你来啦! — 半正式上线
2026年6月4日 15:06

前段时间提到的那个心血来潮的项目,经过这几天的反复折腾。现在算是有些眉目了,虽然离一个正式的产品依然差很多。
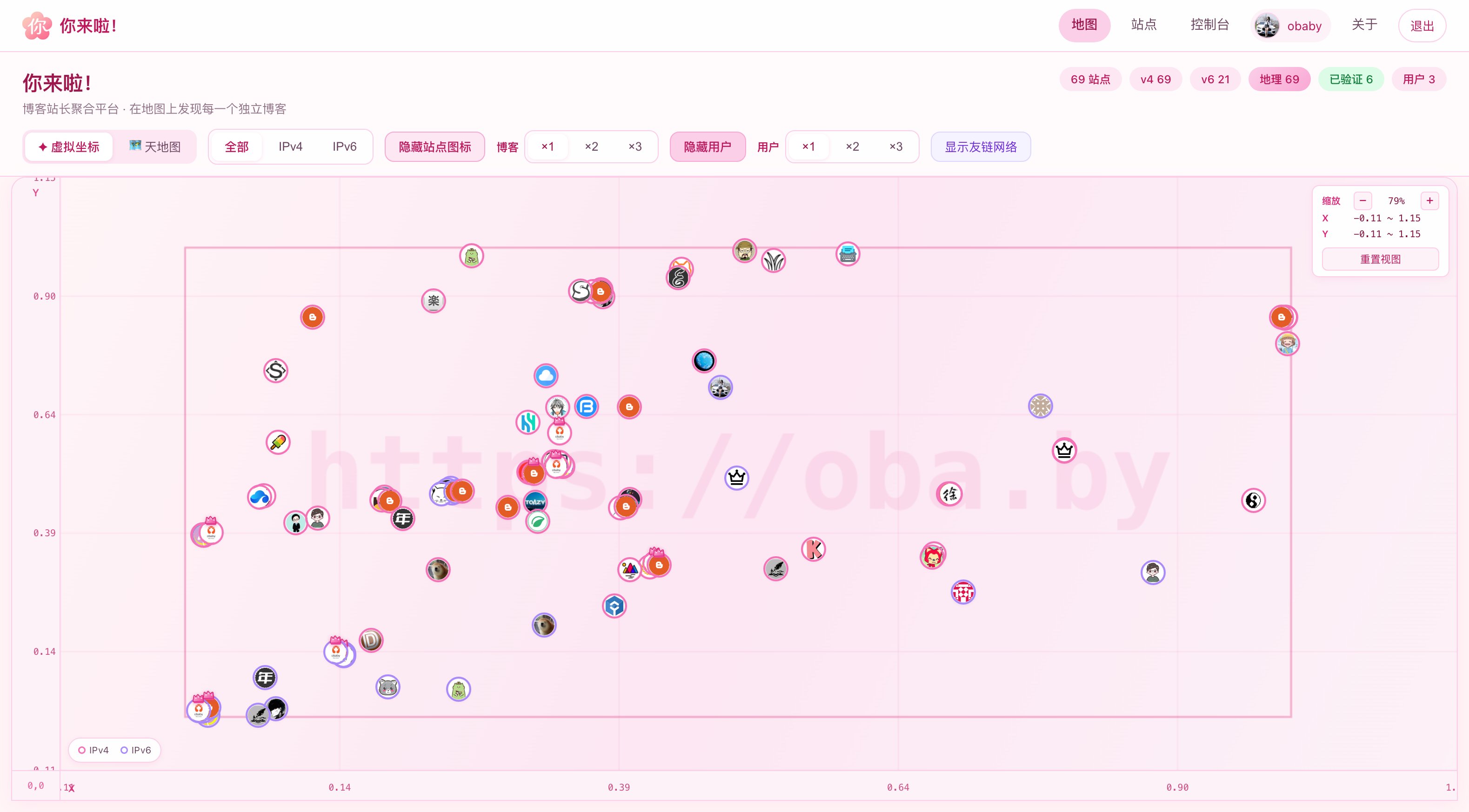
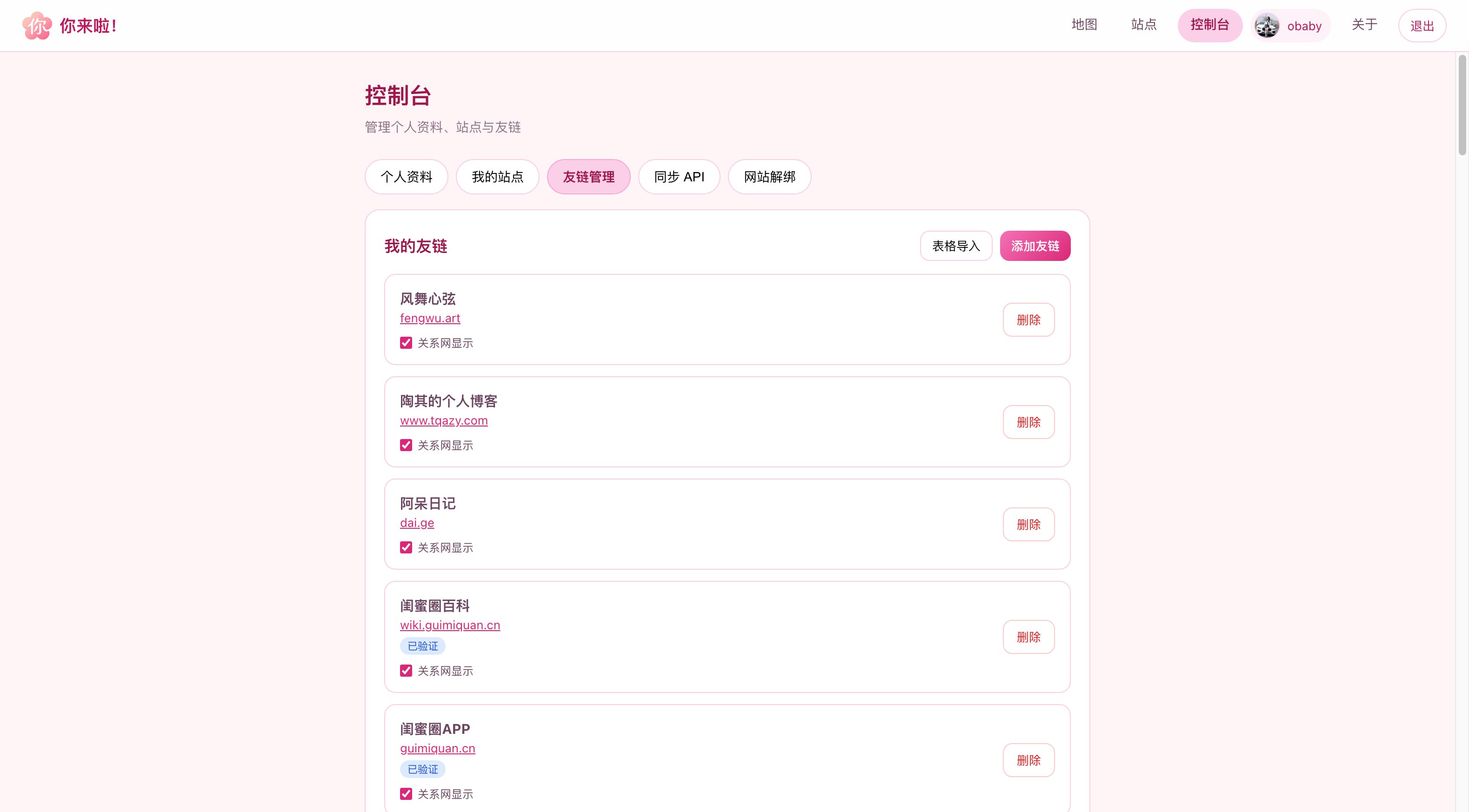
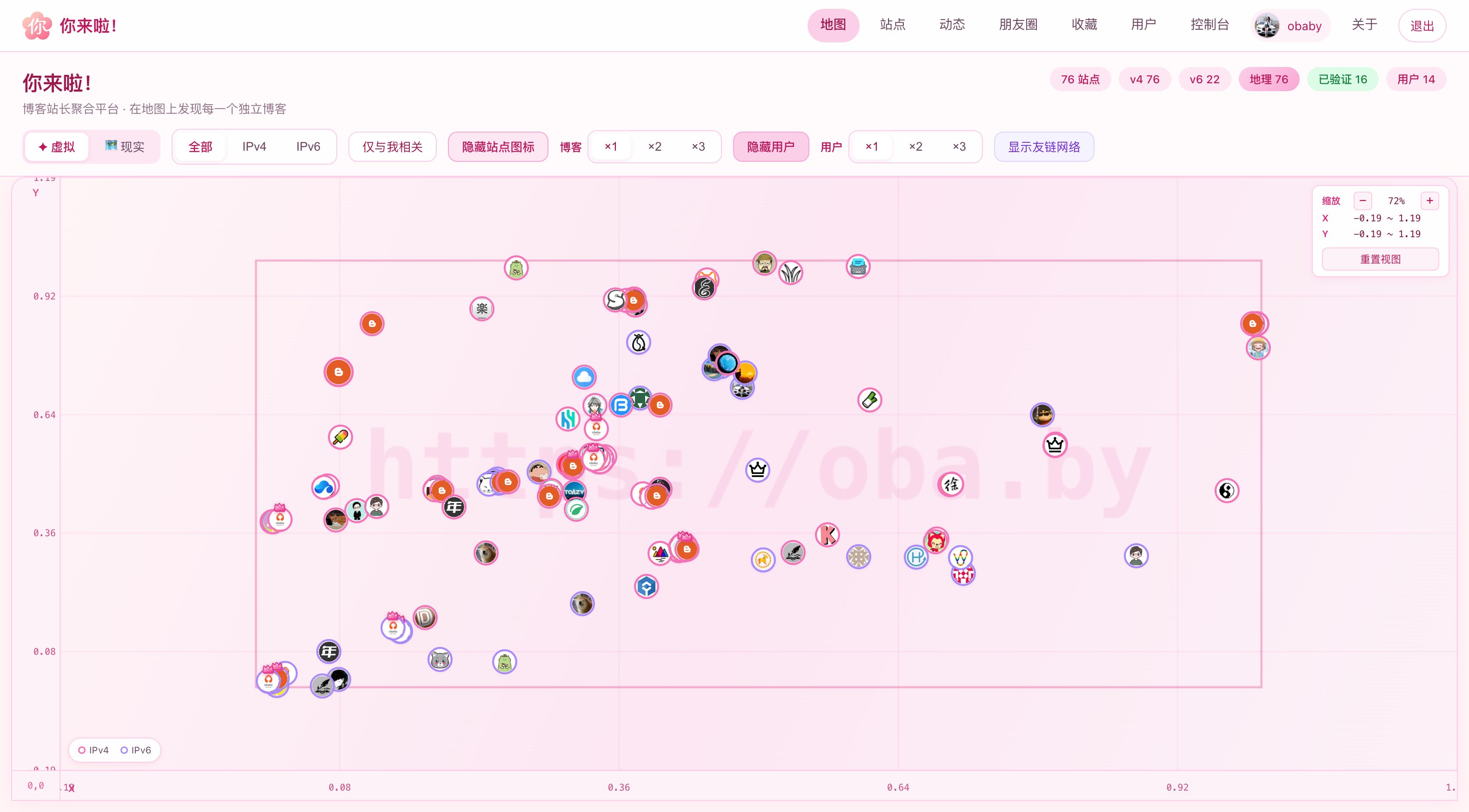
从来没什么完美的产品,也从来不会有完美。虽然嘴上说闺蜜圈最近又停滞了很久,但是陆陆续续还是修复了一些服务端的推送问题。如果说产品,那么 你来啦! 可以算是一个不务正业的产品,从来没想到自己会做一款博客聚合类的产品。
