发现两个多月没写文章了,不过考试月也没啥好写的。
最近大模型这么火,正好有个项目用到,于是便水一篇教程吧。
此篇教程为 科大讯飞的星火大模型 部署教程,部署完成后即可与智能助手进行聊天。
这里是关于部署到服务器端,如果有其他需求可以查看官方文档。
大语言模型 (英语:large language model,LLM) 是一种语言模型,由具有许多参数(通常数十亿个权重或更多)的人工神经网络组成,使用自监督学习或半监督学习对大量未标记文本进行训练[[1]](https://zh.wikipedia.org/wiki/大型语言模型#cite\_note-1)。
大型语言模型在2018年左右出现,并在各种任务中表现出色[[2]](https://zh.wikipedia.org/wiki/大型语言模型#cite\_note-Manning-2022-2)。
尽管这个术语没有正式的定义,但它通常指的是参数数量在数十亿或更多数量级的深度学习模型[[3]](https://zh.wikipedia.org/wiki/大型语言模型#cite\_note-extracting-3)。
大型语言模型是通用的模型,在广泛的任务中表现出色,而不是针对一项特定任务(例如情感分析、命名实体识别或数学推理)进行训练[[2]](https://zh.wikipedia.org/wiki/大型语言模型#cite\_note-Manning-2022-2)。
尽管在预测句子中的下一个单词等简单任务上接受过训练,但发现具有足够训练和参数计数的神经语言模型可以捕获人类语言的大部分句法和语义。
此外大型语言模型展示了相当多的关于世界的常识,并且能够在训练期间“记住”大量事实[[2]](https://zh.wikipedia.org/wiki/大型语言模型#cite\_note-Manning-2022-2)。
