浅谈前后端分离系统的SEO优化

开发一个系统,不管是从头开始,还是在已有系统上二次开发,从来都不是一蹴而就的事情。在上线以前总觉得已经做够了足够的测试,但是在上线之后还是会出现各种各样的问题。
有的问题,如果是新系统完全可以避免,正是由于是在已有系统上开发的为了兼容wp才会引入一系列的问题,这类问题主要是wp原生的一些机制兼容问题导致的包括但不限于:
1.wp固定连接的兼容
2.shortcode的解析处理
3.wp资源文件与新系统资源文件的路径兼容处理
4.wp启用插件的功能实现,邮件通知、micro-post、邮件发送、邮件模板等等
5.其他的未知问题
也有一部分是新系统天生的缺陷:seo不友好,搜索引擎爬虫无法获取网页内容,毕竟robot不会执行js,这个是前后端分离系统的必然缺陷。
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<link
rel="icon"
href="https://zhongxiaojie.cn/wp-content/uploads/2026/01/uugai.com-166111691272754-100x100.png"
sizes="32x32"
/>
<link
rel="icon"
href="https://zhongxiaojie.cn/wp-content/uploads/2026/01/uugai.com-166111691272754-200x200.png"
sizes="192x192"
/>
<link
rel="apple-touch-icon"
href="https://zhongxiaojie.cn/wp-content/uploads/2026/01/uugai.com-166111691272754-200x200.png"
/>
<meta
name="msapplication-TileImage"
content="https://zhongxiaojie.cn/wp-content/uploads/2026/01/uugai.com-166111691272754-300x300.png"
/>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta
name="description"
content="爱好广泛的女王 独立APP开发者 AI修理师 爬虫砖家 逆向工程师 人工智能 全栈工程师"
/>
<meta
name="keywords"
content="人工智能,机器学习,ml,逆向分析,信息安全,物联网,ida,uniapp,python,爬虫,妹子图,秀人集,java,vue"
/>
<meta
name="theme-color"
content="#ff4f87"
/>
<link
rel="manifest"
href="/manifest.json"
/>
<link
rel="stylesheet"
href="/vendor/enlighterjs.min.css"
/>
<link
rel="stylesheet"
href="/vendor/simple-microblogging.css"
/>
<title>obaby 𝐢𝐧⃝ void - 程序媛 / 独立开发者 / 智商不稳定的女神经</title>
<script type="module" crossorigin src="/assets/index-DFHpxK1A.js"></script>
<link rel="stylesheet" crossorigin href="/assets/index-CKljzL1r.css">
</head>
<body>
<div id="app"></div>
<script
defer
src="/vendor/enlighterjs.min.js"
></script>
<script defer src="/vendor/obaby.js"></script>
</body>
</html>
当然有人会比较在意这个东西,不是说这个东西不对。可能是自己没那么在乎吧,之前就曾经收到过数次关于seo友链不显示的问题,上次是搞页面静态化。
其实,在我的博客添加的友链,也并不是全部都不显示,毕竟还有其他的域名,zhongxiaojie.com 以及 oba.by等还是会显示完整的友链信息,这两个域名并没有切换到新的前后端分离的系统。所以,我博客的友链,相当于数个站都给友链做了多次链接,我不知道这个东西对于seo有没有作用,至于是有好处,还是有坏处,我并不清除,我自己并不是那么关注所谓的seo。如果觉得这样反而会出问题的,欢迎反馈,我会及时删除相关链接哈。
当然,这个东西有办法解决吗?答案自然是有,至于解决方法,那就是继续回归服务器渲染。
这解决方案真的是简单粗暴啊,合着这折腾来折腾去,又要弄回服务器渲染,这辛辛苦苦四十年,一夜回到解放前?