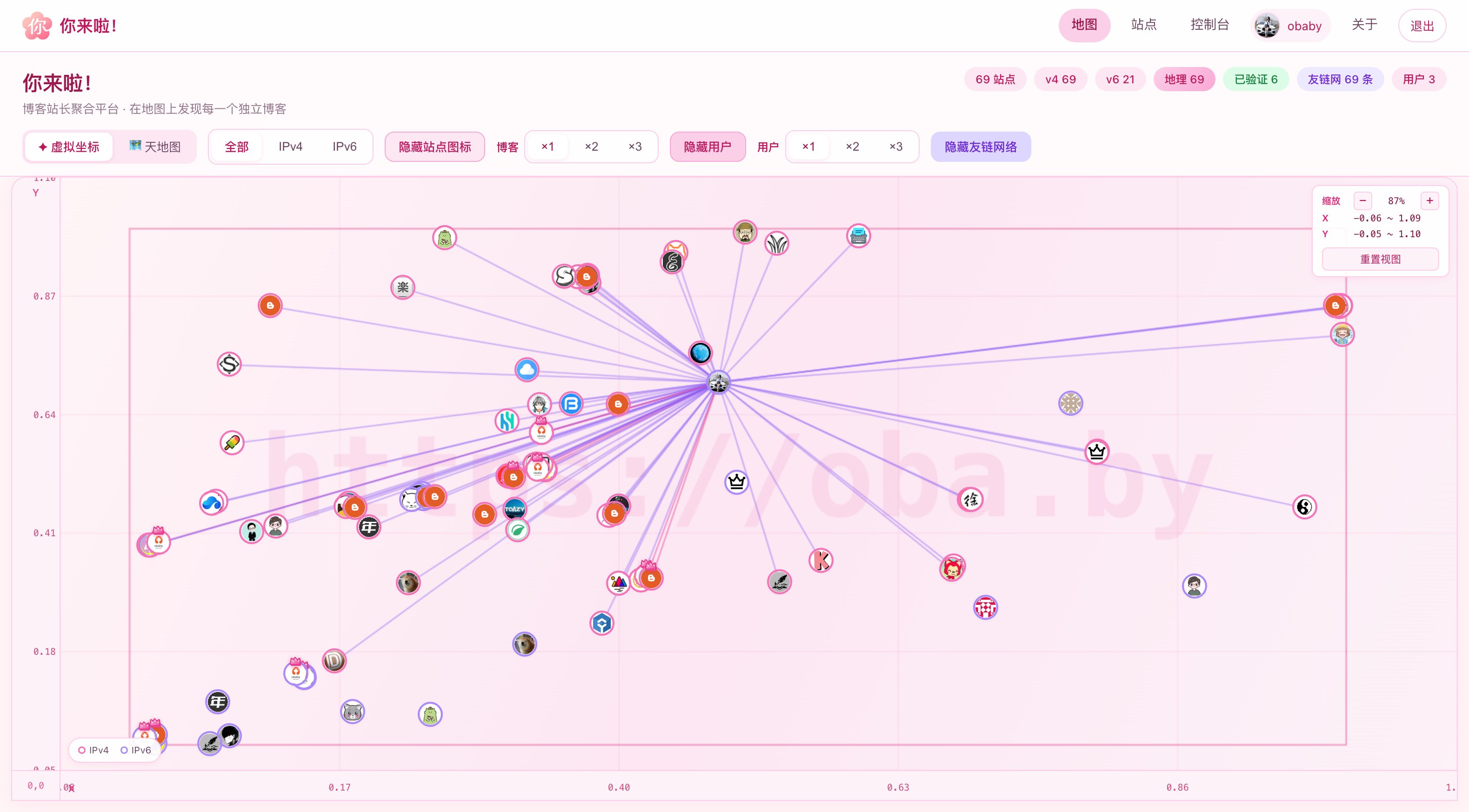
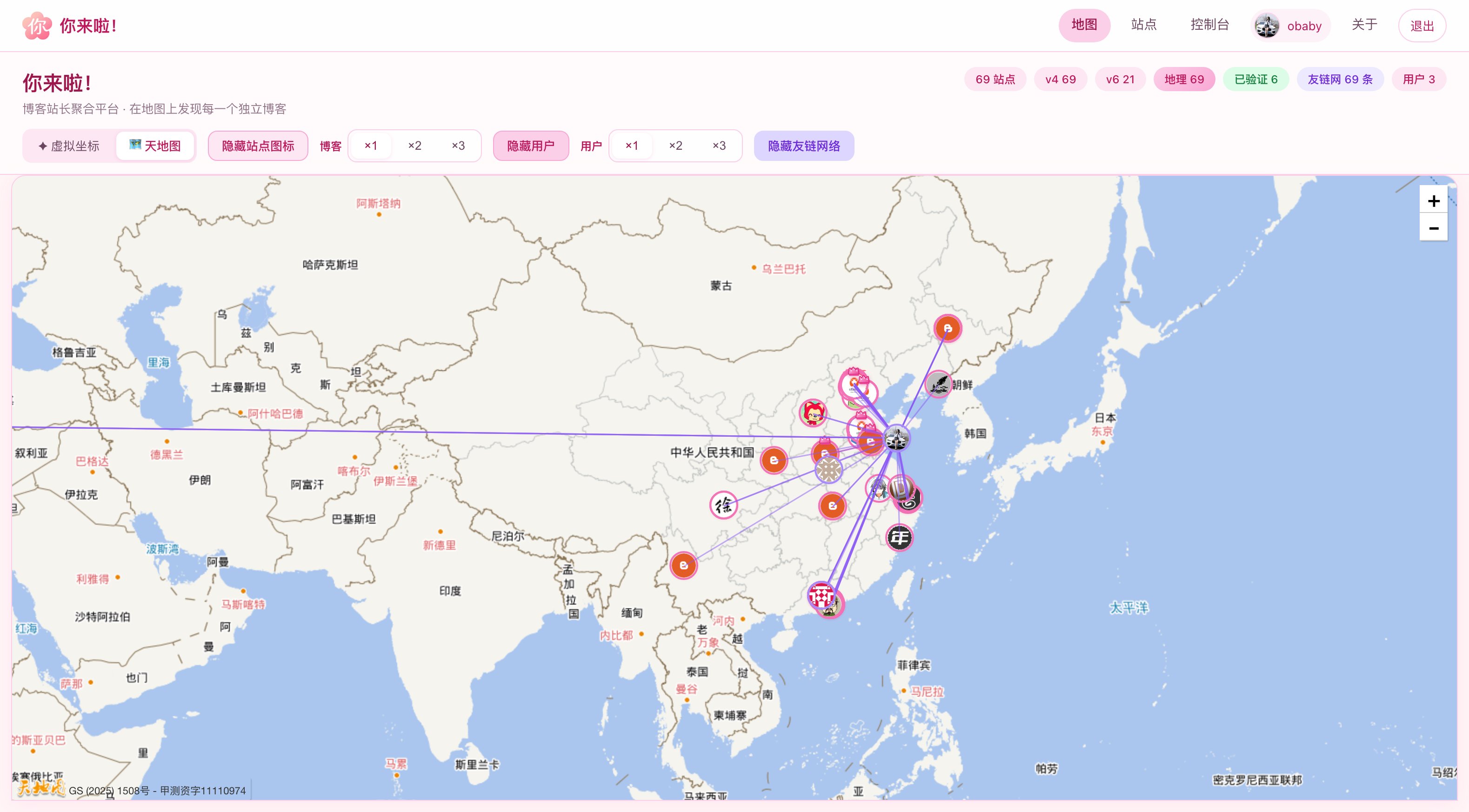
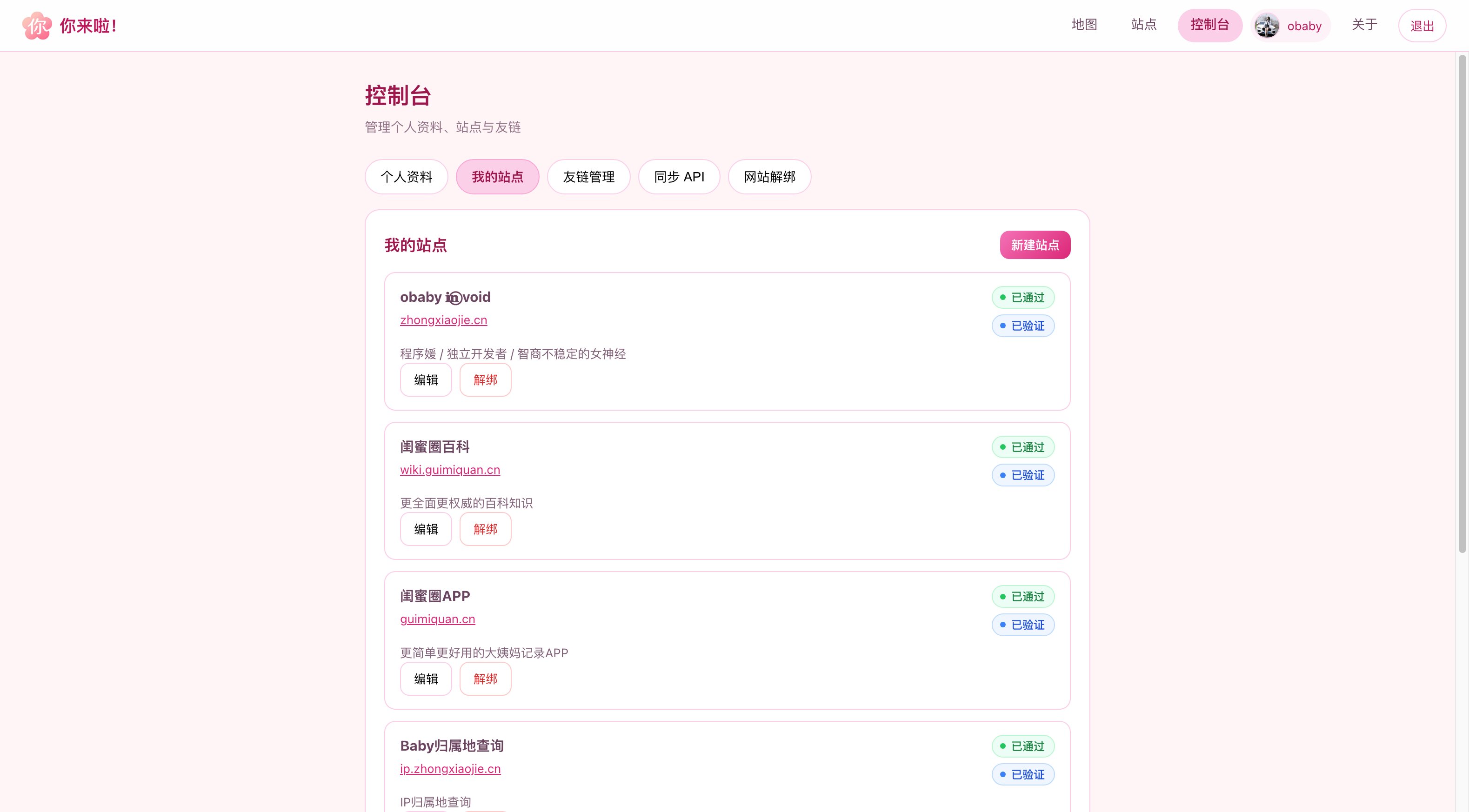
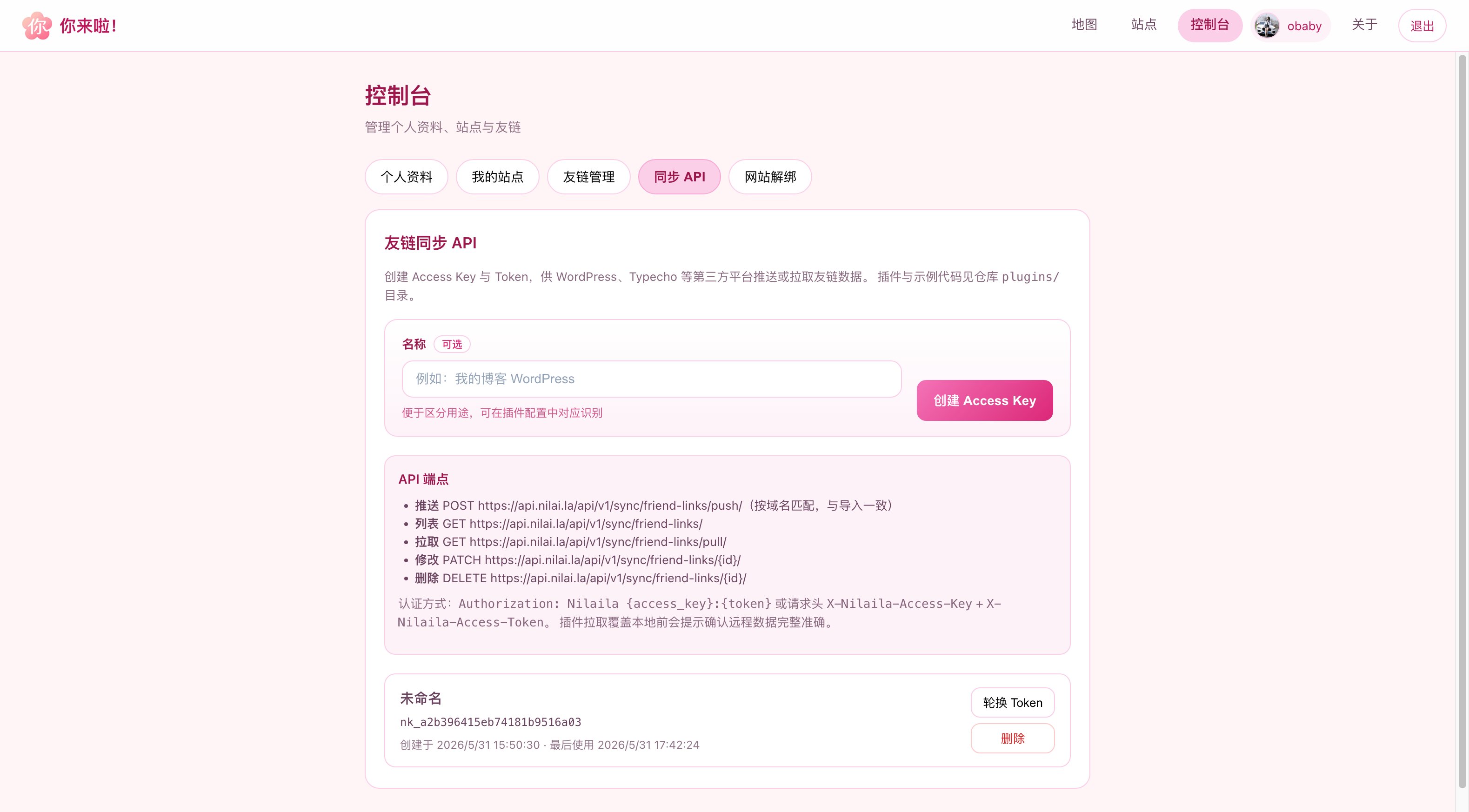
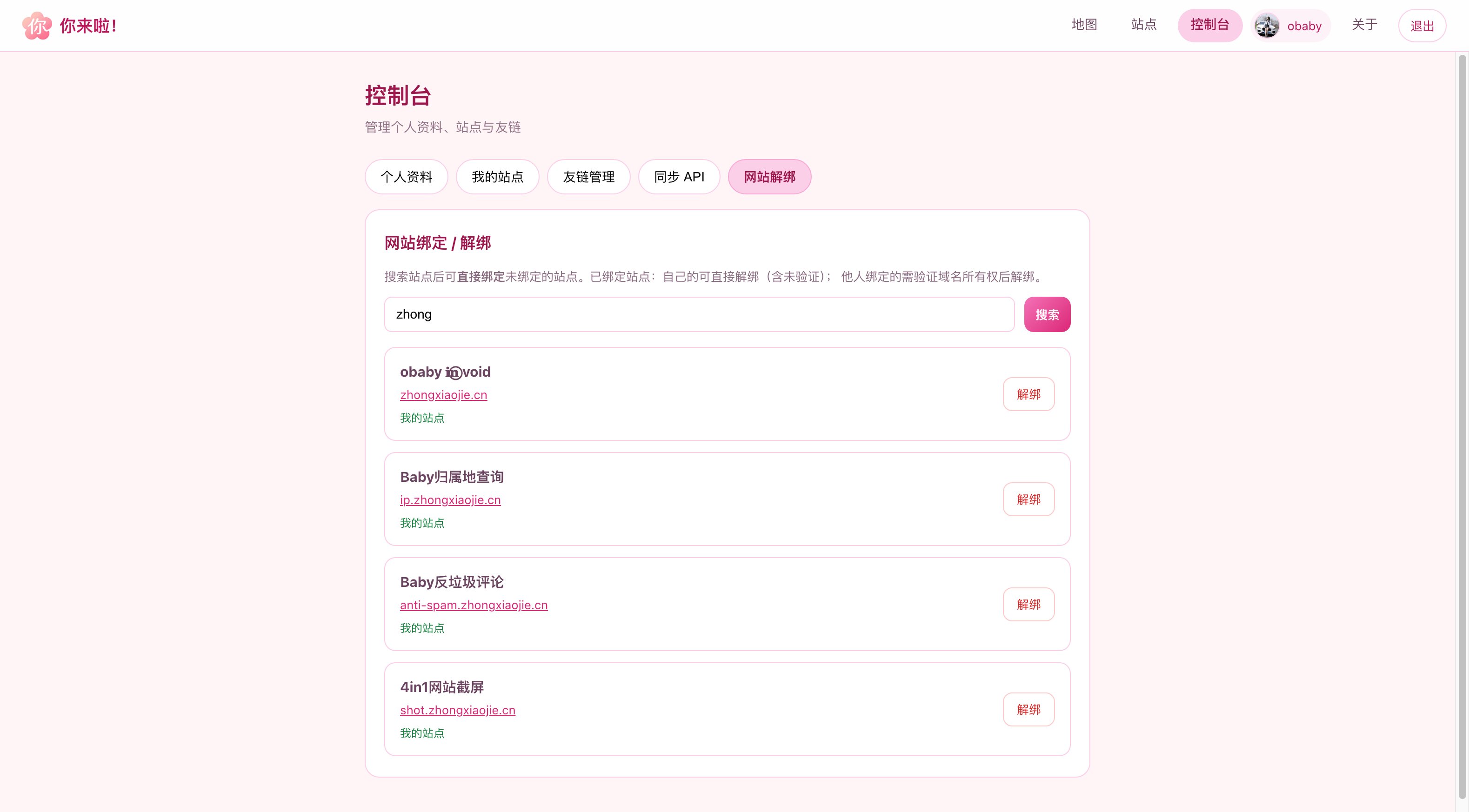
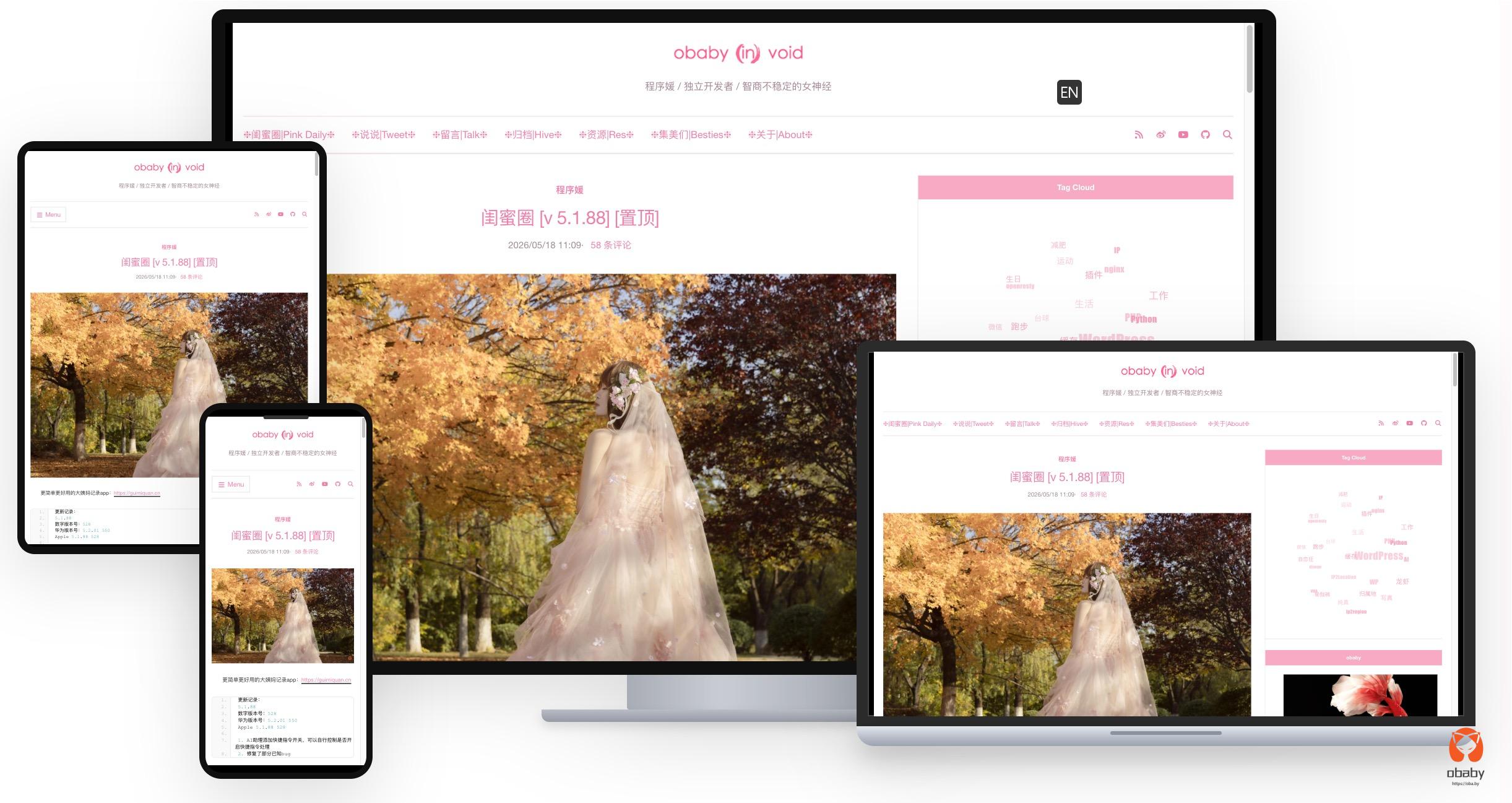
