未完待续
包和模块是Python语言封装功能和组织程序集的解决方案,类似Java中的package和C#中的namespace,将固定功能模块的代码聚合在一起,提高程序的复用性和可维护性。
模块和包在不同环境下位置和作用范围也不一样,本文建议和Python全局环境和虚拟环境(venv) 一文搭配食用。
本文基于Python3.13
每一个.py文件都是一个模块,每个模块中可以包含变量,函数,类等内容,模块,多用于封装固定功能的代码,每个模块都是一个工具,模块可以提升代码的可维护性和可复用性,还能避免命名冲突。
python中的模块分为三种:标准库模块,自定义模块和第三方模块
标准库模块
随着Python自带的一些模块,位于Python安装目录的\Lib下(site-packages中的除外),有些是C语言实现的,不能看到源码(Pycharm IDE会为我们准备存根文件,里面仅有注释)也叫内置模块,剩下是python实现,可见源码,叫做非内置模块,例如:copy, os, math, sys, time等都是标准库模块,其中的math, sys, time就是内置模块,copy, os就是非内置模块
有些模块是用包进行组织的,包的概念后面会有介绍
python提供了标准库文档用于参考:https://docs.python.org/zh-cn/3.14/py-modindex.html
自定义模块
是我们为了实现功能自己编写的模块
第三方模块
通常位于Python安装目录的\Lib\site-packages,引用别人写好的现成的功能,往往使用包来引入,通常使用pip进行管理
模块的命名要符合标识符的命名规则,模块名(文件名)大小写敏感,最重要的是不能与标准库模块重名,否则引入时,会被与之重名的标准库模块顶替(类似Java中的双亲委派)
例如定义两个模块在根路径下,order和pay
order.py
max_amount = 5000_0000 def create_order ( ) : print ( 'create_order' ) def cancel_order ( ) : print ( 'cancel_order' ) def info ( ) : print ( 'order info' ) pay.py
timeout = 300 def wechat_pay ( ) : print ( 'wechat_pay' ) def alipay_pay ( ) : print ( 'alipay_pay' ) def info ( ) : print ( 'pay info' ) 在根目录建一个新的mytest模块,引入刚刚建的两个模块,总共有5种常见的引入方式,在不同的场景使用适合的方式进行导入。
引入模块中的全部成员,要使用模块中的成员,需要用模块名.的方式访问
import orderimport payprint ( order. max_amount) order. create_order( ) order. cancel_order( ) order. info( ) print ( pay. timeout) pay. alipay_pay( ) pay. wechat_pay( ) pay. info( ) 可以为引入的模块取一个别名,通过别名.访问,但是别名需要符合标识符的命名规范
import order as oimport pay as pprint ( o. max_amount) o. create_order( ) o. cancel_order( ) o. info( ) print ( p. timeout) p. alipay_pay( ) p. wechat_pay( ) p. info( ) 之前的方式都是将整个模块引入,通过from 模块名 import 具体内容,...可以将模块中的部分成员引入,并可以不需经过模块,直接调用
