对象有一本做数独的书,里面满满的都是题目,然而,看到这前三关直接不淡定了,这尼玛是人能做出来的。
试了半天无过之后,果断还是决定上代码了。
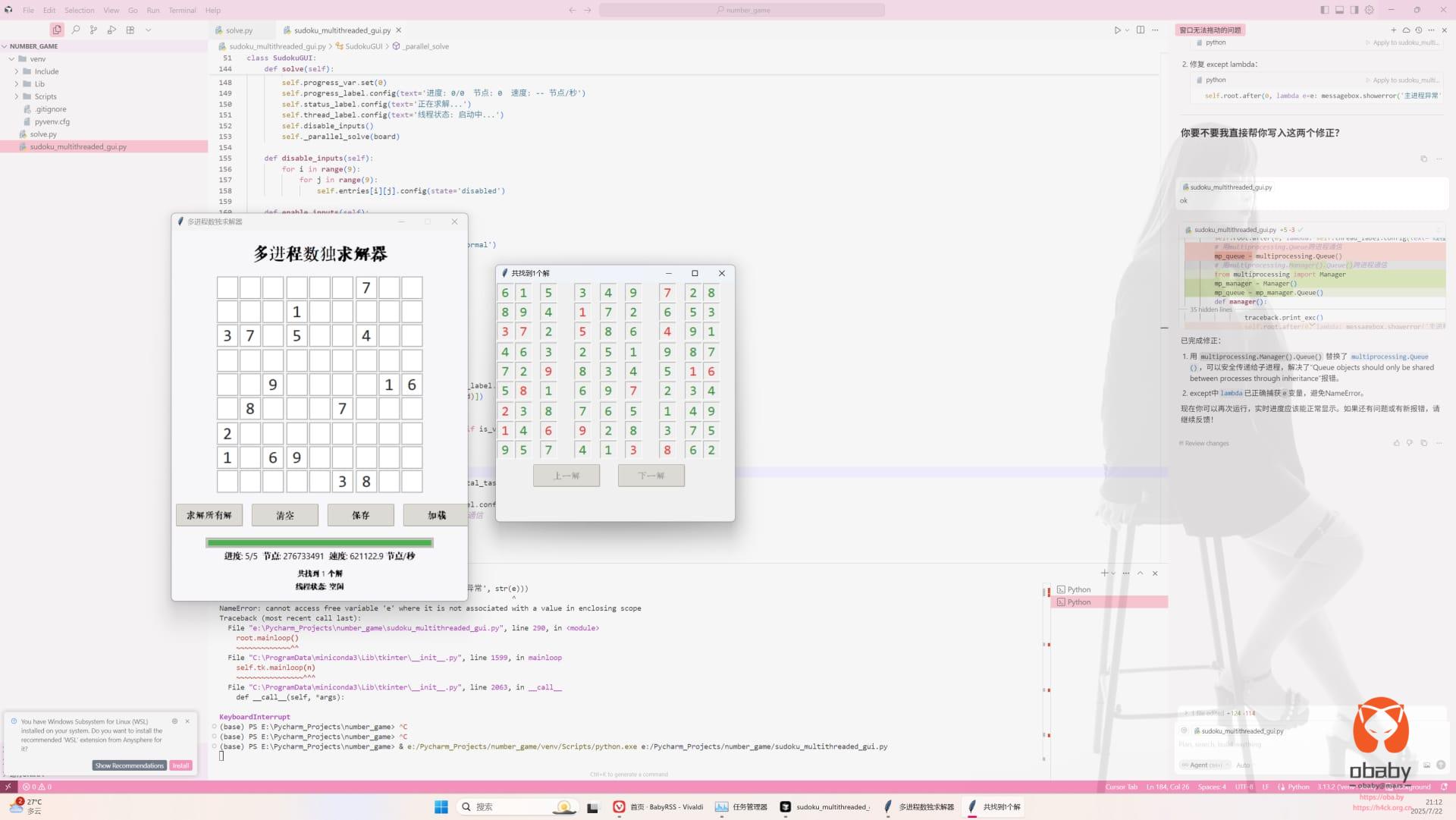
就这么个破玩意儿,愣是跑了十几分钟才出来。
import tkinter as tk
from tkinter import ttk, messagebox, filedialog
import threading
import queue
import time
import json
import copy
import concurrent.futures
import os
import multiprocessing
# --- 数独核心逻辑 ---
def is_valid(board, row, col, num):
for i in range(9):
if board[row][i] == num or board[i][col] == num:
return False
start_row, start_col = 3 * (row // 3), 3 * (col // 3)
for i in range(3):
for j in range(3):
if board[start_row + i][start_col + j] == num:
return False
return True
def solve_sudoku_all_with_progress(board, branch_id, progress_queue):
solutions = []
visited = [0]
def backtrack(bd, pos=0):
if pos == 81:
solutions.append(copy.deepcopy(bd))
return
row, col = divmod(pos, 9)
if bd[row][col] != 0:
backtrack(bd, pos + 1)
else:
for num in range(1, 10):
if is_valid(bd, row, col, num):
bd[row][col] = num
visited[0] += 1
if visited[0] % 1000 == 0:
progress_queue.put((branch_id, visited[0]))
backtrack(bd, pos + 1)
bd[row][col] = 0
backtrack(board)
# 结束时推送最终节点数
progress_queue.put((branch_id, visited[0]))
return solutions, visited[0]
def worker(new_board, branch_id, progress_queue):
return solve_sudoku_all_with_progress(new_board, branch_id, progress_queue)
class SudokuGUI:
def __init__(self, root):
self.root = root
self.root.title('多进程数独求解器')
self.root.geometry('520x650')
self.root.resizable(False, False)
self.entries = [[None for _ in range(9)] for _ in range(9)]
self._build_ui()
self.progress_queue = queue.Queue()
self._poll_progress()
def _build_ui(self):
self.root.configure(bg='#f7f7fa')
style = ttk.Style()
style.theme_use('clam')
style.configure('TButton', font=('Segoe UI', 12), padding=6)
style.configure('TLabel', font=('Segoe UI', 11), background='#f7f7fa')
style.configure('TProgressbar', thickness=18, troughcolor='#e0e0e0', background='#4caf50')
title = ttk.Label(self.root, text='多进程数独求解器', font=('Segoe UI', 22, 'bold'))
title.pack(pady=(18, 8))
frame = tk.Frame(self.root, bg='#f7f7fa')
frame.pack(pady=8)
for i in range(9):
for j in range(9):
e = tk.Entry(frame, width=2, font=('Consolas', 22), justify='center', bd=2, relief='ridge', bg='#fff', fg='#222')
e.grid(row=i, column=j, padx=(2 if j % 3 == 0 else 0, 2), pady=(2 if i % 3 == 0 else 0, 2))
self.entries[i][j] = e