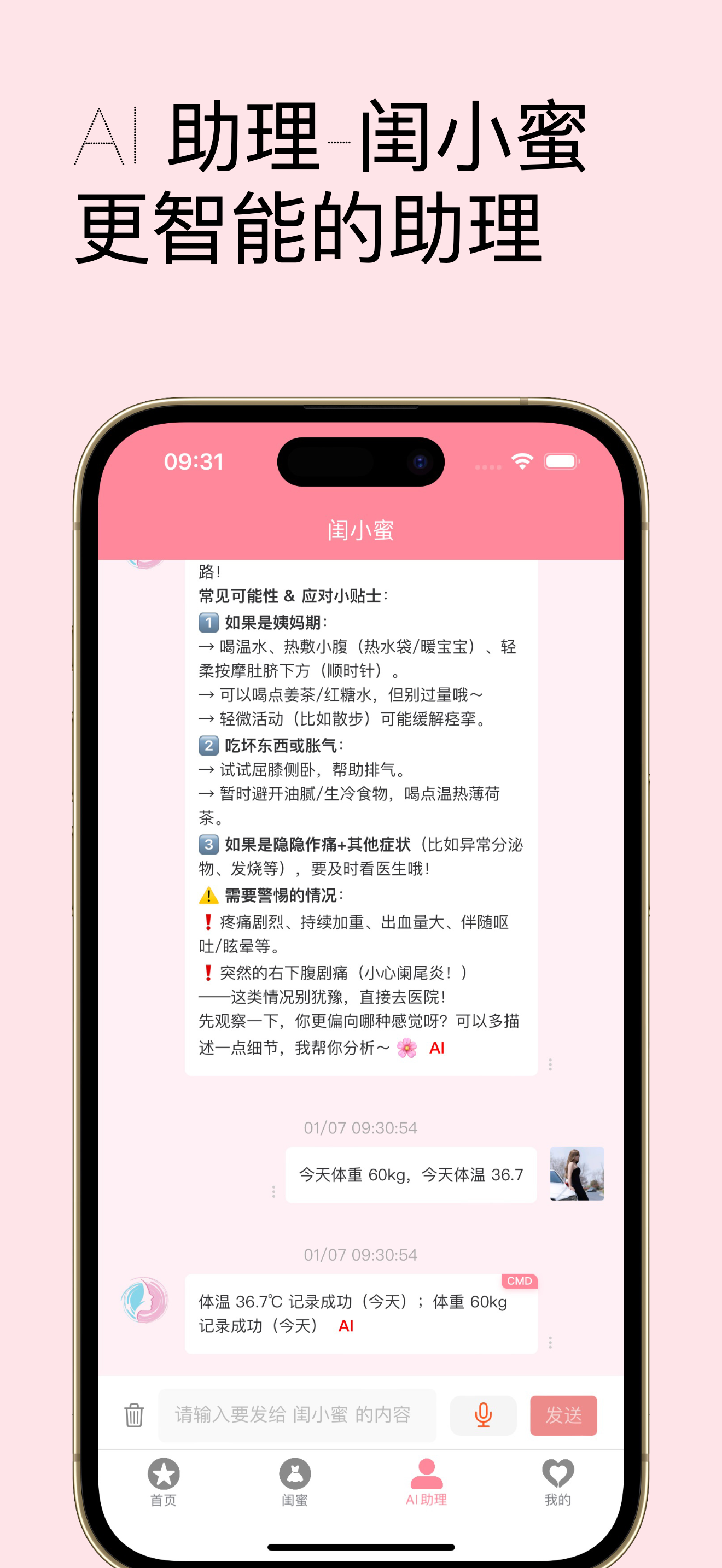
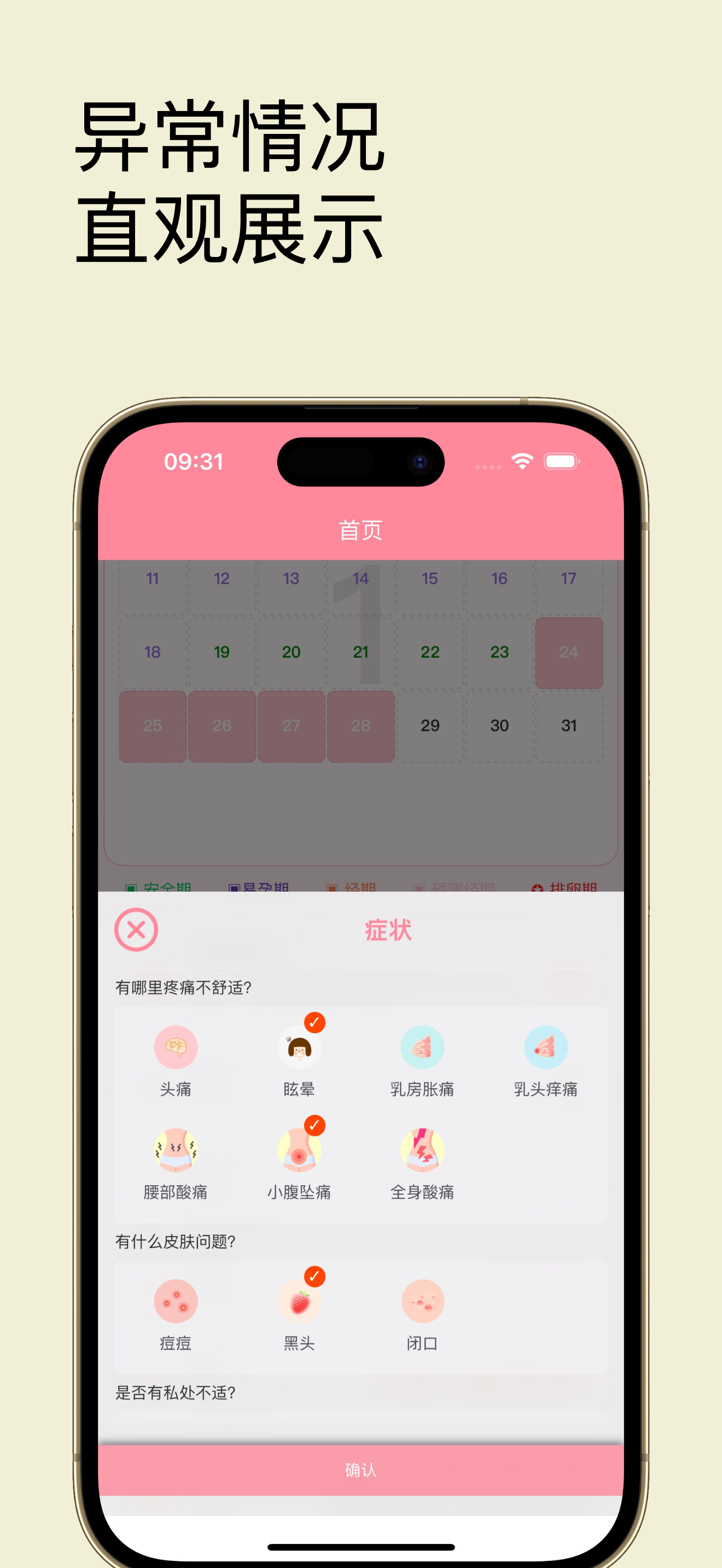
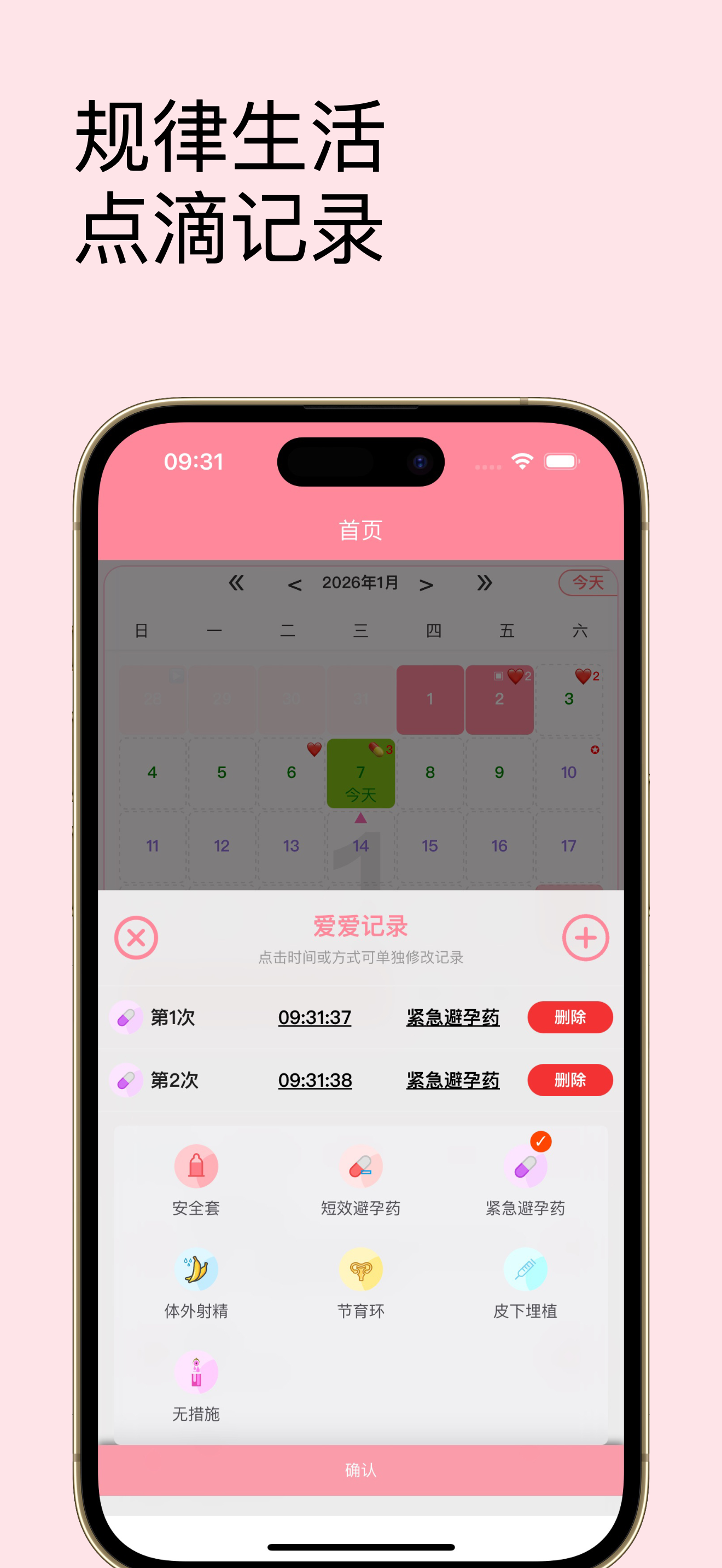
数次迭代之后,现在看到的就是下面的样子了(部分界面截图):
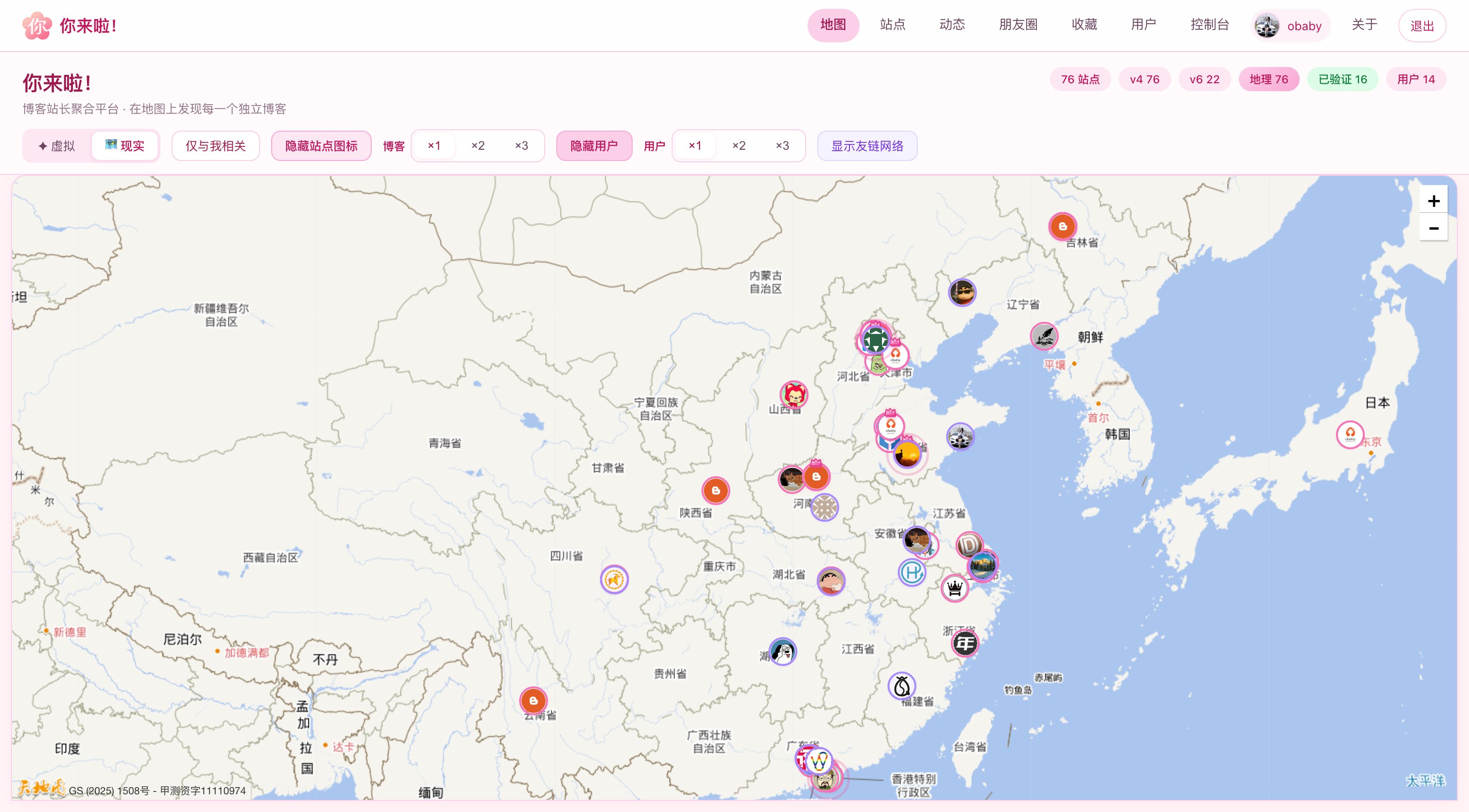
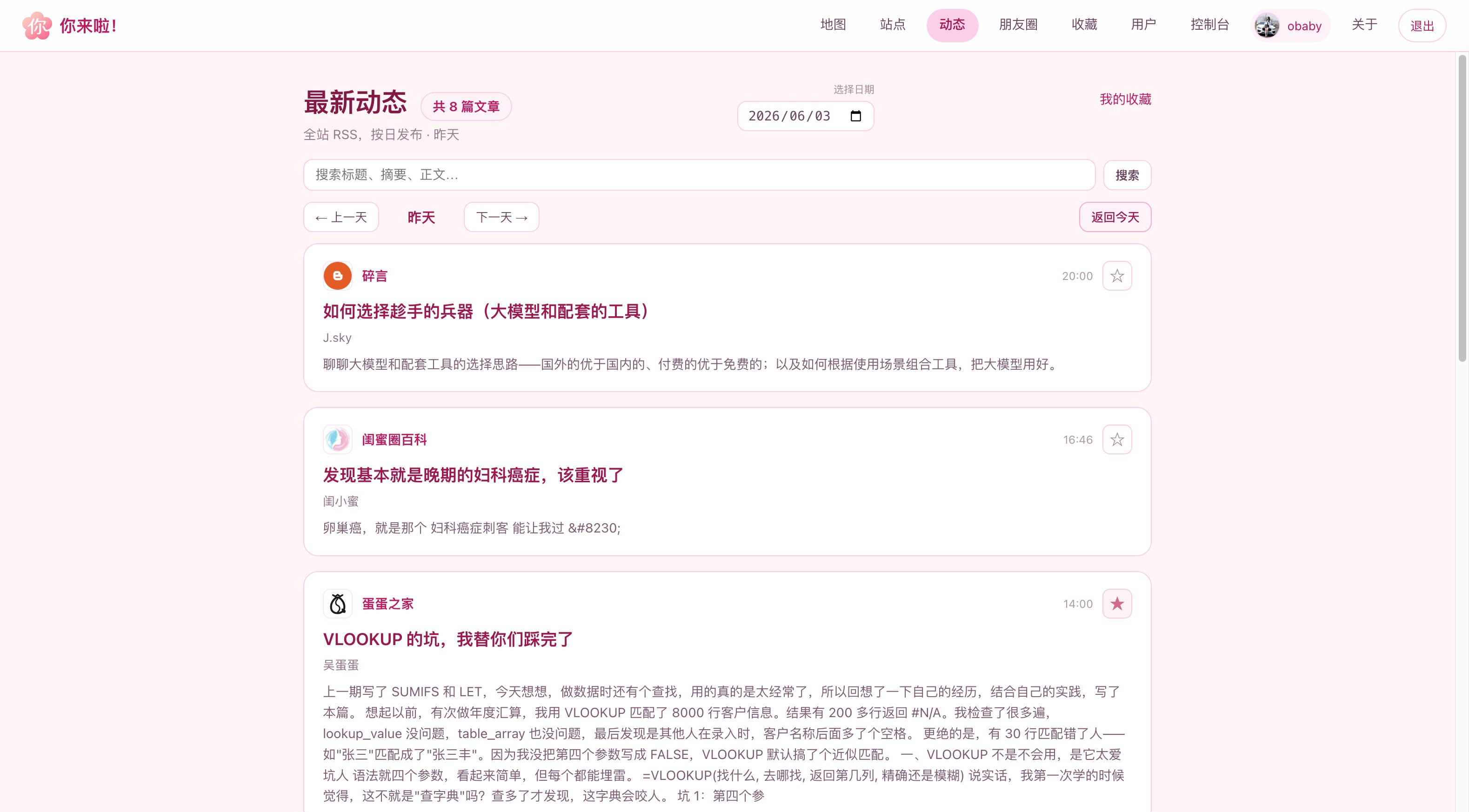
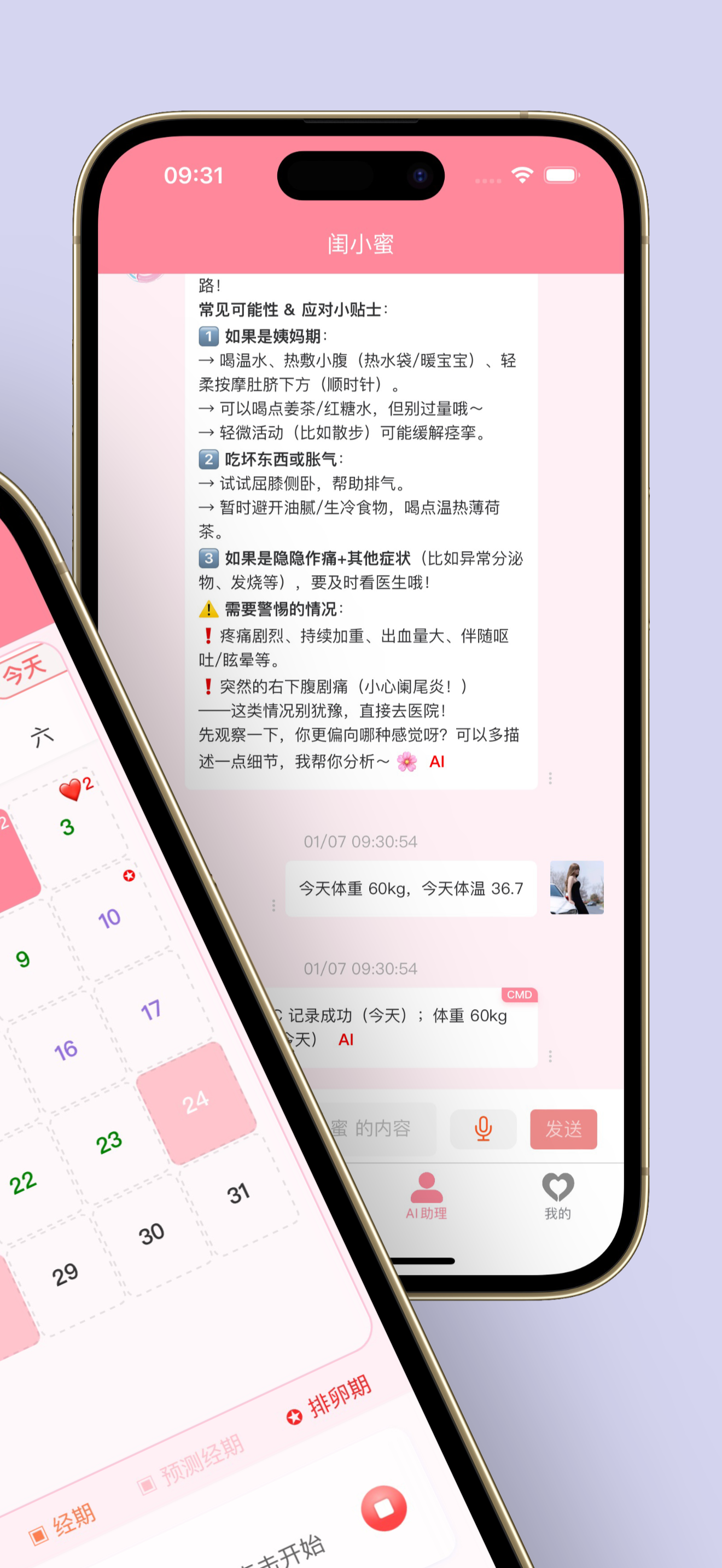
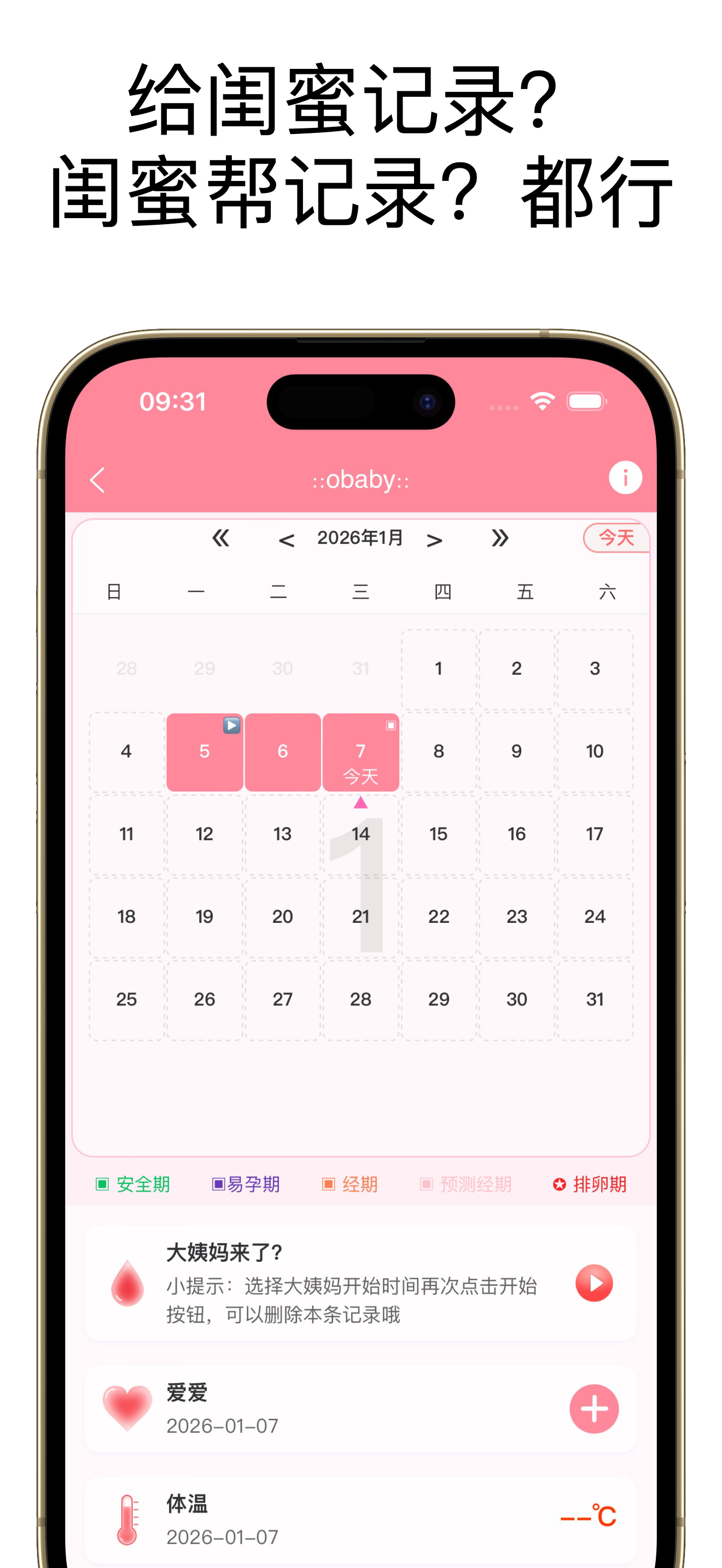