from order import max_amount, create_order, cancel_order, infofrom pay import timeout, wechat_pay, alipay_pay, infoprint ( max_amount) print ( timeout) create_order( ) cancel_order( ) alipay_pay( ) wechat_pay( ) info( ) 但是有一个问题,两个模块中有重名的成员时,后引入的会覆盖先引入的,例如上面程序运行结果就是:info()执行的是pay模块中的info()
50000000300create_ordercancel_orderalipay_paywechat_paypay info在3的基础上,通过这种方式,将重名成员设置别名,避免冲突
from order import info as o_infofrom pay import info as p_infoo_info( ) p_info( ) ⚠️这是一种不被推荐的用法
引入模块中全部成员,但是和第1种不同的是,访问成员不需要通过模块名或别名,同样会出现重名成员后者覆盖前者的情况,而且和当前模块中声明的成员也可能无形中发生冲突,同样存在按照前后顺序覆盖
timeout = 0 from order import * from pay import * max_amount = 5 print ( timeout) print ( max_amount) alipay_pay( ) wechat_pay( ) create_order( ) cancel_order( ) info( ) 运行结果:timeout被pay.timeout覆盖,order.max_amount也会被max_amount覆盖,info()调用的是pay模块的info()
3005alipay_paywechat_paycreate_ordercancel_orderpay info在python中,可以通过__all__来控制from 模块名 import *引入哪些成员,且__all__仅针对from 模块名 import *的方式有效,__all__的值可以是列表或元组
例如将order.py修改成以下,被引入时,只能引入create_order, cancel_order两个函数
列表和元组中每个元素是字符串形式的属性名,不要把函数或变量等直接当成对象直接放进去
max_amount = 5000_0000 def create_order ( ) : print ( 'create_order' ) def cancel_order ( ) : print ( 'cancel_order' ) def info ( ) : print ( 'order info' ) __all__ = [ 'create_order' , 'cancel_order' ] 在mytest.py中再使用未引入的成员将报错
from order import * print ( max_amount) create_order( ) cancel_order( ) info( ) Traceback (most recent call last): File "D:\python-lang-test\test1\mytest.py", line 60, in <module> print(max_amount) ^^^^^^^^^^NameError: name 'max_amount' is not definedProcess finished with exit code 1一个python项目由诸多模块构成,如果一个模块,是直接在python解释器后直接运行的,则这个模块就是主模块,类似Java中JVM从某个类的public static void main(String[] args)方法开始执行。