采用这种简单粗暴的方法来解决seo问题,显示不是本仙女的作风。既然是针对搜索引擎的,那就直接对搜索引擎做单独的处理就完了。检测ua,如果是收缩引起的ua返回服务器渲染之后的内容,如果是正常浏览(搜索引擎爬虫意外的ua)返回前后端分离的内容。
要实现服务器渲染,基于vue的可以参考nuxt.js(百度百科):
接下来也就简单了,创建nuxt项目,实现与frontend同样的页面路由和相关的页面文件布局。接口可以直接复用当前的接口,
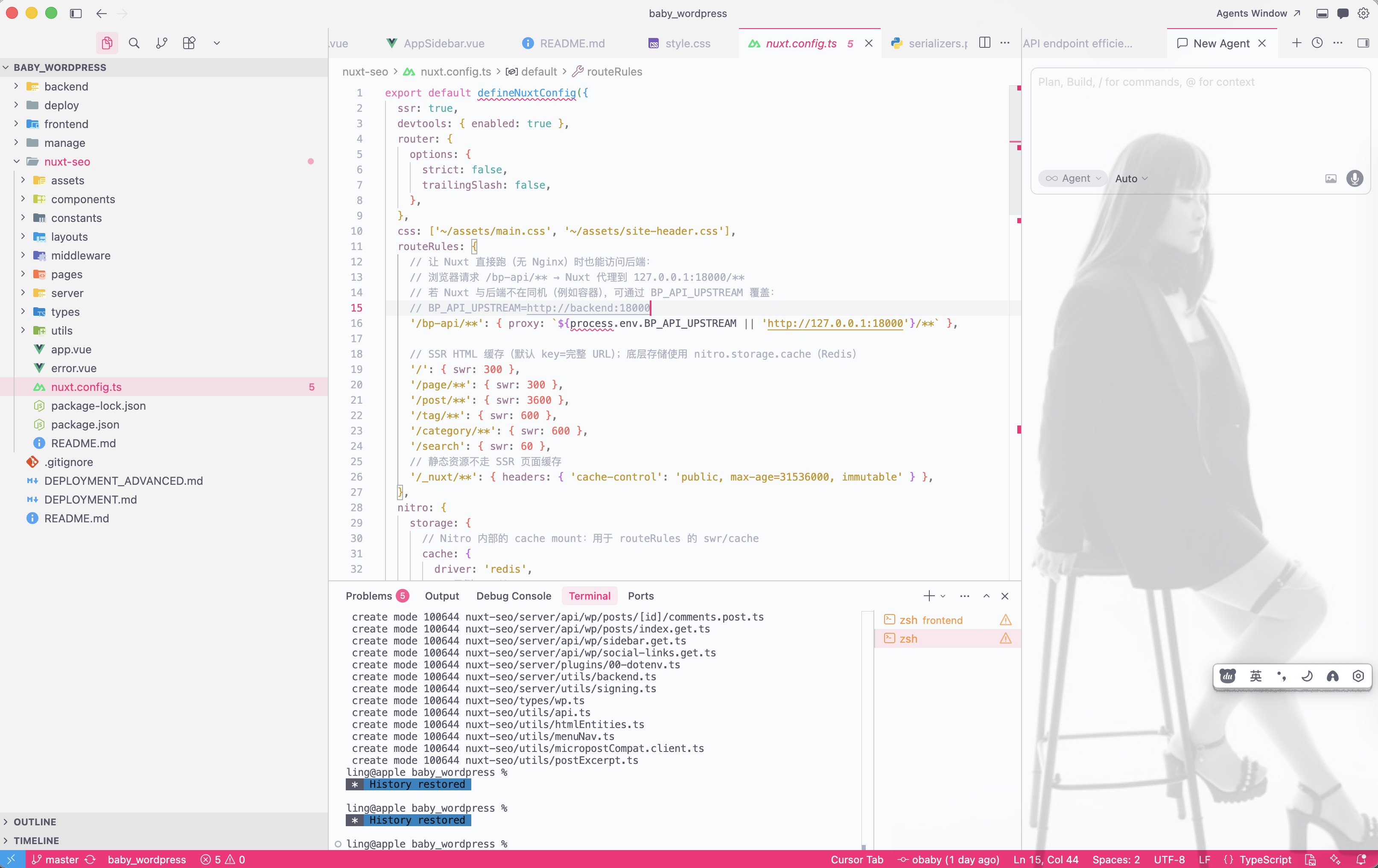
配置openresty的处理逻辑:
# -----------------------------------------------------------------------------
# Dynamic Rendering(SEO):爬虫 UA → Nuxt SSR;普通用户 → 现有 SPA
# - Nuxt SSR 服务建议监听 127.0.0.1:3000(可按需调整)
# - ?