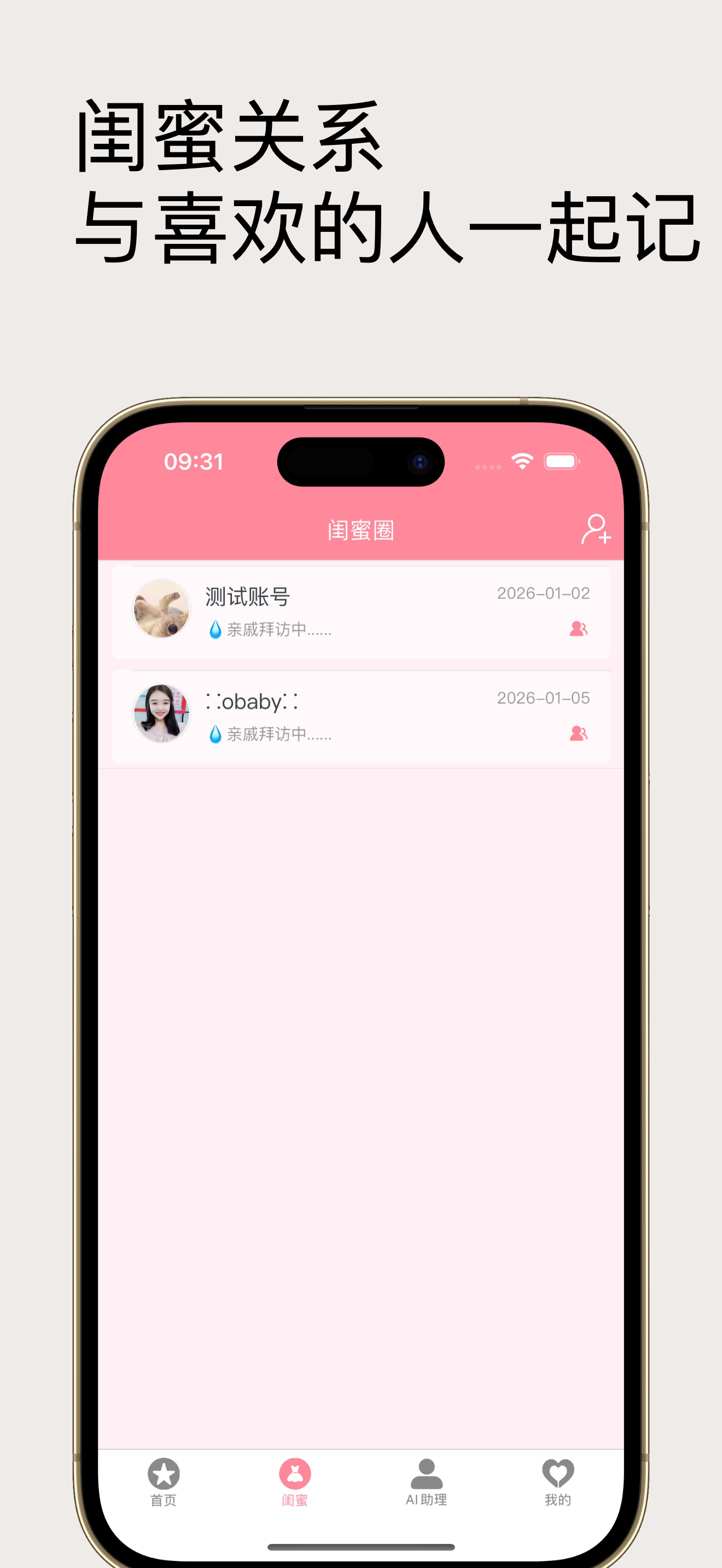
当然除此之外我还开发了app,部分截图:
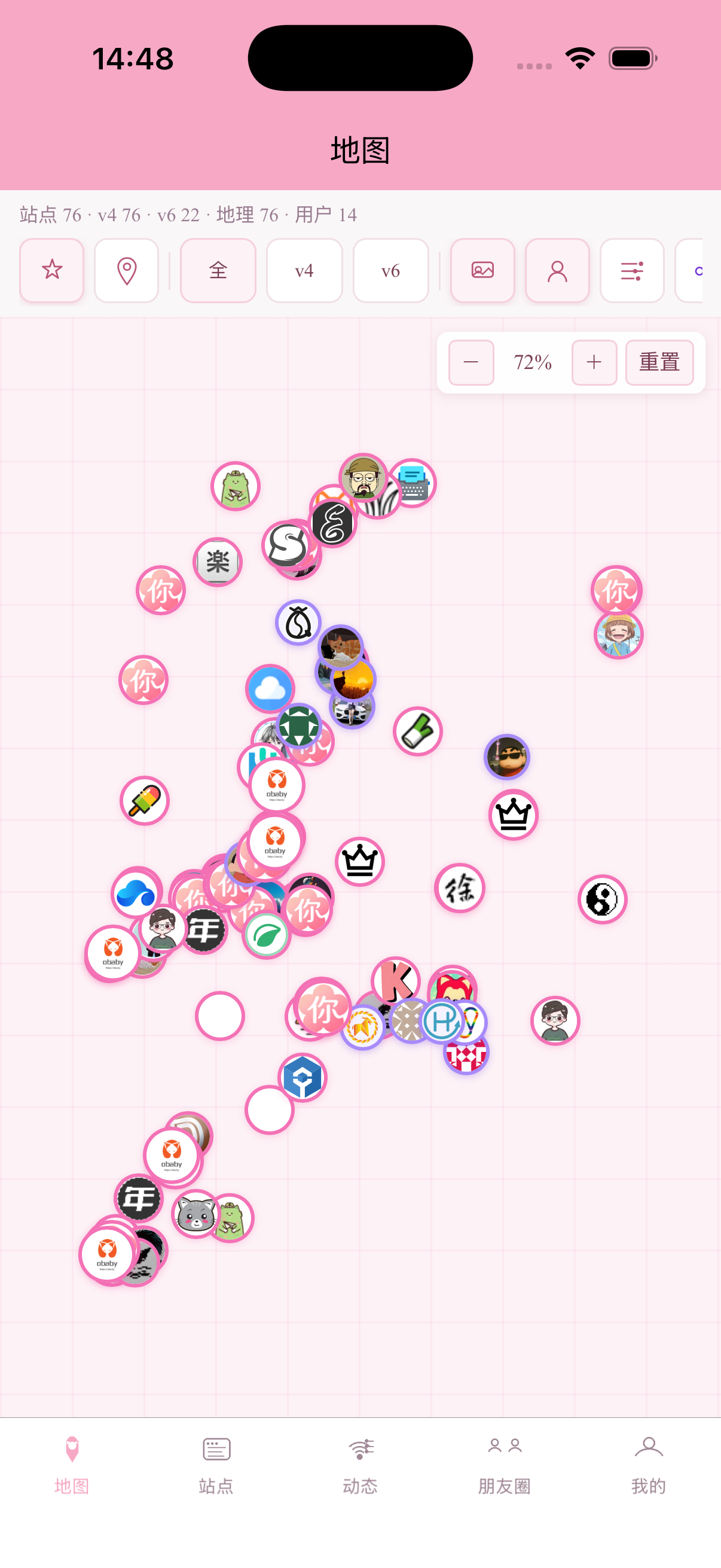
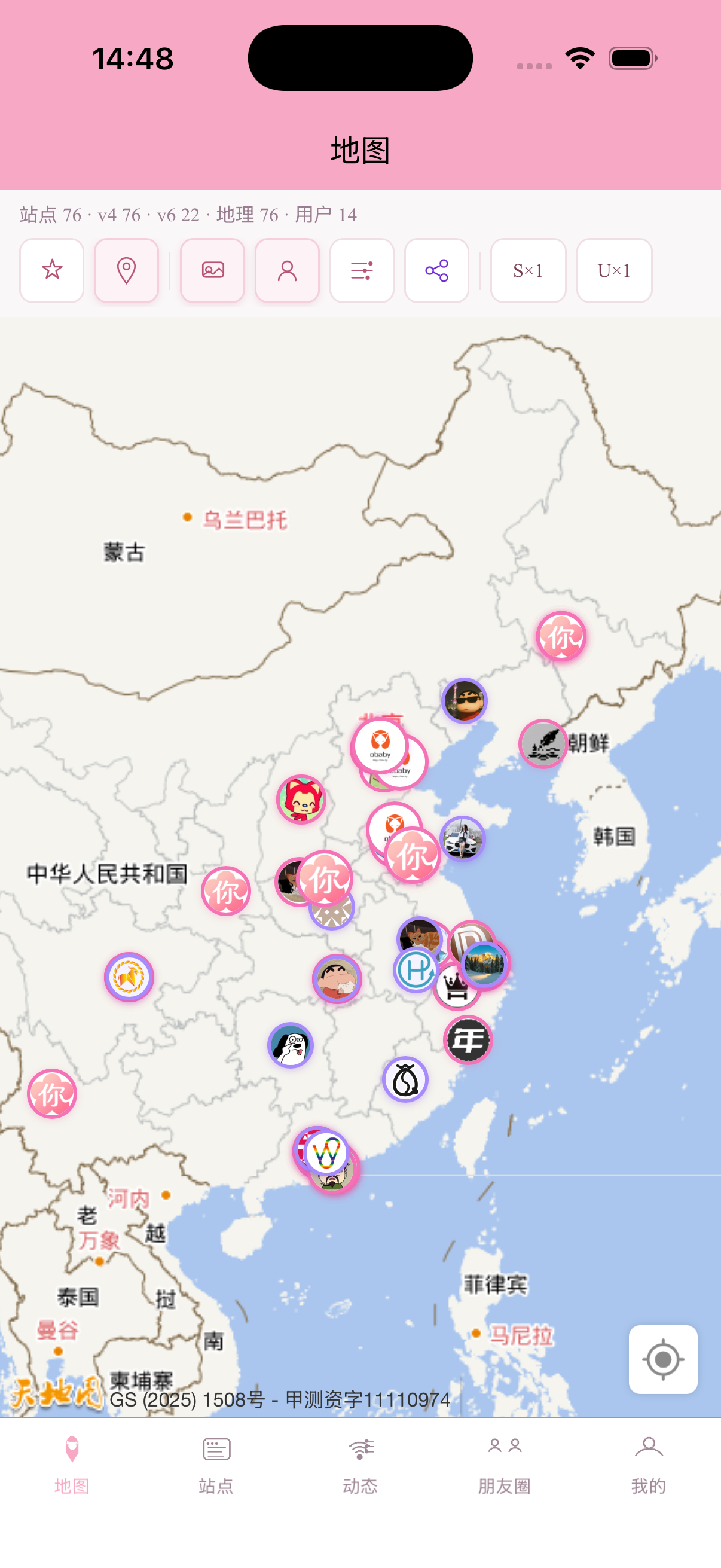

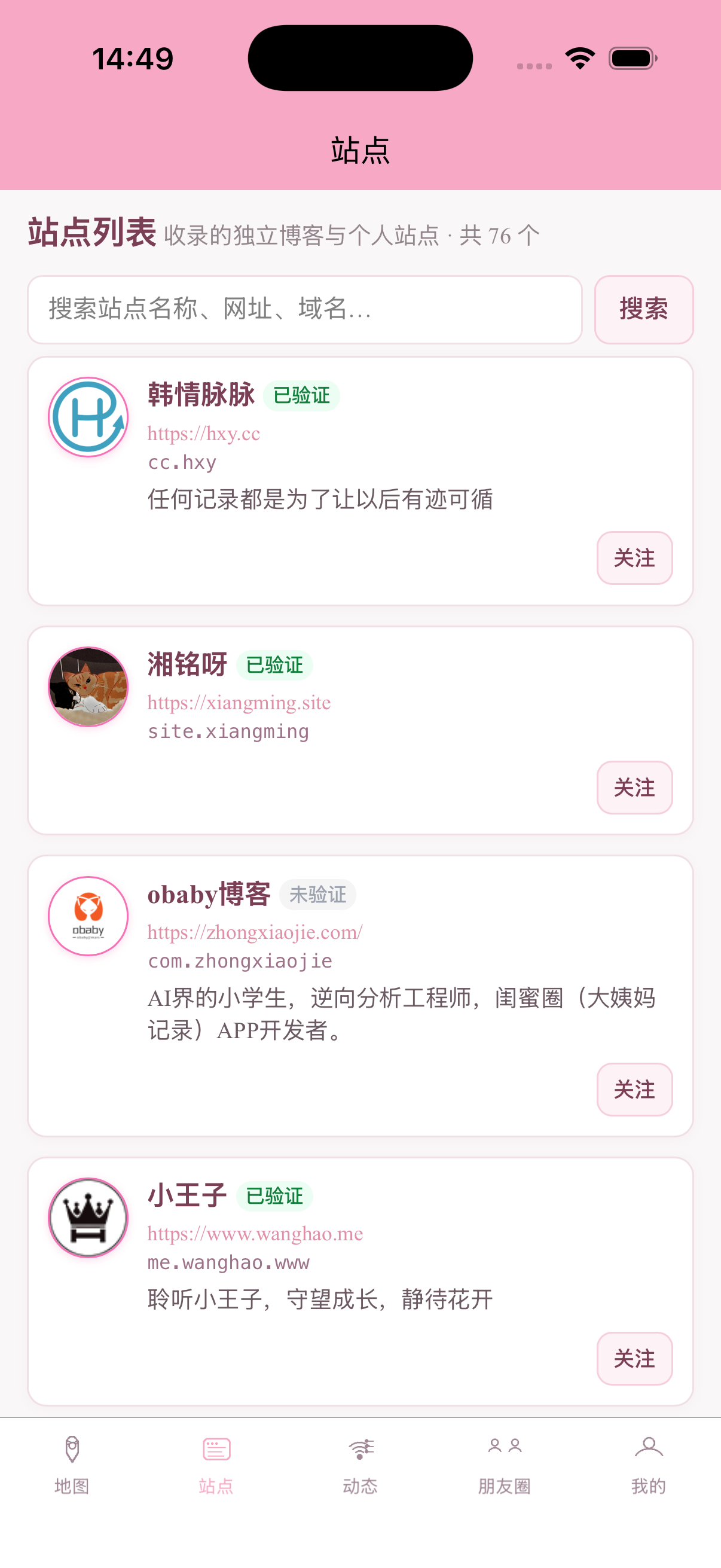
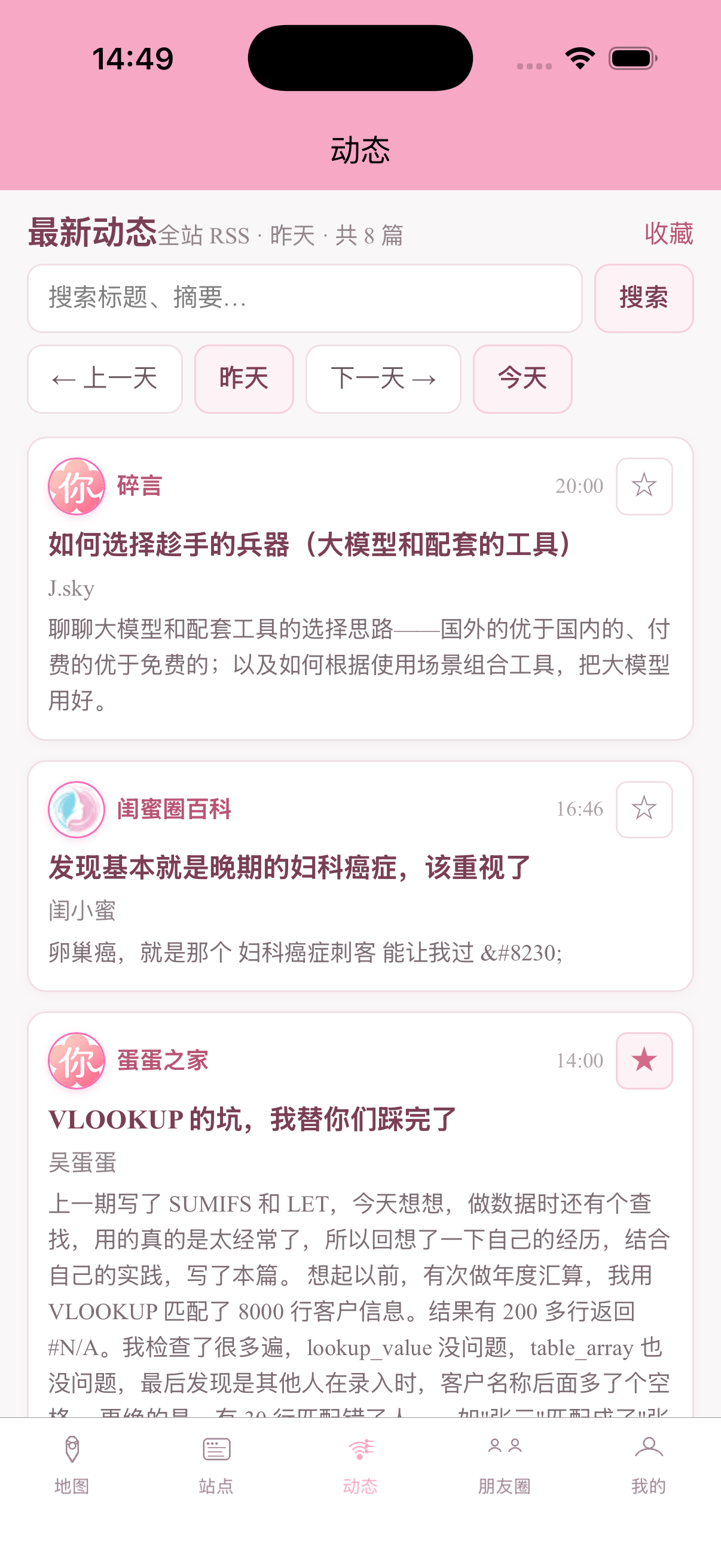
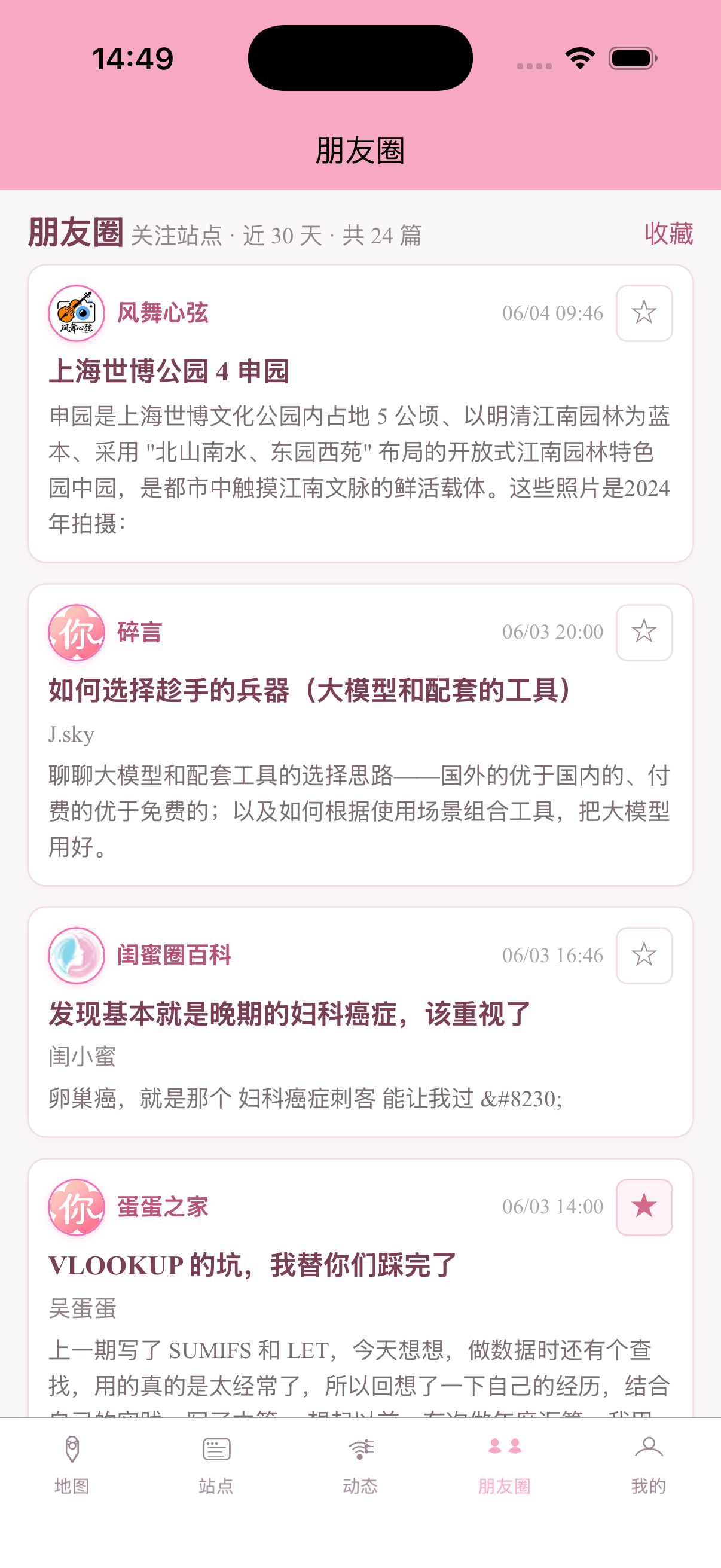