比如这样运行某个python项目,mytest.py模块就是主模块
D:\python-lang-test\test1\.venv\Scripts\python.exe D:\python-lang-test\test1\mytest.pypython中有一个特殊的变量:__name__,是一个字符串类型,该变量只有在主模块中出现时,才会被python解释器赋值为一个字符串:”__main__“,如果出现在了非主模块,则会被赋值为当前模块的名
同时,python代码运行时,一旦执行了import语句,被引入的模块代码就会开始自然从上向下执行,类似浏览器中执行js代码一样
例如:
mytest.py(主模块)
import sonprint ( '主模块执行-开始' ) print ( __name__) son. fun( ) son.py
print ( 'son模块执行-开始' ) def fun ( ) : print ( __name__) 运行结果就是上面说的那样:son模块print先执行了,然后主模块print后执行,而且__name__被解释器自动赋上对应的值
son模块执行-开始主模块执行-开始__main__son这样设计的用途是,可以对某个模块内自己实现的方法进行简单测试,类似Java中如果想在某个类中测试下刚刚写好的方法,就会随手就地写一个main方法然后main中直接启动自己写的方法,对python而言,可以将某个子模块最后加上这样一段if __name__ == '__main__'逻辑
print ( 'son模块执行-开始' ) def fun ( ) : print ( 'hello world' ) if __name__ == '__main__' : fun( ) 只要将当前模块直接启动,就能被当作主模块被解释器直接执行if __name__ == '__main__'下的逻辑实现临时测试,但是上线后当作为子模块被主模块引入,这段if逻辑则会被忽略
如果不加这段if逻辑,同样可以进行测试,但是需要上线前删除或注释测试代码,一旦忘记了,或者少注释了一段,误上线后就可能造成很大的影响,因此if __name__ == '__main__'至少可以使得程序更加安全
python中,包并不是一个和模块并列的东西,而是模块的进一步升级,一个包含__init__.py文件的文件夹就叫做包。通常将实现某个近似或相关功能的众多模块放在一个包中。
__init__.py是包的初始化文件,可以编写一些初始化逻辑(比如检查下当前环境等),还可以控制包被导入的内容,当包被导入时,__init__.py将被自动调用
模块是对功能的整理,包则是对模块的进一步整理,一个包中可以包含多个模块,也可以包含多个子包,包可以提升代码的可维护性和可复用性,便于管理大型项目。
python的包和模块类似,分为标准库包,自定义包和第三方包,封装标准库模块的自然就是标准库包,第三方包和自定义包同理。
定义包和定义模块规则也类似,报名符合标识符命名规范,不能和标准库包的名称冲突,且大小写敏感,一般用小写字母。
例如在项目根路径下,新建一个trade包,新建文件夹,名字和要建的包的包名一致,文件夹里面新建一个空的__init__.py文件,就成功创建了一个包