参考资料:llm - 搜索 (wikipedia.org)
首先前往科大讯飞的星火大模型官网 讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)
进行注册,然后领取大模型的API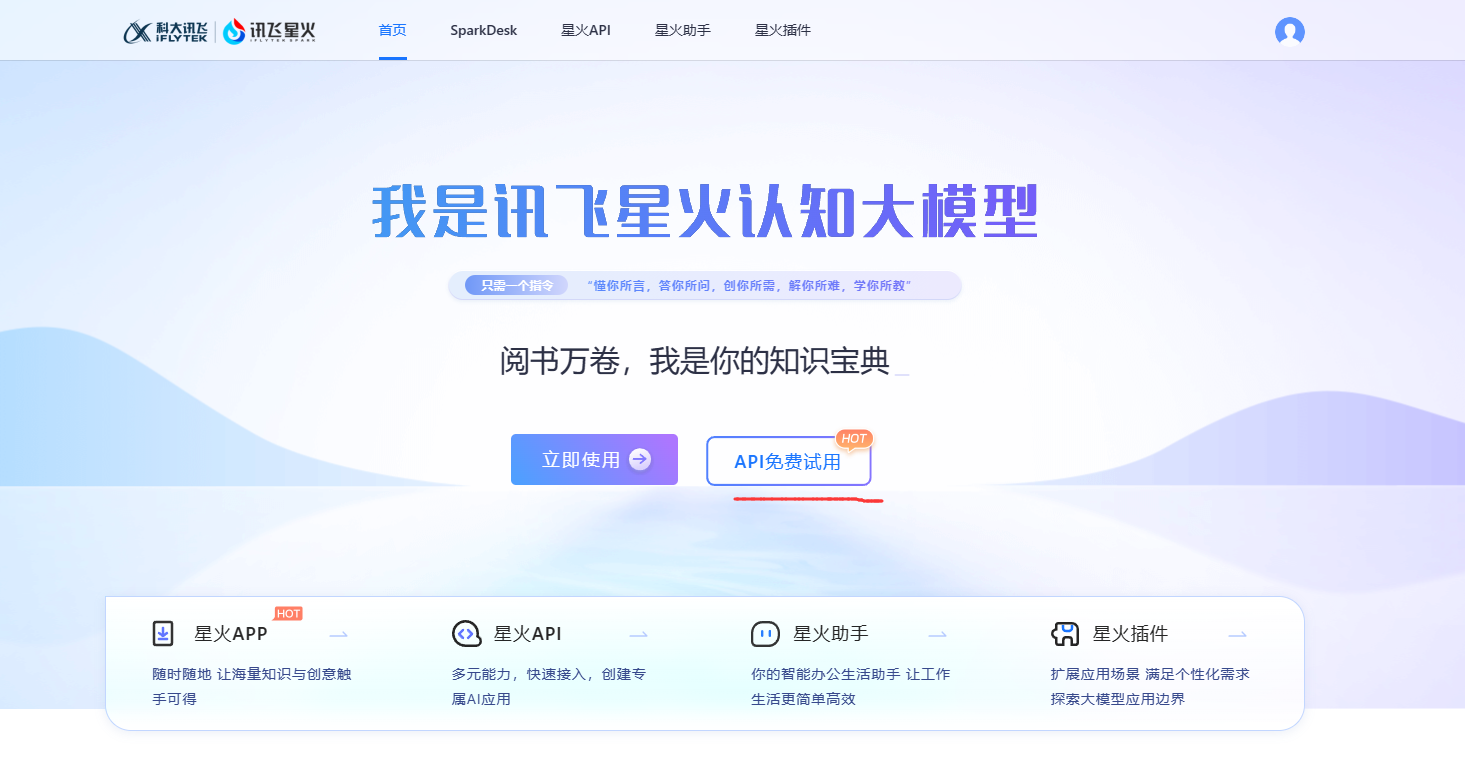
这里选择 API免费试用 ,然后进入如下页面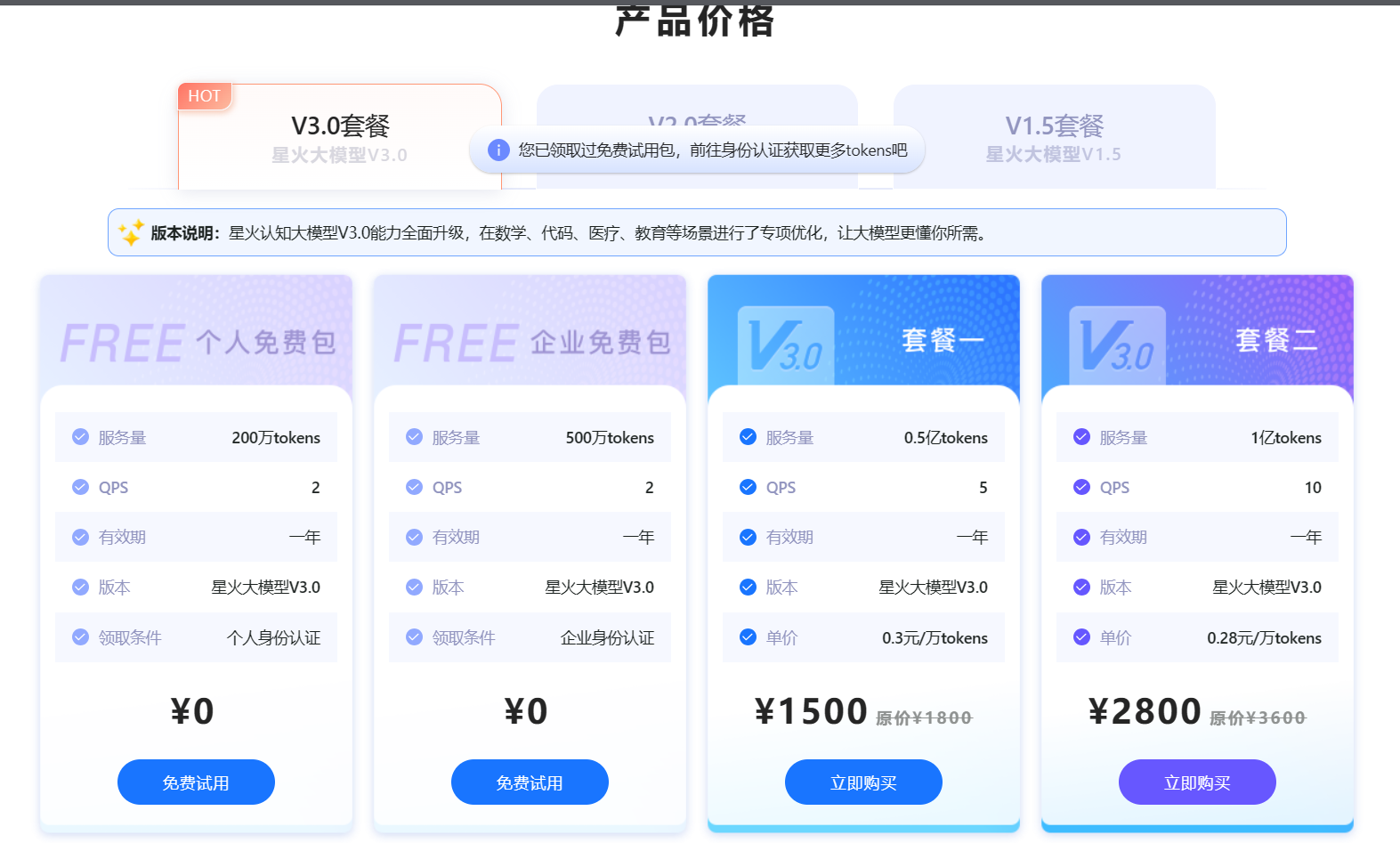
选择第一个 个人免费包免费试用 。等到领取成功后,后台会有如下界面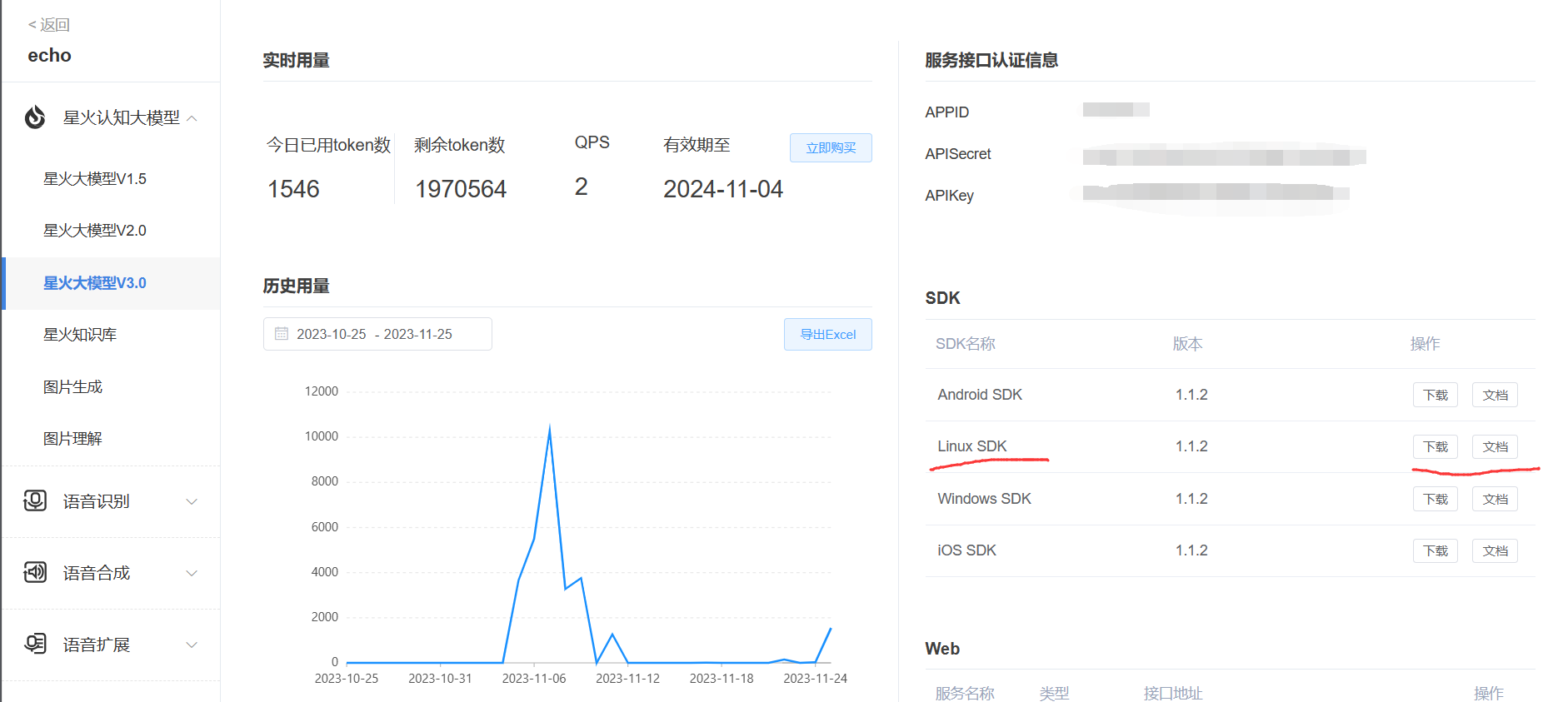
这里的 APPID 、APISecret 、APIKey 就是接口信息,后面会用到。
进入上面页面后,点击 Linux SDK 右边的下载按钮。将会下载SDK包,感兴趣的也可以点击文档查看使用教程
下载完成后传到服务器,使用解压命令解压包
unzip Spark3.0\_Linux\_SDK\_v1.1.zip然后进入解压出来的包 Spark3.0\_Linux\_SDK\_v1.1 , 里面应该包含如下文件
root@echofree:/opt# cd Spark3.0\_Linux\_SDK\_v1.1/
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1# ls
build include lib src进入 lib 目录,里面会有一个相关的调用库