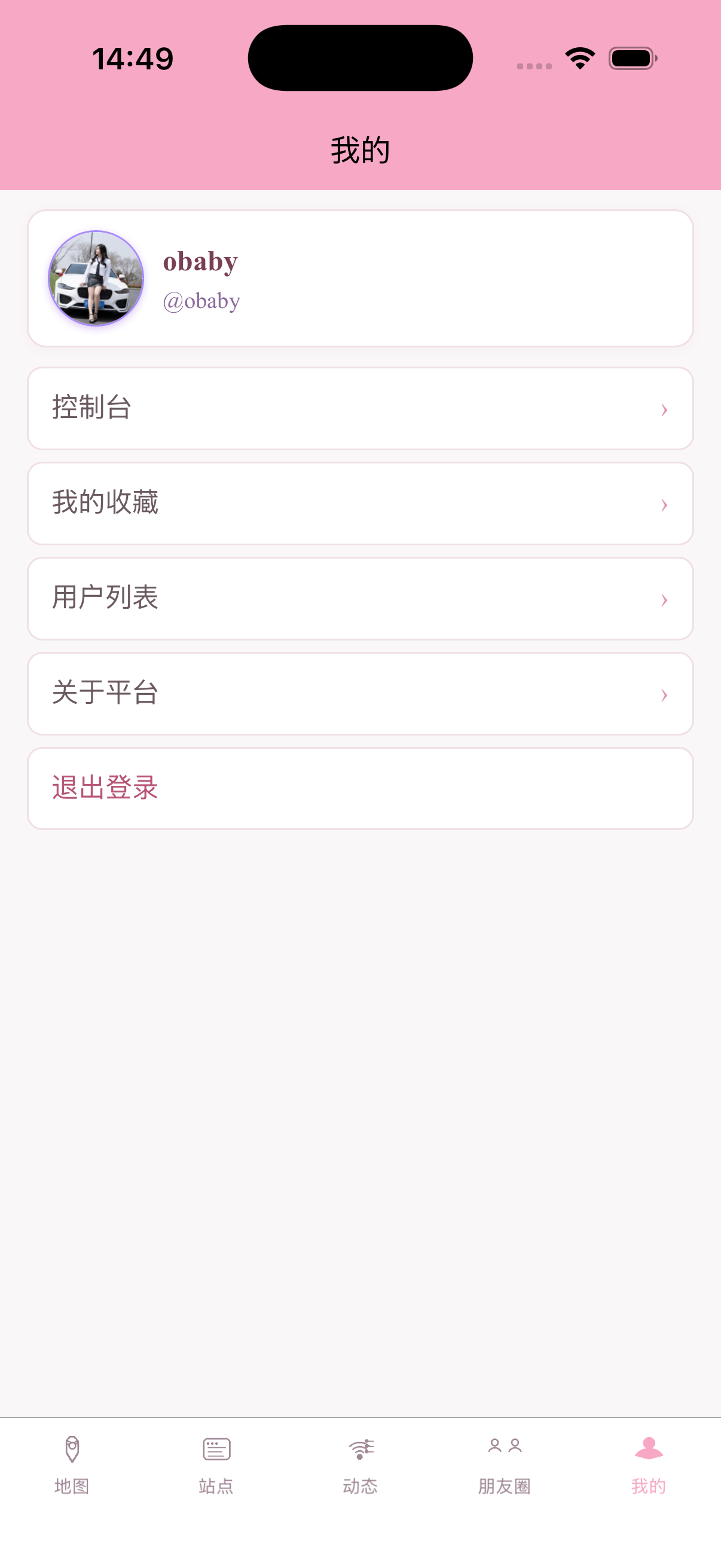
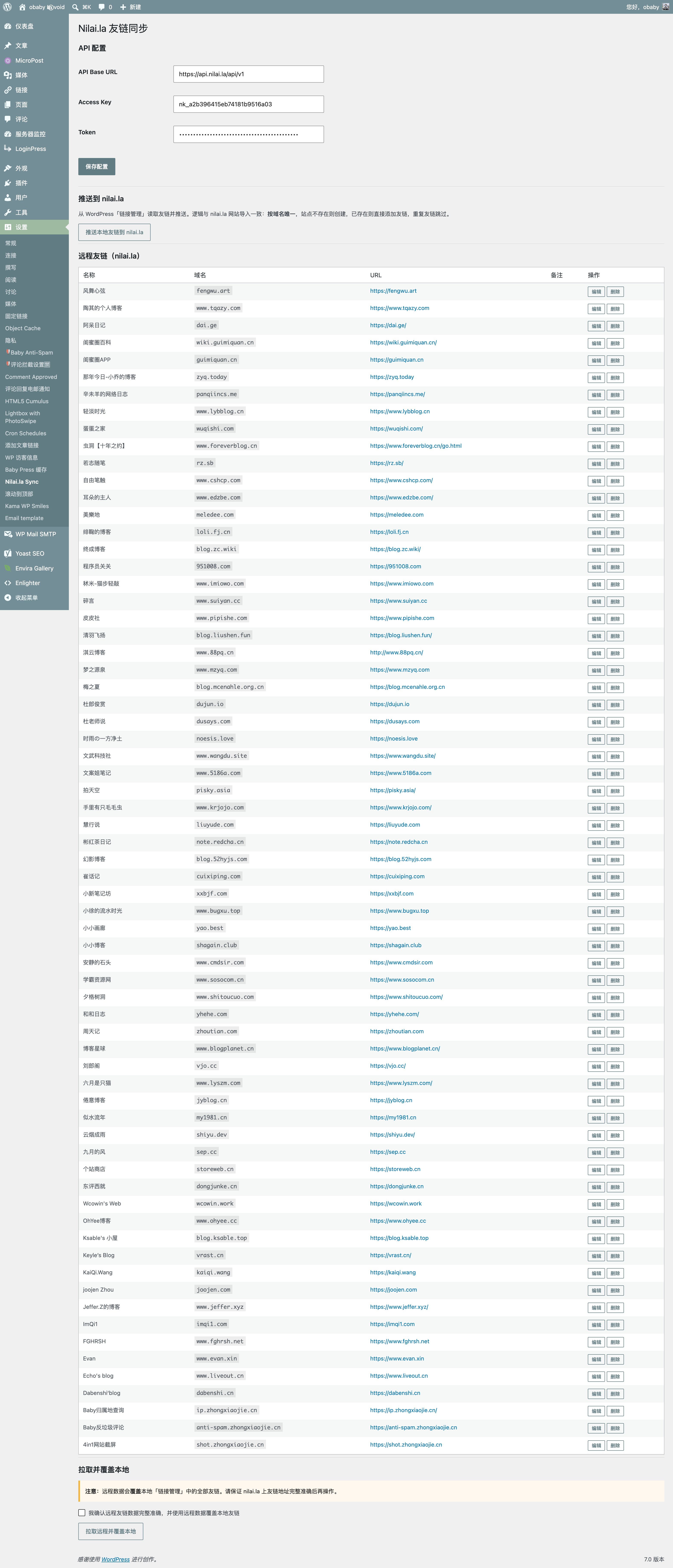
当然,除此之外还开发了几个常用博客的插件,包括wp、tp、halo以及api接口文档,需要的可以自行开发。
ios目前没有上架appstore,提供ipa包,如果安装可以使用sideloadly 自签名安装:
工具下载地址:https://iexmo.com/sideloadly/#mac
IPA下载地址:__UNI__8813F79__20260605093322.ipa