存在子包时,包名就是父子包用.连接,就像Java那样,例如:org.springframework.boot
project ├── .venv └── trade └── __init__.py在Pycharm IDE中,右键新建Python Package可以一气呵成将文件夹和__init__.py同时创建。
包中可以新建自己需要的模块,例如order.py,pay.py
project ├── .venv └── trade ├── order.py ├── pay.py └── __init__.py对于包来说,有五种和引入模块相似的方式,在语法和用法规则都是相同的,唯一改变的是模块名前要加上包名
模块 包 import 模块名 import 包名.模块名 import 模块名 as 别名 import 包名.模块名 as 别名 from 模块名 import 具体内容1, 具体内容2 … from 包名.模块名 import 具体内容1, 具体内容2 … from 模块名 import 具体内容1 as 别名1, 具体内容2 as 别名2 … from 包名.模块名 import 具体内容1 as 别名1, 具体内容2 as 别名2 … from 模块名 import * from 包名.模块名 import *
除了这五种和引入模块相似的语法,还有包特有的引入方式,新建一个testpg.py模块,测试这些方式
project ├── .venv ├── testpg.py └── trade ├── order.py ├── pay.py └── __init__.pytestpg.py
from trade import payfrom trade import orderprint ( pay. timeout) pay. wechat_pay( ) print ( order. max_amount) order. create_order( ) testpg.py
from trade import pay as pfrom trade import order as oprint ( p. timeout) p. wechat_pay( ) print ( o. max_amount) o. create_order( ) 包和模块的import *导入逻辑是不一样的,并不是将包下每个模块的所有成员都导入,而是和包的__init__.py文件有关,__init__.py中定义的内容才能被导入
trade/__init__.py
print ( 'trade init' ) a = 100 b = 200 testpg.py
from trade import * print ( a) print ( b) print ( timeout) print ( max_amount) 运行结果:导入包时打印trade init,且只有a b能获取到
trade init100200Traceback (most recent call last): File "D:\python-lang-test\test1\testpg.py", line 29, in <module> print(timeout) ^^^^^^^NameError: name 'timeout' is not definedProcess finished with exit code 1如果要通过包引入模块,可以在__init__.py文件中直接import模块,import也是一种定义
trade/__init__.py
print ( 'trade init' ) a = 100 b = 200 import orderimport paytestpg.py