btn_frame = tk.Frame(self.root, bg='#f7f7fa')
btn_frame.pack(pady=10)
ttk.Button(btn_frame, text='求解所有解', command=self.solve).grid(row=0, column=0, padx=8)
ttk.Button(btn_frame, text='清空', command=self.clear).grid(row=0, column=1, padx=8)
ttk.Button(btn_frame, text='保存', command=self.save).grid(row=0, column=2, padx=8)
ttk.Button(btn_frame, text='加载', command=self.load).grid(row=0, column=3, padx=8)
self.progress_var = tk.DoubleVar()
self.progress_bar = ttk.Progressbar(self.root, variable=self.progress_var, maximum=1, length=400)
self.progress_bar.pack(pady=(10, 2))
self.progress_label = ttk.Label(self.root, text='进度: 0/0 节点: 0 速度: -- 节点/秒')
self.progress_label.pack()
self.status_label = ttk.Label(self.root, text='', font=('Segoe UI', 10))
self.status_label.pack(pady=(8, 0))
self.thread_label = ttk.Label(self.root, text='线程状态: 空闲', font=('Segoe UI', 10))
self.thread_label.pack(pady=(2, 0))
def get_board(self):
board = []
for i in range(9):
row = []
for j in range(9):
val = self.entries[i][j].get()
if val == '':
row.append(0)
else:
try:
num = int(val)
if 1 <= num <= 9:
row.append(num)
else:
raise ValueError
except ValueError:
messagebox.showerror('输入错误', f'第{i+1}行第{j+1}列输入无效')
return None
board.append(row)
return board
def clear(self):
for i in range(9):
for j in range(9):
self.entries[i][j].delete(0, tk.END)
self.progress_var.set(0)
self.progress_label.config(text='进度: 0/0 节点: 0 速度: -- 节点/秒')
self.status_label.config(text='')
self.thread_label.config(text='线程状态: 空闲')
def save(self):
data = [[self.entries[i][j].get() for j in range(9)] for i in range(9)]
file_path = filedialog.asksaveasfilename(defaultextension='.json', filetypes=[('JSON文件', '*.json')])
if file_path:
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False)
self.status_label.config(text='已保存')
def load(self):
file_path = filedialog.askopenfilename(defaultextension='.json', filetypes=[('JSON文件', '*.json')])
if file_path:
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for i in range(9):
for j in range(9):
self.entries[i][j].delete(0, tk.END)
if data[i][j]:
self.entries[i][j].insert(0, data[i][j])
self.status_label.config(text='已加载')
def solve(self):
board = self.get_board()
if board is None:
return
self.progress_var.set(0)
self.progress_label.config(text='进度: 0/0 节点: 0 速度: -- 节点/秒')
self.status_label.config(text='正在求解...')
self.thread_label.config(text='线程状态: 启动中...')