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1# cd lib/
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1/lib# ls
libSparkChain.so这里为了方便点,直接采用暴力方法,将库文件 libSparkChain.so 复制到 /usr/lib 下
cp libSparkChain.so /usr/lib进入 src 目录,会有一个 demo.cpp 文件,进入此文件,修改如下信息
int initSDK()
{
// 全局初始化
SparkChainConfig \*config = SparkChainConfig::builder();
config->appID("appID") // 你的appid
->apiKey("apiKey") // 你的apikey
->apiSecret("apiSecret"); // 你的apisecret
// ->logLevel(0)
// ->logPath("./aikit.log");
int ret = SparkChain::init(config);
printf(RED "\ninit SparkChain result:%d" RESET,ret);
return ret;
}将这里的 三个API配置信息改为自己的即可。
配置完成后就要测试连接了,使用 GNU 编译套件进行编译,命令如下
g++ -Iinclude src/demo.cpp -o demo -lSparkChain -lstdc++ -lpthread如果你会 Makefile 的话,也可以复制下面的进行编译
CC = g++
CFLAGS = -Iinclude
LIBS = -lSparkChain -lstdc++ -lpthread
SRC = src/server.cpp
OUTPUT = demo
all: $(OUTPUT)
$(OUTPUT): $(SRC)
$(CC) $(CFLAGS) -o $@ $^ $(LIBS)
clean:
rm -f $(OUTPUT)如果一切正常,文件夹下会生成一个可执行文件 demo
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1# ls
build demo files include lib src运行看看
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1# ./demo
######### llm Demo #########
init SparkChain result:0
######### 同步调用 #########
syncOutput: assistant:Hello
syncOutput: assistant:こんにちは
######### 异步调用 #########
0:assistant:Hello:myContext
2:assistant::myContext
tokens:1 + 5 = 6
0:assistant:こ:myContext
1:assistant:んに:myContext
1:assistant:ちは (:myContext
1:assistant:Konnichi:myContext
2:assistant:wa):myContext
tokens:12 + 10 = 22很好,配置完成!