from trade import * print ( a) print ( b) print ( order. max_amount) pay. wechat_pay( ) 还可以通过__all__以字符串指定包中的哪些可以被from 包名 import *的语法引入,无需import模块直接写模块名在列表中,例如下面程序,只有order模块和a b能被引入
trade/__init__.py
print ( 'trade init' ) a = 100 b = 200 __all__ = [ 'order' , 'a' , 'b' ] 直接导入包,通过包名访问成员,导入的包必须在__init__.py中import,通过__all__指定在这种引入方式上不生效
trade/__init__.py
print ( 'trade init' ) import orderimport paya = 100 b = 200 testpg.py
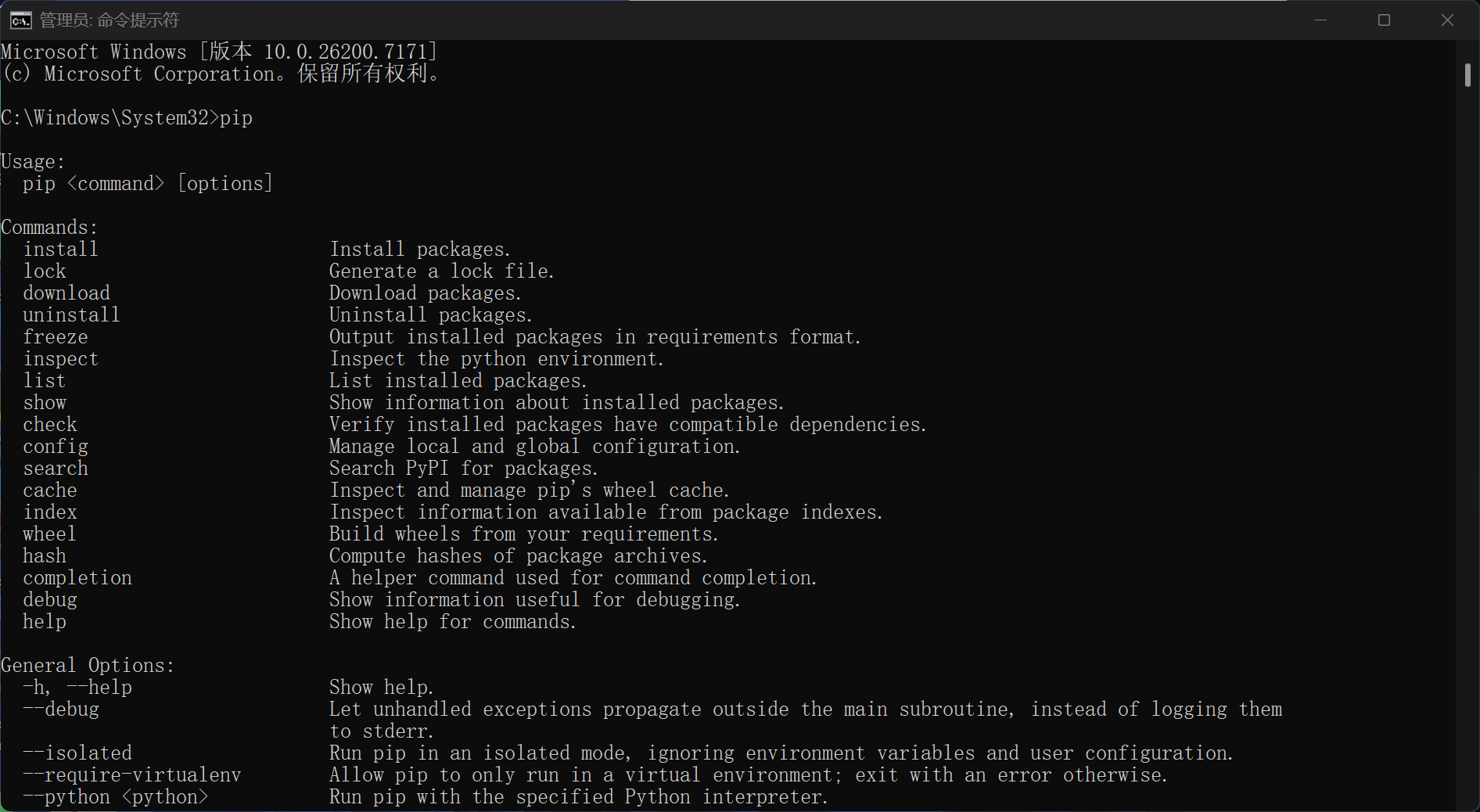
import tradetrade. order. create_order( ) print ( trade. a) pip是python自带的第三方包管理器,在windows下使用管理员权限打开CMD,输入pip回车,就能看到提示,pip实际上对应的是python安装目录的\Scripts\pip.exe文件
第三方包要到pypi的网站查找:https://pypi.org/ ,就像从maven中央仓库和npm查找Java或js的第三方依赖那样。
通过pip install命令安装第三方包,例如:
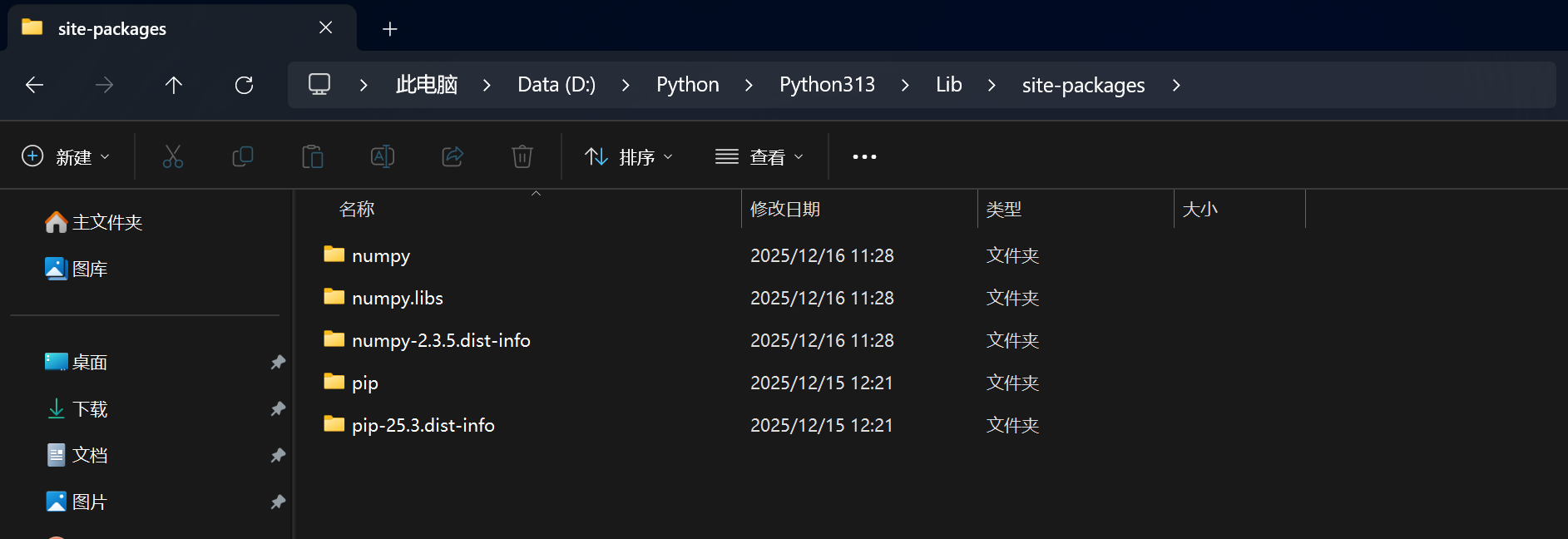
全局环境下,第三方包和模块会被安装在Python安装目录的\Lib\site-packages,一同被安装的还有numpy.libs,numpy-2.3.5.dist-info两个文件夹,numpy.libs是该包依赖的一些底层C实现的东西,numpy-2.3.5.dist-info里面则是描述文件
pip自己也是一个第三方包,在安装python环境时,一般默认安装pip,只要选择了默认安装,就会被安装在Lib\site-packages,Scripts\pip.exe最终就是在运行Lib\site-packages中的pip
pypi的服务器在境外,夜间可能访问不稳定,因此可以使用国内的一些镜像,例如清华大学pypi镜像:https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip安装时临时指定镜像
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple numpy永久指定镜像
⚠️如果在虚拟环境下执行,实现每个环境有不同的pip配置,虚拟环境目录下要提前创建好一个pip.ini文件,例如我的是:.venv\pip.ini
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simplepip还有以下几个常见用法:
命令 释义 pip install 包==版本号当前环境中,安装某个版本的某包 pip list当前环境中,已安装的所有第三方包 pip config list当前环境pip配置 pip uninstall ...从当前环境卸载指定的第三方包 pip config unset global.index-url恢复默认的pypi地址 pip install git+https://github.com/**从Git仓库地址安装包