APK下载地址:https://zhongxiaojie.cn/wp-content/uploads/2026/06/nilaila_1_0_1.apk
APK下载二维码:

apk下载2: https://www.pgyer.com/nilaila-android

网站地址: https://nilai.la/feed
插件下载:
wp:wordpress
tp:typecho
halo:nilaila-friend-link-sync-1.0.0.jar
api接口及文档:docs
邀请码:
邀请码 状态 使用者 备注 创建时间 操作 INV-DHXP-HBYS-5B7X 已使用 INV-AA19-BTMY-D1ZZ 已使用 INV-IF3U-5H8A-4Q8H 已使用 INV-LTHS-ZRD3-W30Y 已使用 INV-8XD0-FT1T-96OT 已使用 INV-FDCN-78NA-L4VT 已使用 INV-NX9Q-7ORC-RCA7 可用 INV-HD5O-18AL-YVX3 已使用 INV-0YS5-SGIJ-CSLE 已使用 INV-RT5D-T7UJ-1DTE 可用 INV-PMKU-BS8Y-I5HM 已使用 INV-W8XY-I2H7-UOUH 已使用 INV-IF6E-NFUT-RGTN 已使用 INV-7IFG-7RQU-WN9I 已使用 INV-K8QC-M81M-55J1 已使用 INV-109X-8UFG-9TH2 已使用 INV-M2ZM-O8AZ-QSGI 已使用 INV-6EK0-3GBF-AVXO 已使用 INV-8XI7-HWAS-T761 已使用 INV-1FGJ-S5WW-NWBN 已使用 INV-PD8N-1RGT-MUKP 可用 INV-UY5Q-7ALX-G8P0 可用 INV-T90M-W48Y-MN1Q 已使用 INV-LRSS-BZGW-KZUM 可用 INV-XIH4-EM3W-1GSR 已使用 INV-9Q6H-ADH7-ZDYG 可用 INV-EDKY-M9U3-24GJ 可用