self.disable_inputs()
self._parallel_solve(board)
def disable_inputs(self):
for i in range(9):
for j in range(9):
self.entries[i][j].config(state='disabled')
def enable_inputs(self):
for i in range(9):
for j in range(9):
self.entries[i][j].config(state='normal')
def _parallel_solve(self, board):
# 找到第一个空格
first_empty = None
for i in range(9):
for j in range(9):
if board[i][j] == 0:
first_empty = (i, j)
break
if first_empty:
break
if not first_empty:
self.root.after(0, lambda: self.thread_label.config(text='线程状态: 空闲'))
self.on_solve_done([copy.deepcopy(board)])
return
i, j = first_empty
candidates = [num for num in range(1, 10) if is_valid(board, i, j, num)]
total_tasks = len(candidates)
finished = [0]
all_solutions = []
all_visited = [0]
branch_nodes = {idx: 0 for idx in range(total_tasks)}
start_time = time.time()
self.root.after(0, lambda: self.thread_label.config(text='线程状态: 运行中 (多进程)'))
# 用multiprocessing.Manager().Queue()跨进程通信
from multiprocessing import Manager
mp_manager = Manager()
mp_queue = mp_manager.Queue()
def manager():
try:
with concurrent.futures.ProcessPoolExecutor(max_workers=os.cpu_count()) as executor:
futures = []
for idx, num in enumerate(candidates):
new_board = copy.deepcopy(board)
new_board[i][j] = num
futures.append(executor.submit(worker, new_board, idx, mp_queue))
# 进度监听线程
def progress_listener():
while finished[0] < total_tasks:
try:
branch_id, nodes = mp_queue.get(timeout=0.1)
branch_nodes[branch_id] = nodes
all_visited[0] = sum(branch_nodes.values())
elapsed = time.time() - start_time
speed = all_visited[0] / elapsed if elapsed > 0 else 0
self.progress_queue.put((finished[0], total_tasks, speed, all_visited[0]))
except Exception:
pass
listener_thread = threading.Thread(target=progress_listener, daemon=True)
listener_thread.start()
for idx, fut in enumerate(futures):
result, visited = fut.result()
all_solutions.extend(result)
finished[0] += 1
branch_nodes[idx] = visited
all_visited[0] = sum(branch_nodes.values())
elapsed = time.time() - start_time
speed = all_visited[0] / elapsed if elapsed > 0 else 0
self.progress_queue.put((finished[0], total_tasks, speed, all_visited[0]))
listener_thread.join(timeout=0.1)
self.root.after(0, lambda: self.thread_label.config(text='线程状态: 已完成 (多进程)'))
self.root.after(0, lambda: self.on_solve_done(all_solutions))
except Exception as e:
import traceback
traceback.print_exc()
self.root.after(0, lambda e=e: messagebox.showerror('主进程异常', str(e)))
threading.Thread(target=manager, daemon=True).start()
def _poll_progress(self):
try:
while True:
v, t, s, nodes = self.progress_queue.get_nowait()
self._update_progress(v, t, s, nodes)
except queue.Empty:
pass
self.root.after(50, self._poll_progress)
def _update_progress(self, finished, total, speed, nodes):
progress = finished / total if total > 0 else 0
speed_str = f"{speed:.1f}" if speed > 0 else "--"
self.progress_var.set(progress)
self.progress_label.config(text=f'进度: {finished}/{total} 节点: {nodes} 速度: {speed_str} 节点/秒')
def on_solve_done(self, solutions):
self.enable_inputs()
if not solutions:
self.status_label.config(text='无解')
self.thread_label.config(text='线程状态: 空闲')
messagebox.showinfo('结果', '无解')
else:
self.status_label.config(text=f'共找到 {len(solutions)} 个解')
self.thread_label.config(text='线程状态: 空闲')
self.show_solution_window(solutions)
def show_solution_window(self, solutions):
win = tk.Toplevel(self.root)
win.title(f'共找到{len(solutions)}个解')
win.geometry('420x420')
idx = tk.IntVar(value=0)
original = [[self.entries[i][j].get() != '' for j in range(9)] for i in range(9)]
sol_entries = [[tk.Entry(win, width=2, font=('Consolas', 18), justify='center', state='readonly') for _ in range(9)] for _ in range(9)]
for i in range(9):
for j in range(9):
sol_entries[i][j].grid(row=i, column=j, padx=(2 if j % 3 == 0 else 0, 2), pady=(2 if i % 3 == 0 else 0, 2))
def show(idx_val):
for i in range(9):
for j in range(9):
sol_entries[i][j].config(state='normal')
sol_entries[i][j].delete(0, tk.END)
sol_entries[i][j].insert(0, str(solutions[idx_val][i][j]))
if original[i][j]:
sol_entries[i][j].config(fg='#e53935')
else:
sol_entries[i][j].config(fg='#388e3c')
sol_entries[i][j].config(state='readonly')
btn_prev = ttk.Button(win, text='上一解', command=lambda: (idx.set((idx.get()-1)%len(solutions)), show(idx.get())))
btn_next = ttk.Button(win, text='下一解', command=lambda: (idx.set((idx.get()+1)%len(solutions)), show(idx.get())))
btn_prev.grid(row=9, column=2, columnspan=2, pady=8)
btn_next.grid(row=9, column=5, columnspan=2, pady=8)
if len(solutions) == 1:
btn_prev.config(state='disabled')
btn_next.config(state='disabled')
show(0)
if __name__ == "__main__":
multiprocessing.freeze_support() # for Windows compatibility
root = tk.Tk()
app = SudokuGUI(root)
root.mainloop()
The post 数独求解工具 appeared first on obaby@mars.