下面就要给他加互动功能了,毕竟大模型不能进行交互聊天,那还要他做什么
修改 demo.cpp 文件,内容如下
记得修改下 API信息哦
#include "../include/sparkchain.h"
#include
#include
#include
#include
#include
#define GREEN "\033[32m"
#define YELLOW "\033[33m"
#define RED "\033[31m"
#define RESET "\033[0m"
using namespace SparkChain;
using namespace std;
// async status tag
static atomic\_bool finish(false);
// result cache
string final\_result = "";
class SparkCallbacks : public LLMCallbacks
{
void onLLMResult(LLMResult \*result, void \*usrContext)
{
int status = result->getStatus();
printf(GREEN "%d:%s:%s:%s \n" RESET, status, result->getRole(), result->getContent(), usrContext);
final\_result += string(result->getContent());
if (status == 2)
{
printf(GREEN "tokens:%d + %d = %d\n" RESET, result->getCompletionTokens(), result->getPromptTokens(), result->getTotalTokens());
finish = true;
}
}
void onLLMEvent(LLMEvent \*event, void \*usrContext)
{
printf(YELLOW "onLLMEventCB\n eventID:%d eventMsg:%s\n" RESET, event->getEventID(), event->getEventMsg());
}
void onLLMError(LLMError \*error, void \*usrContext)
{
printf(RED "onLLMErrorCB\n errCode:%d errMsg:%s \n" RESET, error->getErrCode(), error->getErrMsg());
finish = true;
}
};
int initSDK()
{
// 全局初始化
SparkChainConfig \*config = SparkChainConfig::builder();
config->appID("appID") // 你的appid
->apiKey("apiKey") // 你的apikey
->apiSecret("apiSecret"); // 你的apisecret
// ->logLevel(0)
// ->logPath("./aikit.log");
int ret = SparkChain::init(config);
printf(RED "\ninit SparkChain result:%d" RESET,ret);
return ret;
}
void syncLLMTest()
{
cout << "\n######### 同步调用 #########" << endl;
// 配置大模型参数
LLMConfig \*llmConfig = LLMConfig::builder();
llmConfig->domain("generalv3");
llmConfig->url("ws(s)://spark-api.xf-yun.com/v3.1/chat");
Memory\* window\_memory = Memory::WindowMemory(5);
LLM \*syncllm = LLM::create(llmConfig, window\_memory);