__ssr=1 可强制走 SSR(方便自测/排障)
# - 仅对“页面路由”生效,不影响 /assets、/vendor、/bp-api、WP 后台等
# -----------------------------------------------------------------------------
set $bp_force_ssr 0;
if ($arg___ssr = "1") {
set $bp_force_ssr 1;
}
set $bp_is_bot 0;
if ($http_user_agent ~* "(googlebot|bingbot|baiduspider|yandexbot|duckduckbot|slurp|sogou|360spider|bytespider|petalbot|facebookexternalhit|twitterbot|rogerbot|ahrefsbot|semrushbot|mj12bot)") {
set $bp_is_bot 1;
}
location @nuxt_ssr {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Uri $request_uri;
}
# 418 跳转技巧:在页面路由里 return 418 → error_page 转到 @nuxt_ssr
error_page 418 = @nuxt_ssr;
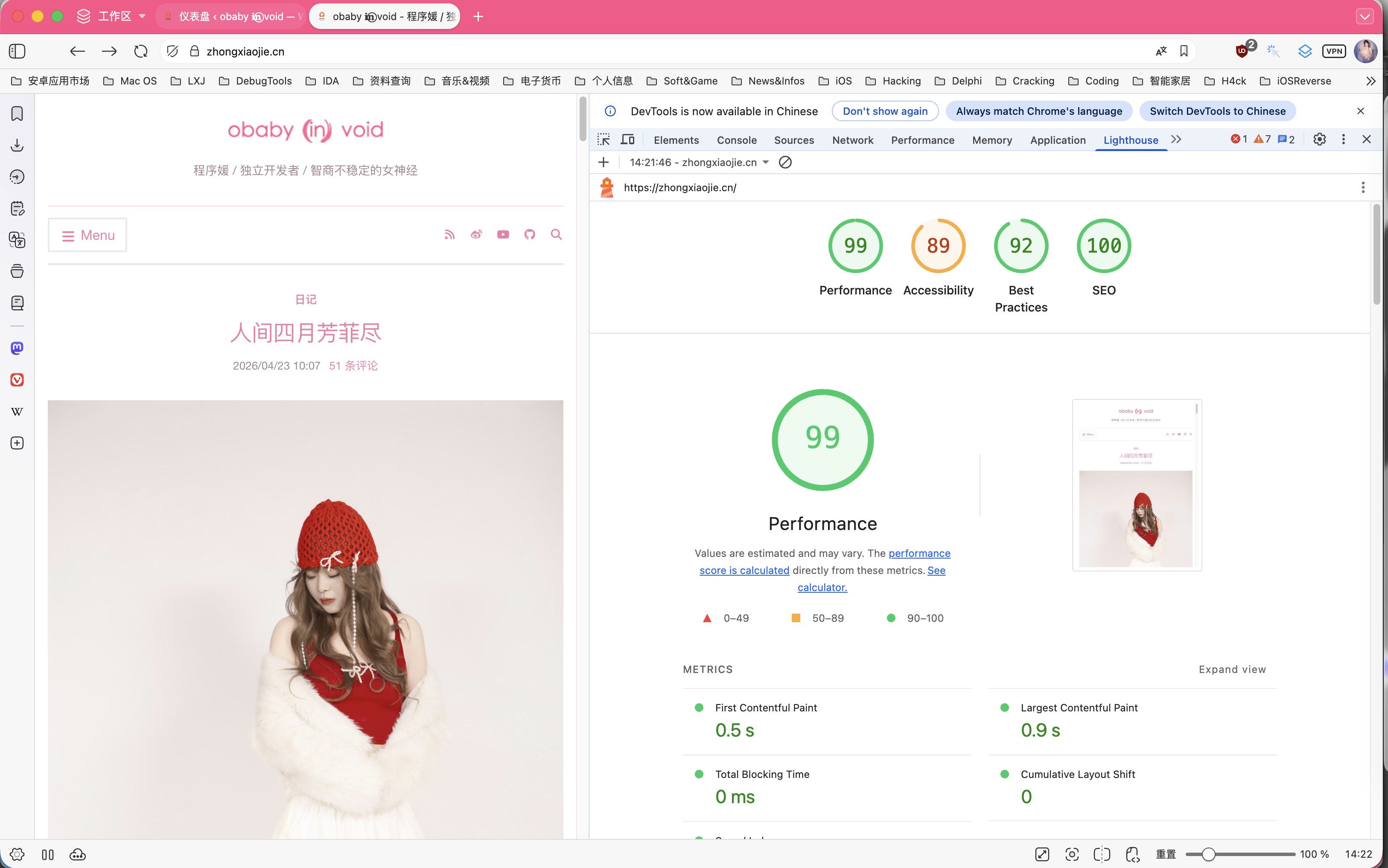
启动之后就可以查看服务器渲染的页面了:
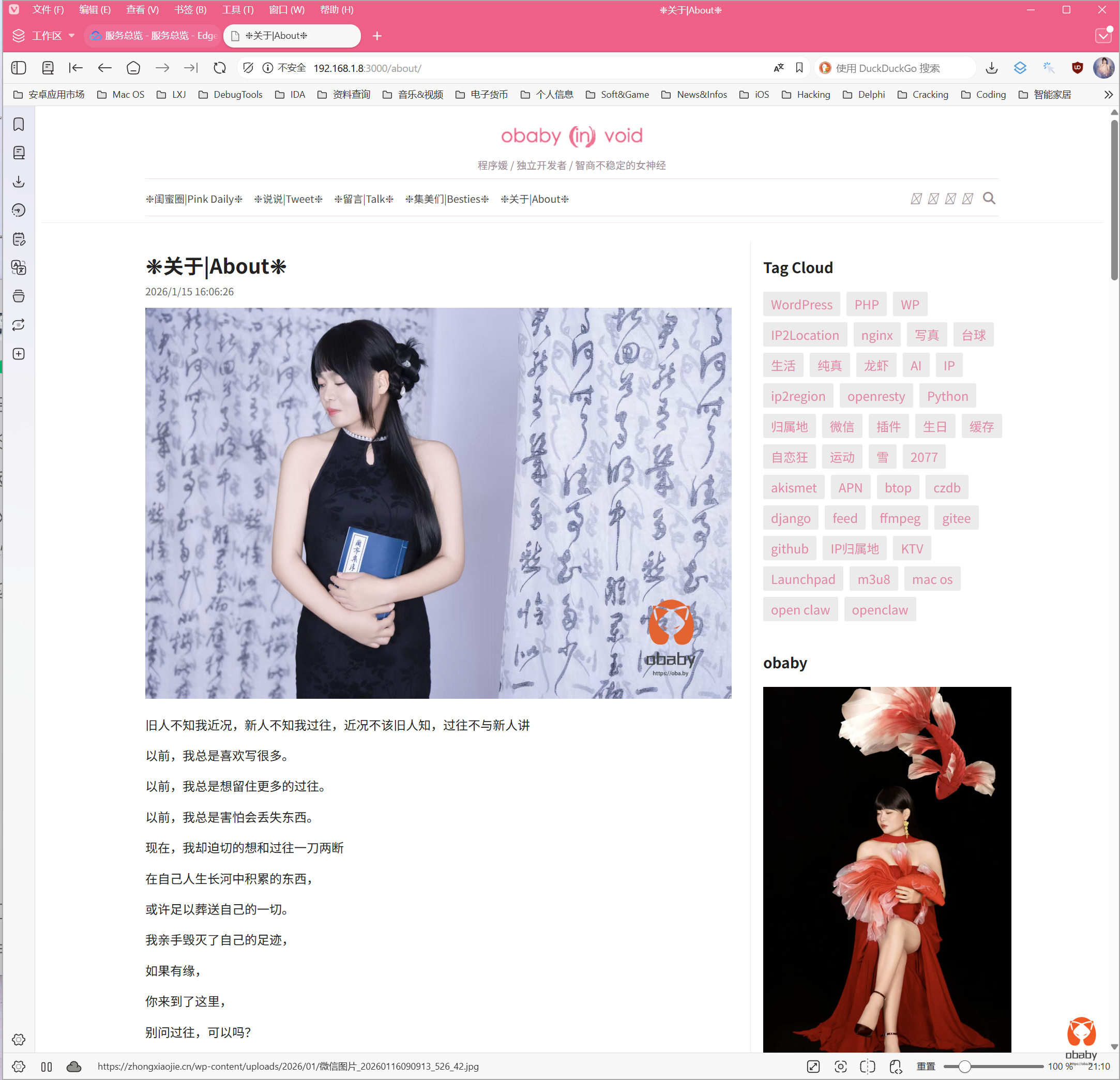
当然,这个实现方法的缺点就是得完全复刻frontend的相关路由和页面,优点就是不用关注原来的系统实现逻辑,哪怕爬虫seo系统出问题也不会影响现有的系统运行。