// Memory\* token\_memory = Memory::TokenMemory(500);
// LLM \*syncllm = LLM::create(llmConfig,token\_memory);
int i = 0;
//const char\* input = "";
while (1)
{
char input[256]; // 定义一个足够大的字符数组来接收用户输入
printf("请输入问题 (输入 'q' 退出):");
scanf("%s", input);
if (strcmp(input, "q") == 0) {
break; // 如果输入是 'q',则退出循环
}
// 同步请求
LLMSyncOutput \*result = syncllm->run(input);
if (result->getErrCode() != 0)
{
printf(RED "\nsyncOutput: %d:%s\n\n" RESET, result->getErrCode(), result->getErrMsg());
continue;
}
else
{
printf(GREEN "\nsyncOutput: %s:%s\n" RESET, result->getRole(), result->getContent());
}
}
// 垃圾回收
if (syncllm != nullptr)
{
LLM::destroy(syncllm);
}
}
void uninitSDK()
{
// 全局逆初始化
SparkChain::unInit();
}
int main(int argc, char const \*argv[])
{
cout << "\n######### llm Demo #########" << endl;
// 全局初始化
int ret = initSDK();
if (ret != 0)
{
cout << "initSDK failed:" << ret << endl;
return -1;
}
syncLLMTest(); // 同步调用
// 退出
uninitSDK();
return 0;
}如果你仔细观察,会发现少了一部分代码。
星火大模型的接口调用给了两种方式,一种是同步,一种是异步
这里我用的是同步,所有文字都输出完,才会打印在终端。
正常的大模型,应该都是异步调用,即慢慢打印出来,这里留给读者自己修改了。
下面看下运行效果
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1# ./demo
######### llm Demo #########
init SparkChain result:0
######### 同步调用 #########
请输入问题 (输入 'q' 退出):徐州天气怎么样
syncOutput: assistant:今天徐州市的天气是多云,气温在3℃到11℃之间,有点冷。东风4-5级,湿度为53%。空气质量良好,PM2.5指数为60。在这样的天气条件下,适宜旅游、钓鱼和户外运动,但要注意保暖。同时,感冒较易发生,请注意保持干净整洁的环境和清新流通的空气。
请输入问题 (输入 'q' 退出):你是什么
syncOutput: assistant:您好,我是科大讯飞研发的认知智能大模型,我的名字叫讯飞星火认知大模型。我可以和人类进行自然交流,解答问题,高效完成各领域认知智能需求。
请输入问题 (输入 'q' 退出):q
root@echofree:/opt/Spark3.0\_Linux\_SDK\_v1.1#效果还是不错的。
既然一切都配置ok了,那肯定得进行应用开发了,这里来个小demo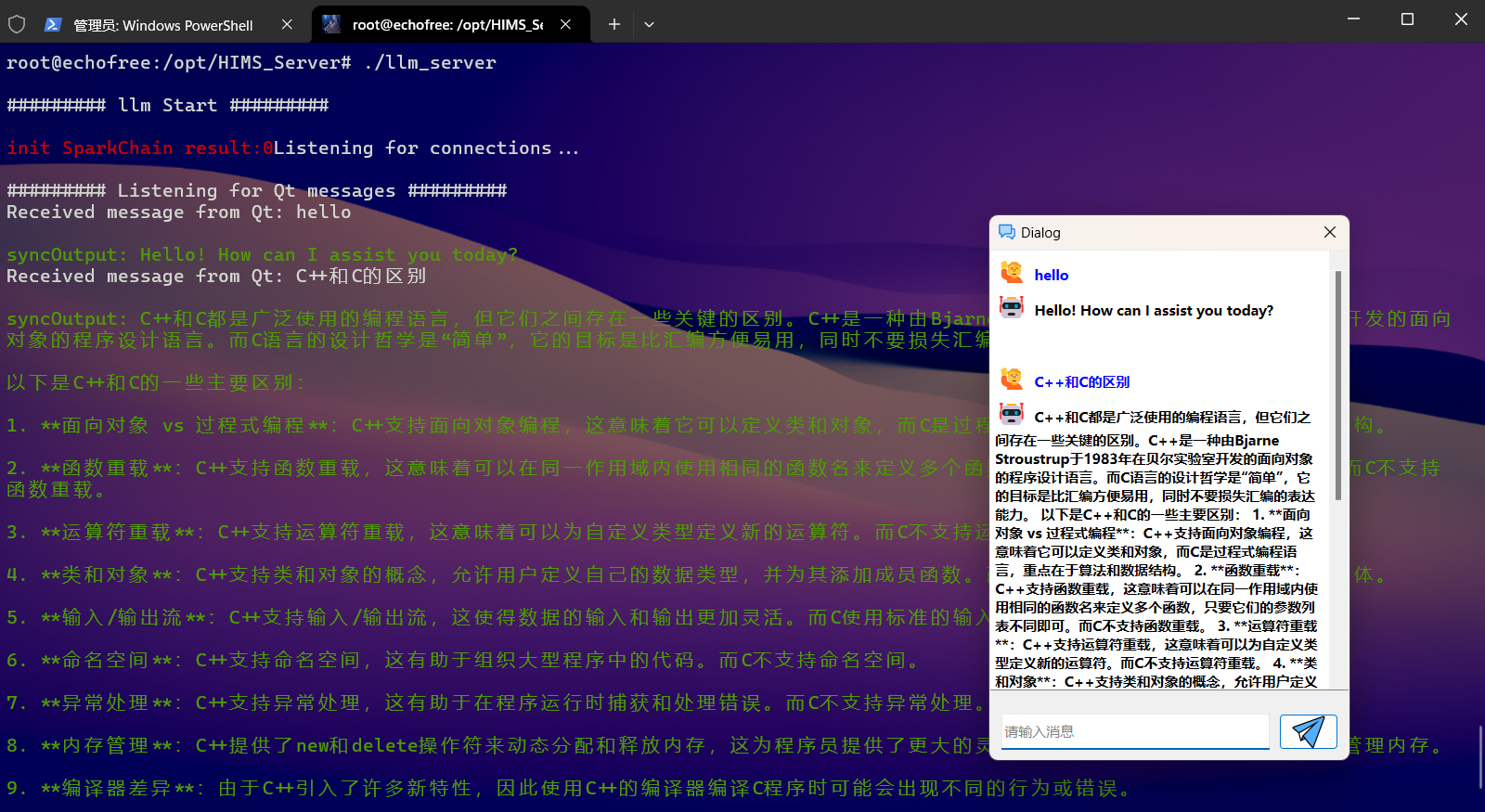
这里是使用 Qt 开发的一个非常质朴的聊天界面,也就是开头所说的项目中正好用到大模型的地方。由于时间紧张,技术能力有限,就直接搬上去了。
具体原理就是使用 Linux的 socket 和 多线程 与界面进行通信。服务器端负责接收客户端的信息并进行回复。
由于技术有限,并且考试月繁忙,等到有空闲时间了,再写个单独的交互界面。